使用NavMesh执行寻路
在前面的章节中我们详细的介绍了Recast从接受一个Obj格式描述的场景到最终生成相应的寻路网格NavMesh数据的,接下来我们将介绍如何加载序列化到文件的NavMesh数据并使用这份NavMesh数据来支持各种寻路请求。
NavMesh的装载
在前面一章的最后一节中我们展示了RecastDemo将dtNavMesh数据序列化到文件的基本流程:先写入NavMeshSetHeader然后再遍历内部存储的所有dtMeshTile按字节输出到文件。对应的加载过程则是上面的逆过程:先读取NavMeshSetHeader然后再一个一个的读取dtMeshTile并调用addTile添加到dtNavMesh中:
dtNavMesh* Sample::loadAll(const char* path)
{
FILE* fp = fopen(path, "rb");
if (!fp) return 0;
// Read header.
NavMeshSetHeader header;
size_t readLen = fread(&header, sizeof(NavMeshSetHeader), 1, fp);
// 这里省略一些数据有效检查
dtNavMesh* mesh = dtAllocNavMesh();
if (!mesh)
{
fclose(fp);
return 0;
}
dtStatus status = mesh->init(&header.params);
if (dtStatusFailed(status))
{
fclose(fp);
return 0;
}
// Read tiles.
for (int i = 0; i < header.numTiles; ++i)
{
NavMeshTileHeader tileHeader;
readLen = fread(&tileHeader, sizeof(tileHeader), 1, fp);
if (readLen != 1)
{
fclose(fp);
return 0;
}
if (!tileHeader.tileRef || !tileHeader.dataSize)
break;
// 读取一份tile数据
unsigned char* data = (unsigned char*)dtAlloc(tileHeader.dataSize, DT_ALLOC_PERM);
if (!data) break;
memset(data, 0, tileHeader.dataSize);
readLen = fread(data, tileHeader.dataSize, 1, fp);
if (readLen != 1)
{
dtFree(data);
fclose(fp);
return 0;
}
// 将这份tile数据加入到dtNavMesh中
mesh->addTile(data, tileHeader.dataSize, DT_TILE_FREE_DATA, tileHeader.tileRef, 0);
}
fclose(fp);
return mesh;
}
对于每个dtMeshTile,其头部元数据字段都会存储其在场景中的位置信息(x,y,layer):
int x; ///< The x-position of the tile within the dtNavMesh tile grid. (x, y, layer)
int y; ///< The y-position of the tile within the dtNavMesh tile grid. (x, y, layer)
int layer; ///< The layer of the tile within the dtNavMesh tile grid. (x, y, layer)
这里的layer字段代表当前Tile是对应的(x,y)的第几层Tile,不过这个字段只有在开启了dtTileCache的时候有作用,其他时候都设置为0。dtNavMesh内使用了一个自己实现的简单版本HashMap来存储所有的dtMeshTile,这里用来查询的key就是(x,y,layer)三元组:
// 一个非常简单且稳定的hash函数
inline int computeTileHash(int x, int y, const int mask)
{
const unsigned int h1 = 0x8da6b343; // Large multiplicative constants;
const unsigned int h2 = 0xd8163841; // here arbitrarily chosen primes
unsigned int n = h1 * x + h2 * y;
return (int)(n & mask);
}
const dtMeshTile* dtNavMesh::getTileAt(const int x, const int y, const int layer) const
{
// 这里只使用(x,y)来计算hash
int h = computeTileHash(x,y,m_tileLutMask);
dtMeshTile* tile = m_posLookup[h]; // m_posLookup是一个数组,数组里存储的都是dtMeshTile组成的链表
while (tile) // 遍历链表查询 (x,y,layer)三元组对应的元素
{
if (tile->header &&
tile->header->x == x &&
tile->header->y == y &&
tile->header->layer == layer)
{
return tile;
}
tile = tile->next;
}
return 0;
}
然后所有的dtMeshTile数据都是在dtNavMesh::init初始化的时候根据参数里传递的最大Tile数量预先分配的:
// 根据传入的m_maxTiles来预先分配所有的tile数据
m_tiles = (dtMeshTile*)dtAlloc(sizeof(dtMeshTile)*m_maxTiles, DT_ALLOC_PERM);
if (!m_tiles)
return DT_FAILURE | DT_OUT_OF_MEMORY;
// 创建hashmap对应的数组
m_posLookup = (dtMeshTile**)dtAlloc(sizeof(dtMeshTile*)*m_tileLutSize, DT_ALLOC_PERM);
if (!m_posLookup)
return DT_FAILURE | DT_OUT_OF_MEMORY;
memset(m_tiles, 0, sizeof(dtMeshTile)*m_maxTiles);
memset(m_posLookup, 0, sizeof(dtMeshTile*)*m_tileLutSize);
m_nextFree = 0; // 使用m_nextFree构造一个空闲tile的链表
for (int i = m_maxTiles-1; i >= 0; --i)
{
m_tiles[i].salt = 1;
m_tiles[i].next = m_nextFree;
m_nextFree = &m_tiles[i];
}
对于每个有效的dtMeshTile,其内存地址一定在m_tiles数组之中,因此可以用一个偏移量去获取数据指针,没有必要每次都用getTileAt(x,y,layer)去执行查询。不过由于dtNavMesh支持对指定dtMeshTile做运行时加载和卸载的操作,所以为了区分dtMeshTile的数据版本,在dtMeshTile内部添加了一个salt字段来代表数据版本号。此时查询获取一个指定的dtMeshTile的指针可以通过(salt, tile_id)这两个字段进行查询,这两个字段拼接成为一个uint64就叫做dtTileRef。不过实际上真正使用的并不是由这个二元组组成的dtTileRef, 而是由(salt, tile_id, poly_id)这个三元组组成的dtPolyRef:
static const unsigned int DT_SALT_BITS = 16;
static const unsigned int DT_TILE_BITS = 28; // 最多支持1 <<28个tile
static const unsigned int DT_POLY_BITS = 20; // 单tile内最多支持 1<<20 个poly
typedef uint64_t dtPolyRef;
typedef uint64_t dtTileRef;
inline dtPolyRef encodePolyId(unsigned int salt, unsigned int it, unsigned int ip) const
{
return ((dtPolyRef)salt << (DT_POLY_BITS+DT_TILE_BITS)) | ((dtPolyRef)it << DT_POLY_BITS) | (dtPolyRef)ip;
}
inline unsigned int decodePolyIdSalt(dtPolyRef ref) const
{
const dtPolyRef saltMask = ((dtPolyRef)1<<DT_SALT_BITS)-1;
return (unsigned int)((ref >> (DT_POLY_BITS+DT_TILE_BITS)) & saltMask);
}
inline unsigned int decodePolyIdTile(dtPolyRef ref) const
{
const dtPolyRef tileMask = ((dtPolyRef)1<<DT_TILE_BITS)-1;
return (unsigned int)((ref >> DT_POLY_BITS) & tileMask);
}
dtTileRef dtNavMesh::getTileRef(const dtMeshTile* tile) const
{
if (!tile) return 0;
const unsigned int it = (unsigned int)(tile - m_tiles);
return (dtTileRef)encodePolyId(tile->salt, it, 0);
}
const dtMeshTile* dtNavMesh::getTileByRef(dtTileRef ref) const
{
if (!ref)
return 0;
unsigned int tileIndex = decodePolyIdTile((dtPolyRef)ref);
unsigned int tileSalt = decodePolyIdSalt((dtPolyRef)ref);
if ((int)tileIndex >= m_maxTiles)
return 0;
const dtMeshTile* tile = &m_tiles[tileIndex];
if (tile->salt != tileSalt)
return 0;
return tile;
}
有了dtPolyRef这个handle,就可以比较快速且安全的获取一个dtMeshTile,以规避裸指针访问dtMeshTile数据时的版本不匹配问题。
了解了dtMeshTile的分配之后,我们才能继续讲解addTile的内部过程, 首先寻找一个空闲的dtMeshTile来装载传入的数据:
// data开头的部分是dtMeshHeader 检查对应的版本号是否匹配
dtMeshHeader* header = (dtMeshHeader*)data;
if (header->magic != DT_NAVMESH_MAGIC)
return DT_FAILURE | DT_WRONG_MAGIC;
if (header->version != DT_NAVMESH_VERSION)
return DT_FAILURE | DT_WRONG_VERSION;
// Make sure the location is free.
if (getTileAt(header->x, header->y, header->layer)) // 如果已经有相同位置的tile被添加了 返回错误
return DT_FAILURE | DT_ALREADY_OCCUPIED;
// Allocate a tile.
dtMeshTile* tile = 0;
if (!lastRef) // lastRef代表指定dtTileRef 这个选项一般不使用 所以这里的逻辑忽略else部分
{
if (m_nextFree)
{
tile = m_nextFree;
m_nextFree = tile->next;
tile->next = 0;
}
}
// Make sure we could allocate a tile.
if (!tile)
return DT_FAILURE | DT_OUT_OF_MEMORY;
// 更新hash表对应表项的链表
int h = computeTileHash(header->x, header->y, m_tileLutMask);
tile->next = m_posLookup[h];
m_posLookup[h] = tile;
找到一个合适的dtMeshTile之后,按照保存时的各项数据的偏移量来初始化dtMeshTile的各个成员变量指针,这里甚至不需要执行内存的复制操作,直接进行指针计算即可:
const int headerSize = dtAlign4(sizeof(dtMeshHeader));
const int vertsSize = dtAlign4(sizeof(float)*3*header->vertCount);
const int polysSize = dtAlign4(sizeof(dtPoly)*header->polyCount);
const int linksSize = dtAlign4(sizeof(dtLink)*(header->maxLinkCount));
const int detailMeshesSize = dtAlign4(sizeof(dtPolyDetail)*header->detailMeshCount);
const int detailVertsSize = dtAlign4(sizeof(float)*3*header->detailVertCount);
const int detailTrisSize = dtAlign4(sizeof(unsigned char)*4*header->detailTriCount);
const int bvtreeSize = dtAlign4(sizeof(dtBVNode)*header->bvNodeCount);
const int offMeshLinksSize = dtAlign4(sizeof(dtOffMeshConnection)*header->offMeshConCount);
unsigned char* d = data + headerSize;
tile->verts = dtGetThenAdvanceBufferPointer<float>(d, vertsSize);
tile->polys = dtGetThenAdvanceBufferPointer<dtPoly>(d, polysSize);
tile->links = dtGetThenAdvanceBufferPointer<dtLink>(d, linksSize);
tile->detailMeshes = dtGetThenAdvanceBufferPointer<dtPolyDetail>(d, detailMeshesSize);
tile->detailVerts = dtGetThenAdvanceBufferPointer<float>(d, detailVertsSize);
tile->detailTris = dtGetThenAdvanceBufferPointer<unsigned char>(d, detailTrisSize);
tile->bvTree = dtGetThenAdvanceBufferPointer<dtBVNode>(d, bvtreeSize);
tile->offMeshCons = dtGetThenAdvanceBufferPointer<dtOffMeshConnection>(d, offMeshLinksSize);
// 初始化空闲links链表
tile->linksFreeList = 0;
tile->links[header->maxLinkCount-1].next = DT_NULL_LINK;
for (int i = 0; i < header->maxLinkCount-1; ++i)
tile->links[i].next = i+1;
// Init tile.
tile->header = header;
tile->data = data;
tile->dataSize = dataSize;
tile->flags = flags;
接下来才是addTile的核心内容,构建从当前dtMeshTile内的任一poly出发的dtLink。首先构造的是起点poly和终点poly都在当前dtMeshTile内的dtLink。由于dtPoly结构体内已经用neis字段存储了当前的邻接Poly,所以这个部分的构建流程就比较简单,对应的函数调用为connectIntLinks(tile):
void dtNavMesh::connectIntLinks(dtMeshTile* tile)
{
if (!tile) return;
dtPolyRef base = getPolyRefBase(tile); // 以(salt, tile_id, 0) 组装成为一个uint64
for (int i = 0; i < tile->header->polyCount; ++i)
{
dtPoly* poly = &tile->polys[i];
poly->firstLink = DT_NULL_LINK;
if (poly->getType() == DT_POLYTYPE_OFFMESH_CONNECTION) //忽略非mesh poly
continue;
// 逆向遍历节点对应的邻居 这样links链表对应的边索引就是从低到高排序的
for (int j = poly->vertCount-1; j >= 0; --j)
{
// 跳过tile 边界边
if (poly->neis[j] == 0 || (poly->neis[j] & DT_EXT_LINK)) continue;
// 从tile的空闲dtlink链表摘取头部
unsigned int idx = allocLink(tile);
if (idx != DT_NULL_LINK)
{
dtLink* link = &tile->links[idx];
link->ref = base | (dtPolyRef)(poly->neis[j]-1);
link->edge = (unsigned char)j; // 存储边索引
link->side = 0xff; // 这里的side为oxff代表是同一tile内的边
link->bmin = link->bmax = 0;
// 维护当前poly对应的links链表
link->next = poly->firstLink;
poly->firstLink = idx;
}
}
}
}
搞定了Tile内部正常多边形直接连接之后,开始处理在当前Tile内的OffMeshPoly。这里会构造两个dtLink,一条dtLink负责从当前OffMeshPoly连接到最近的正常地面Poly也叫做landpoly,另外一个dtLink负责从landpoly连接到OffMeshPoly:
void dtNavMesh::baseOffMeshLinks(dtMeshTile* tile)
{
if (!tile) return;
dtPolyRef base = getPolyRefBase(tile);
// Base off-mesh connection start points.
for (int i = 0; i < tile->header->offMeshConCount; ++i)
{
dtOffMeshConnection* con = &tile->offMeshCons[i];
dtPoly* poly = &tile->polys[con->poly]; // 当前的OffmeshPoly
const float halfExtents[3] = { con->rad, tile->header->walkableClimb, con->rad };
// 查找当前Tile内当前OffMeshConnection起点最近的Poly
const float* p = &con->pos[0]; // First vertex
float nearestPt[3];
dtPolyRef ref = findNearestPolyInTile(tile, p, halfExtents, nearestPt);
if (!ref) continue;
// 如果距离太远则认为不连通 跳过
if (dtSqr(nearestPt[0]-p[0])+dtSqr(nearestPt[2]-p[2]) > dtSqr(con->rad))
continue;
// 存储poly上离con的起点最近的点
float* v = &tile->verts[poly->verts[0]*3];
dtVcopy(v, nearestPt);
// 构造从当前的OffmeshPoly指向landpoly的dtlink
unsigned int idx = allocLink(tile);
if (idx != DT_NULL_LINK)
{
dtLink* link = &tile->links[idx];
link->ref = ref;
link->edge = (unsigned char)0;
link->side = 0xff;// 当前tile内部边
link->bmin = link->bmax = 0;
// 维持好poly对应link链表
link->next = poly->firstLink;
poly->firstLink = idx;
}
// 构造从landpoly指向offmeshpoly的dtlink
unsigned int tidx = allocLink(tile);
if (tidx != DT_NULL_LINK)
{
const unsigned short landPolyIdx = (unsigned short)decodePolyIdPoly(ref);
dtPoly* landPoly = &tile->polys[landPolyIdx];
dtLink* link = &tile->links[tidx];
link->ref = base | (dtPolyRef)(con->poly);
link->edge = 0xff; // 这里的0xff代表是到offmeshpoly的边
link->side = 0xff; // 当前tile内部边
link->bmin = link->bmax = 0;
// 维持好poly对应link链表
link->next = landPoly->firstLink;
landPoly->firstLink = tidx;
}
}
}
然后对于每一条OffMeshCon,构造对应的dtLink,如果OffMeshCon是单向连通的,则构造一条,如果是双向连通的,则构造两条:
// 这个函数负责构造两个tile之间的所有OffMeshCon对应的Link
// OffMeshCon的起点在target 终点在当前tile side 代表target相对于tile的方向偏移 0xff代表是同一个tile
void dtNavMesh::connectExtOffMeshLinks(dtMeshTile* tile, dtMeshTile* target, int side)
{
if (!tile) return;
const unsigned char oppositeSide = (side == -1) ? 0xff : (unsigned char)dtOppositeTile(side);
for (int i = 0; i < target->header->offMeshConCount; ++i)
{
dtOffMeshConnection* targetCon = &target->offMeshCons[i];
if (targetCon->side != oppositeSide) // 过滤掉不是往当前tile连接的offmeshCon
continue;
dtPoly* targetPoly = &target->polys[targetCon->poly];
// 如果targetPoly在targetTile内没有landpoly与之连接 说明当前offmeshcon没有意义 跳过
if (targetPoly->firstLink == DT_NULL_LINK)
continue;
const float halfExtents[3] = { targetCon->rad, target->header->walkableClimb, targetCon->rad };
// 查找targetCon终点在当前tile对应的landpoly
const float* p = &targetCon->pos[3];
float nearestPt[3];
dtPolyRef ref = findNearestPolyInTile(tile, p, halfExtents, nearestPt);
if (!ref)
continue;
// findNearestPoly may return too optimistic results, further check to make sure.
if (dtSqr(nearestPt[0]-p[0])+dtSqr(nearestPt[2]-p[2]) > dtSqr(targetCon->rad))
continue;
// 找到了有效的landpoly和投影点 复制到offmeshpoly的第二个节点
float* v = &target->verts[targetPoly->verts[1]*3];
dtVcopy(v, nearestPt);
// 构造OffmeshPoly到landpoly的dtlink
unsigned int idx = allocLink(target);
if (idx != DT_NULL_LINK)
{
dtLink* link = &target->links[idx];
link->ref = ref;
link->edge = (unsigned char)1;
link->side = oppositeSide;
link->bmin = link->bmax = 0;
// Add to linked list.
link->next = targetPoly->firstLink;
targetPoly->firstLink = idx;
}
// 如果当前连接是双向的 则也构造一条从landpoly指向当前offmeshpoly的dtlink
if (targetCon->flags & DT_OFFMESH_CON_BIDIR)
{
unsigned int tidx = allocLink(tile);
if (tidx != DT_NULL_LINK)
{
const unsigned short landPolyIdx = (unsigned short)decodePolyIdPoly(ref);
dtPoly* landPoly = &tile->polys[landPolyIdx];
dtLink* link = &tile->links[tidx];
link->ref = getPolyRefBase(target) | (dtPolyRef)(targetCon->poly);
link->edge = 0xff;
link->side = (unsigned char)(side == -1 ? 0xff : side);
link->bmin = link->bmax = 0;
// Add to linked list.
link->next = landPoly->firstLink;
landPoly->firstLink = tidx;
}
}
}
}
注意这个函数可以指定两个dtMeshTile做参数,因此这个函数可以构造以当前Tile为中心的九宫格内所有Tile到当前Tile的OffMeshCon对应的dtLink,所以如果外部如果设置了两个OffMeshLink的距离太远超过九宫格范围的话,NavMesh中不会生成对应的dtLink:
connectExtOffMeshLinks(tile, tile, -1); // 构造起点和终点都在当前tile内的所有offmeshcon对应的dtlink
// Create connections with neighbour tiles.
static const int MAX_NEIS = 32;
dtMeshTile* neis[MAX_NEIS];
int nneis;
// Connect with layers in current tile.
nneis = getTilesAt(header->x, header->y, neis, MAX_NEIS); // 查询(x,y)上的多层tile
for (int j = 0; j < nneis; ++j)
{
if (neis[j] == tile)
continue;
connectExtLinks(tile, neis[j], -1);// 构造两者的边界连通dtlink
connectExtLinks(neis[j], tile, -1);
connectExtOffMeshLinks(tile, neis[j], -1); // 构造两者的offmeshCon对应的dtlink
connectExtOffMeshLinks(neis[j], tile, -1);
}
// 构造八个方向邻居的所有边界连通边与offmeshCon对应的Dtlink
for (int i = 0; i < 8; ++i)
{
// 获取当前i方向的所有layer的邻居tile
nneis = getNeighbourTilesAt(header->x, header->y, i, neis, MAX_NEIS);
for (int j = 0; j < nneis; ++j)
{
connectExtLinks(tile, neis[j], i);// 构造两者的边界连通dtlink
connectExtLinks(neis[j], tile, dtOppositeTile(i));
connectExtOffMeshLinks(tile, neis[j], i);// 构造两者的offmeshCon对应的dtlink
connectExtOffMeshLinks(neis[j], tile, dtOppositeTile(i));
}
}
上面的代码中除了调用connectExtOffMeshLinks来构造非地表连接形成的dtLink之外,还使用了connectExtLinks来构造相邻(包括y轴相邻和xz平面九宫格相邻)dtMeshTile之间的边界portal连接。其实构建portal边只会涉及到四个轴方向的邻居,其他方向都不会构造portal边,所以下面的代码里只判断了这四个轴方向:
// 构造从tile出发连接到target的边界边
void dtNavMesh::connectExtLinks(dtMeshTile* tile, dtMeshTile* target, int side)
{
if (!tile) return;
// Connect border links.
for (int i = 0; i < tile->header->polyCount; ++i)
{
dtPoly* poly = &tile->polys[i];
const int nv = poly->vertCount;
for (int j = 0; j < nv; ++j)
{
// 遍历每一条边 过滤掉不连通到target 的
if ((poly->neis[j] & DT_EXT_LINK) == 0)
continue;
const int dir = (int)(poly->neis[j] & 0xff);
if (side != -1 && dir != side)
continue;
// 当前边是一条边界边
const float* va = &tile->verts[poly->verts[j]*3];
const float* vb = &tile->verts[poly->verts[(j+1) % nv]*3];
dtPolyRef nei[4]; // 邻接poly的handle
float neia[4*2]; // 邻接的线段在当前线段的位置百分比
// 找到target里与当前边界边相邻的一些poly
int nnei = findConnectingPolys(va,vb, target, dtOppositeTile(dir), nei,neia,4);
for (int k = 0; k < nnei; ++k) // 对于每个邻接的poly 构造一个dtlink
{
unsigned int idx = allocLink(tile);
if (idx != DT_NULL_LINK)
{
dtLink* link = &tile->links[idx];
link->ref = nei[k];
link->edge = (unsigned char)j;
link->side = (unsigned char)dir; //邻居tile的方向
// 填充到当前poly的link链表中
link->next = poly->firstLink;
poly->firstLink = idx;
// 对于轴向的四个方向邻居tile 计算对应的aabb box
if (dir == 0 || dir == 4)
{
float tmin = (neia[k*2+0]-va[2]) / (vb[2]-va[2]);
float tmax = (neia[k*2+1]-va[2]) / (vb[2]-va[2]);
if (tmin > tmax)
dtSwap(tmin,tmax);
link->bmin = (unsigned char)std::round(dtClamp<float>(tmin, 0.0f, 1.0f)*255.0f);
link->bmax = (unsigned char)std::round(dtClamp<float>(tmax, 0.0f, 1.0f)*255.0f);
}
else if (dir == 2 || dir == 6)
{
float tmin = (neia[k*2+0]-va[0]) / (vb[0]-va[0]);
float tmax = (neia[k*2+1]-va[0]) / (vb[0]-va[0]);
if (tmin > tmax)
dtSwap(tmin,tmax);
link->bmin = (unsigned char)std::round(dtClamp<float>(tmin, 0.0f, 1.0f)*255.0f);
link->bmax = (unsigned char)std::round(dtClamp<float>(tmax, 0.0f, 1.0f)*255.0f);
}
}
}
}
}
}
上面函数还是比较浅显易懂的,核心的逻辑都在findConnectingPolys函数内了,这个函数负责计算指定tile内与某条线段靠近的Poly,注意这里从side与邻居tile的偏移量对应如下:
int dtNavMesh::getNeighbourTilesAt(const int x, const int y, const int side, dtMeshTile** tiles, const int maxTiles) const
{
int nx = x, ny = y;
switch (side)
{
case 0: nx++; break;
case 1: nx++; ny++; break;
case 2: ny++; break;
case 3: nx--; ny++; break;
case 4: nx--; break;
case 5: nx--; ny--; break;
case 6: ny--; break;
case 7: nx++; ny--; break;
};
return getTilesAt(nx, ny, tiles, maxTiles);
}
// 计算side的反方向
inline int dtOppositeTile(int side) { return (side+4) & 0x7; }
从上面的代码可以看出0,4对应的是X轴方向的邻居,2,6对应的是Z轴方向的邻居,其他奇数方向对应的是对角线方向的邻居。然后side从0增大到7就是一个顺时针查找所有方向的邻居的过程。了解了side的定义之后,我们才能更好的了解findConnectingPolys:
// 计算 va 点在 side 方向的轴上的坐标点
// 如果 side 是在 X 轴方向上寻找邻居,则返回的是 x 轴坐标
// 如果 side 是在 Z 轴方向上寻找邻居,则返回的是 z 轴坐标
// 如果不是轴方向 则返回0
static float getSlabCoord(const float* va, const int side)
{
if (side == 0 || side == 4)
return va[0];
else if (side == 2 || side == 6)
return va[2];
return 0;
}
int dtNavMesh::findConnectingPolys(const float* va, const float* vb,
const dtMeshTile* tile, int side,
dtPolyRef* con, float* conarea, int maxcon) const
{
if (!tile) return 0;
// 这两个字段只有在四个轴方向时才起作用 用来加速非相交判断的
// 计算除掉当前side对应的轴方向的AABB box 这里的[1]对应的永远是高度轴 即Y轴
float amin[2], amax[2];
calcSlabEndPoints(va, vb, amin, amax, side);
// 计算 va 点在 side 方向的轴上的坐标点
const float apos = getSlabCoord(va, side);
// Remove links pointing to 'side' and compact the links array.
float bmin[2], bmax[2];
unsigned short m = DT_EXT_LINK | (unsigned short)side;
int n = 0;
dtPolyRef base = getPolyRefBase(tile);
for (int i = 0; i < tile->header->polyCount; ++i)
{
dtPoly* poly = &tile->polys[i];
const int nv = poly->vertCount;
for (int j = 0; j < nv; ++j)
{
// 跳过不与当前来源tile方向连通的边
if (poly->neis[j] != m) continue;
const float* vc = &tile->verts[poly->verts[j]*3];
const float* vd = &tile->verts[poly->verts[(j+1) % nv]*3];
// 计算vc在当前轴方向的投影值
const float bpos = getSlabCoord(vc, side);
// 对于非轴方向 两者都是0 所以会执行后续代码
// 对于轴方向 会利用两者差值进行过滤
if (dtAbs(apos-bpos) > 0.01f)
continue;
// 计算除掉当前side对应的轴方向的AABB box 这里的[1]对应的永远是高度轴 即Y轴
calcSlabEndPoints(vc,vd, bmin,bmax, side);
// 这里会计算两个aabb box之间是否相交
// 这里还考虑了爬升高度
if (!overlapSlabs(amin,amax, bmin,bmax, 0.01f, tile->header->walkableClimb)) continue;
// Add return value.
if (n < maxcon)
{
// 获取投影相交区域的非side对应轴坐标的最大最小值
conarea[n*2+0] = dtMax(amin[0], bmin[0]);
conarea[n*2+1] = dtMin(amax[0], bmax[0]);
con[n] = base | (dtPolyRef)i;
n++;
}
break;
}
}
return n;
}
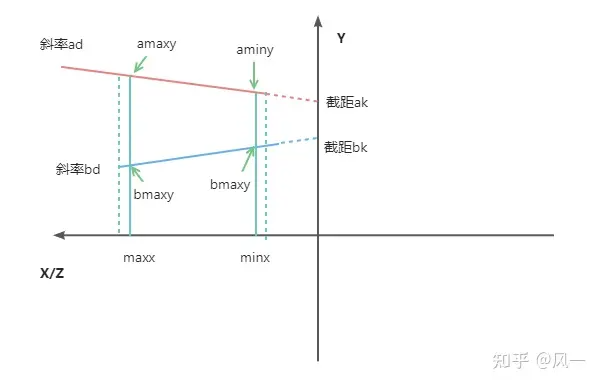
这里的overlapSlabs负责计算两条线段对应的AABB矩形间隔是否在爬升范围walkableClimb之内,实现的有点复杂,我们需要对照源代码讲解一下:
inline bool overlapSlabs(const float* amin, const float* amax,
const float* bmin, const float* bmax,
const float px, const float py)
{
const float minx = dtMax(amin[0]+px,bmin[0]+px);
const float maxx = dtMin(amax[0]-px,bmax[0]-px);
// 两个 portal edge 必定不会有重叠的情况
// 其中收缩了 px 的距离,主要是防止 a 的 min 和 b 的 max 恰好重合的情况
// 对于两个 portal edge 仅仅只是端点相邻的情况是不构成连接
// 也可以理解成只有两个 portal edge 需要重叠一部分,才能保证这两个是实实在在的相邻
if (minx > maxx)
return false;
// 现在主要看垂直切面上的情况,只有两种情况,一种是 XY 平面,一种是 ZY 平面
// 写法基本一致,所以前面把 x 或 z 的坐标设置到了 [0] 里,y 则放到 [1] 里
// ad 代表线段a的斜率
const float ad = (amax[1]-amin[1]) / (amax[0]-amin[0]);
// 这里使用平面坐标系上直线的斜截式公式求在 Y 轴上的截距
// 已知直线表达式 y = kx + b 带入点 amin 得到 amin[1] = k * amin[0] + b
// 由于斜率 k 已知,即可得到截距 b = amin[1] - ad * amin[0]
const float ak = amin[1] - ad*amin[0];
// 同理计算 b 的截距
const float bd = (bmax[1]-bmin[1]) / (bmax[0]-bmin[0]);
const float bk = bmin[1] - bd*bmin[0];
// 将上一步的 minx 点带入到 a 的直线中得到 aminy
const float aminy = ad*minx + ak;
// 将上一步的 maxx 点带入到 a 的直线中得到 amaxy
const float amaxy = ad*maxx + ak;
// 同理带入 b 的直线中得到 bminy bmaxy
const float bminy = bd*minx + bk;
const float bmaxy = bd*maxx + bk;
// 两条线段投影到Y轴之后 计算上下端点的差值
const float dmin = bminy - aminy;
const float dmax = bmaxy - amaxy;
// 线段发生交叉的情况 说明当前aabb肯定相交
if (dmin*dmax < 0)
return true;
// 没有发生交叉,则就看看距离
const float thr = dtSqr(py*2);
if (dmin*dmin <= thr || dmax*dmax <= thr)
return true;
return false;
}
因为portal边从XY或ZY切面上看可能是斜着的,所以还需要判断高度范围的重叠情况。如果 dmin*dmax小于0,说明a线段和b线段重叠部分必有一个交点。否则要么a线段完全在b线段上或者下,此时直接比较下两端距离和agentClimb的大小即可。
NavMesh的路径查询
dtNavMesh类提供了一些简单的接口来支撑路径查询:
/// 查询某个tile中特定aabb内的poly
int queryPolygonsInTile(const dtMeshTile* tile, const float* qmin, const float* qmax,
dtPolyRef* polys, const int maxPolys) const;
/// 查询某个tile中与特定点最近的poly nearestPt里存储这个poly里距离center最近的点坐标
dtPolyRef findNearestPolyInTile(const dtMeshTile* tile, const float* center,
const float* halfExtents, float* nearestPt) const;
// 计算点投影到某个poly的高度 如果点在poly下面则返回false 在上面返回true 高度存储在height中
bool getPolyHeight(const dtMeshTile* tile, const dtPoly* poly, const float* pos, float* height) const;
/// 计算某个poly上离指定点最近的点
void closestPointOnPoly(dtPolyRef ref, const float* pos, float* closest, bool* posOverPoly) const;
路径查询首先需要知道一个点对应的Poly是哪个,这个功能就对应了上面的findNearestPolyInTile接口。findNearestPolyInTile内部使用queryPolygonsInTile来获取查询范围内的所有Poly,然后再对这些Poly调用closestPointOnPoly获取一个多边形距离目标点最近的点及距离,获取其中距离最短的作为目标Poly进行返回。如果dtNavMesh生成的时候没有配置生成BVH数据,则queryPolygonsInTile与findNearestPolyInTile的实现都只能通过遍历当前Tile内所有的Poly来执行区间相交过滤,时间复杂度就是Poly数量的线性。如果配置了BVH数据,则可以使用BVH来加速区间查询,这部分的代码与之前在RecastNavMesh生成的时候介绍的BVH查询基本一致。
closestPointOnPoly内部会调用getPolyHeight来计算目标点在当前Poly上的投影高度,这个查询会利用当前Poly对应的细节三角形数据来计算最贴近表面的高度:
bool dtNavMesh::getPolyHeight(const dtMeshTile* tile, const dtPoly* poly, const float* pos, float* height) const
{
// offmesh poly不参与这个计算
if (poly->getType() == DT_POLYTYPE_OFFMESH_CONNECTION)
return false;
const unsigned int ip = (unsigned int)(poly - tile->polys);
const dtPolyDetail* pd = &tile->detailMeshes[ip];
float verts[DT_VERTS_PER_POLYGON*3];
const int nv = poly->vertCount;
for (int i = 0; i < nv; ++i)
dtVcopy(&verts[i*3], &tile->verts[poly->verts[i]*3]);
// 使用凸包算法判断点在XZ平面的投影在这个多边形的XZ投影内
if (!dtPointInPolygon(pos, verts, nv))
return false;
if (!height)
return true;
// 遍历当前poly对应的细节三角形 计算投影点
for (int j = 0; j < pd->triCount; ++j)
{
const unsigned char* t = &tile->detailTris[(pd->triBase+j)*4];
const float* v[3];
for (int k = 0; k < 3; ++k)
{
if (t[k] < poly->vertCount)
v[k] = &tile->verts[poly->verts[t[k]]*3];
else
v[k] = &tile->detailVerts[(pd->vertBase+(t[k]-poly->vertCount))*3];
}
float h;
if (dtClosestHeightPointTriangle(pos, v[0], v[1], v[2], h))
{
*height = h;
return true;
}
}
// 如果不在细节三角形内 则遍历细节三角形的边界边上离目标点最近的点
float closest[3];
closestPointOnDetailEdges<false>(tile, poly, pos, closest);
*height = closest[1];
return true;
}
由于OffMeshPoly的存在,closestPointOnPoly还需要做一些额外判断:
void dtNavMesh::closestPointOnPoly(dtPolyRef ref, const float* pos, float* closest, bool* posOverPoly) const
{
const dtMeshTile* tile = 0;
const dtPoly* poly = 0;
getTileAndPolyByRefUnsafe(ref, &tile, &poly);
dtVcopy(closest, pos);
if (getPolyHeight(tile, poly, pos, &closest[1]))
{
// 如果点的投影在当前多边形内 直接计算投影点
if (posOverPoly)
*posOverPoly = true;
return;
}
if (posOverPoly)
*posOverPoly = false;
// 如果是offmesh poly 计算两点连线上与当前点最近的点
if (poly->getType() == DT_POLYTYPE_OFFMESH_CONNECTION)
{
const float* v0 = &tile->verts[poly->verts[0]*3];
const float* v1 = &tile->verts[poly->verts[1]*3];
float t;
dtDistancePtSegSqr2D(pos, v0, v1, t);
dtVlerp(closest, v0, v1, t);
return;
}
// 计算当前Poly所有边中距离目标点最近的点
closestPointOnDetailEdges<true>(tile, poly, pos, closest);
}
实际上Detour并不推荐使用者直接使用dtNavMesh提供的这几个接口来做查询,而是提供了一个专用的查询类dtNavMeshQuery。这个类型上提供了最终对外的寻路查询接口,不仅包括了点对应的最近Poly查询,还包括了两点之间的Poly路径查询。此外dtNavMeshQuery还支持了dtQueryFilter来对路径上的不同Area类型的多边形进行查询权重修改:
class dtQueryFilter
{
float m_areaCost[DT_MAX_AREAS]; /// 每种类型的Area在路径查询时的cost
unsigned short m_includeFlags; /// 路径查询时能被使用的多边形的flag
unsigned short m_excludeFlags; /// 路径查询时不能被使用的多边形的flag
public:
dtQueryFilter();
virtual ~dtQueryFilter() { }
// 判断一个poly能否通过当前queryfilter的要求
virtual bool passFilter(const dtPolyRef ref,
const dtMeshTile* tile,
const dtPoly* poly) const;
/// 计算跨poly移动时的cost
virtual float getCost(const float* pa, const float* pb,
const dtPolyRef prevRef, const dtMeshTile* prevTile, const dtPoly* prevPoly,
const dtPolyRef curRef, const dtMeshTile* curTile, const dtPoly* curPoly,
const dtPolyRef nextRef, const dtMeshTile* nextTile, const dtPoly* nextPoly) const;
};
因此dtNavMeshQuery上提供的所有查询接口都需要带上这个QueryFilter:
// 寻找一个点最近的poly
dtStatus findNearestPoly(const float* center, const float* halfExtents,
const dtQueryFilter* filter,
dtPolyRef* nearestRef, float* nearestPt, bool* isOverPoly) const;
// 寻找两个多边形之间的多边形连通路径
dtStatus findPath(dtPolyRef startRef, dtPolyRef endRef,
const float* startPos, const float* endPos,
const dtQueryFilter* filter,
dtPolyRef* path, int* pathCount, const int maxPath) const;
findNearestPoly的实现与dtNavMesh上的findNearestPolyInTile实现基本一致,只是多加了dtQueryFilter的多边形过滤,因此这里不再详细介绍。而findPath则是整个NavMesh系统最重要的接口,其核心逻辑就是利用Poly中存储的邻接关系来执行A*搜索构造连通路径,下面我们来重点分析搜索的实现细节。首先定义了一个dtNode的结构体来描述A*搜索时使用的节点:
enum dtNodeFlags
{
DT_NODE_OPEN = 0x01, // 当前node在A*搜索的OpenList中
DT_NODE_CLOSED = 0x02, // 当前node在A*搜索的ClosedList中
DT_NODE_PARENT_DETACHED = 0x04, // 当前节点的父节点并不是直接边相邻的 而是通过raycast计算出来的
};
static const int DT_NODE_PARENT_BITS = 24;
static const int DT_NODE_STATE_BITS = 2;
struct dtNode
{
float pos[3]; ///< 当前点的坐标
float cost; ///< 前面的节点移动到当前节点的cost
float total; ///< 当前点的综合cost 等于从起点到当前点的cost加上当前点到目标点的启发cost
unsigned int pidx : DT_NODE_PARENT_BITS; ///< 父节点dtNode的在全局dtNode数组中的偏移量
unsigned int state : DT_NODE_STATE_BITS; ///< 一些自定义的额外信息字段
unsigned int flags : 3; ///< 当前node的dtNodeFlags信息
dtPolyRef id; ///< 当前节点所在的polyid
};
A*搜索执行时会构造很多的dtNode,dtNavMeshQuery使用了一个dtNodePool来管理dtNode的分配和查询,内部用一个dtNode数组作为线性的内存分配器,所以dtNode中使用了一个24bit的整数来替代一个完整的dtNode指针。为了支持多边形对应的dtNode的查询,dtNodePool使用了一个C风格的HashMap来处理PolyId到dtNode的查询映射:
class dtNodePool
{
public:
dtNodePool(int maxNodes, int hashSize);
~dtNodePool();
void clear();
// 根据(id,state)来查询对应的dtNode 如果不存在则分配一个对应的dtNode
dtNode* getNode(dtPolyRef id, unsigned char state=0);
// 根据(id,state)来查询对应的dtNode 如果不存在则返回null
dtNode* findNode(dtPolyRef id, unsigned char state);
// 查询一个poly id对应的所有节点
unsigned int findNodes(dtPolyRef id, dtNode** nodes, const int maxNodes);
// 对外提供Node的索引 0是无效索引 有效的索引都是偏移值加上1
inline unsigned int getNodeIdx(const dtNode* node) const
{
if (!node) return 0;
return (unsigned int)(node - m_nodes) + 1;
}
inline dtNode* getNodeAtIdx(unsigned int idx)
{
if (!idx) return 0;
return &m_nodes[idx - 1];
}
private:
// Explicitly disabled copy constructor and copy assignment operator.
dtNodePool(const dtNodePool&);
dtNodePool& operator=(const dtNodePool&);
dtNode* m_nodes;
dtNodeIndex* m_first;
dtNodeIndex* m_next;
const int m_maxNodes;
const int m_hashSize;
int m_nodeCount;
};
了解了dtNode的相关定义之后,我们开始正式的启动A*搜索的流程,首先需要构造初始节点:
dtNode* startNode = m_nodePool->getNode(startRef);
dtVcopy(startNode->pos, startPos);
startNode->pidx = 0;
startNode->cost = 0;
startNode->total = dtVdist(startPos, endPos) * H_SCALE;
startNode->id = startRef;
startNode->flags = DT_NODE_OPEN;
m_openList->push(startNode);
dtNode* lastBestNode = startNode;
float lastBestNodeCost = startNode->total;
上面的m_openList是一个由最小堆实现的优先队列dtNodeQueue,提供了top,pop,push,modify等接口,以方便每次迭代时获取综合cost最小的dtNode。设置好初始节点之后,就开始了A*的循环迭代流程,不断的获取m_openList中的top,获取这个dtNode对应的Poly:
// Remove node from open list and put it in closed list.
dtNode* bestNode = m_openList->pop();
bestNode->flags &= ~DT_NODE_OPEN;
bestNode->flags |= DT_NODE_CLOSED;
// Reached the goal, stop searching.
if (bestNode->id == endRef)
{
lastBestNode = bestNode;
break;
}
// Get current poly and tile.
// The API input has been cheked already, skip checking internal data.
const dtPolyRef bestRef = bestNode->id;
const dtMeshTile* bestTile = 0;
const dtPoly* bestPoly = 0;
m_nav->getTileAndPolyByRefUnsafe(bestRef, &bestTile, &bestPoly);
// Get parent poly and tile.
dtPolyRef parentRef = 0;
const dtMeshTile* parentTile = 0;
const dtPoly* parentPoly = 0;
if (bestNode->pidx)
parentRef = m_nodePool->getNodeAtIdx(bestNode->pidx)->id;
if (parentRef)
m_nav->getTileAndPolyByRefUnsafe(parentRef, &parentTile, &parentPoly);
遍历这个dtNode里Poly对应的边,去更新相邻Poly对应的dtNode:
for (unsigned int i = bestPoly->firstLink; i != DT_NULL_LINK; i = bestTile->links[i].next)
{
dtPolyRef neighbourRef = bestTile->links[i].ref;
// Skip invalid ids and do not expand back to where we came from.
if (!neighbourRef || neighbourRef == parentRef)
continue;
// Get neighbour poly and tile.
// The API input has been cheked already, skip checking internal data.
const dtMeshTile* neighbourTile = 0;
const dtPoly* neighbourPoly = 0;
m_nav->getTileAndPolyByRefUnsafe(neighbourRef, &neighbourTile, &neighbourPoly);
if (!filter->passFilter(neighbourRef, neighbourTile, neighbourPoly))
continue;
// deal explicitly with crossing tile boundaries
unsigned char crossSide = 0;
if (bestTile->links[i].side != 0xff)
crossSide = bestTile->links[i].side >> 1;
// get the node
dtNode* neighbourNode = m_nodePool->getNode(neighbourRef, crossSide);
if (!neighbourNode)
{
outOfNodes = true;
continue;
}
// If the node is visited the first time, calculate node position.
if (neighbourNode->flags == 0)
{
getEdgeMidPoint(bestRef, bestPoly, bestTile,
neighbourRef, neighbourPoly, neighbourTile,
neighbourNode->pos);
}
// 此处剩余对这个Node进行Cost计算和更新的代码
}
上面获取了一个有效的邻居Poly之后,会利用getEdgeMidPoint计算当前连接dtLink的中间节点坐标作为当前dtNode的坐标,而不是常规的以Poly中心作为距离计算坐标。有了这个路点坐标之后,计算综合cost,如果cost变小了,则更新当前dtNode的parent为之前获取的m_openList中的top,并更新m_openList中对应的dtNode,维护最小堆性质:
// Calculate cost and heuristic.
float cost = 0;
float heuristic = 0;
// Special case for last node.
if (neighbourRef == endRef)
{
// Cost
const float curCost = filter->getCost(bestNode->pos, neighbourNode->pos,
parentRef, parentTile, parentPoly,
bestRef, bestTile, bestPoly,
neighbourRef, neighbourTile, neighbourPoly);
const float endCost = filter->getCost(neighbourNode->pos, endPos,
bestRef, bestTile, bestPoly,
neighbourRef, neighbourTile, neighbourPoly,
0, 0, 0);
cost = bestNode->cost + curCost + endCost;
heuristic = 0;
}
else
{
// Cost
const float curCost = filter->getCost(bestNode->pos, neighbourNode->pos,
parentRef, parentTile, parentPoly,
bestRef, bestTile, bestPoly,
neighbourRef, neighbourTile, neighbourPoly);
cost = bestNode->cost + curCost;
heuristic = dtVdist(neighbourNode->pos, endPos)*H_SCALE;
}
const float total = cost + heuristic;
// The node is already in open list and the new result is worse, skip.
if ((neighbourNode->flags & DT_NODE_OPEN) && total >= neighbourNode->total)
continue;
// The node is already visited and process, and the new result is worse, skip.
if ((neighbourNode->flags & DT_NODE_CLOSED) && total >= neighbourNode->total)
continue;
// Add or update the node.
neighbourNode->pidx = m_nodePool->getNodeIdx(bestNode);
neighbourNode->id = neighbourRef;
neighbourNode->flags = (neighbourNode->flags & ~DT_NODE_CLOSED);
neighbourNode->cost = cost;
neighbourNode->total = total;
if (neighbourNode->flags & DT_NODE_OPEN)
{
// Already in open, update node location.
m_openList->modify(neighbourNode);
}
else
{
// Put the node in open list.
neighbourNode->flags |= DT_NODE_OPEN;
m_openList->push(neighbourNode);
}
这里还有一个额外的一步,记录当前已经计算出来的离目标点启发cost最小的点:
// Update nearest node to target so far.
if (heuristic < lastBestNodeCost)
{
lastBestNodeCost = heuristic;
lastBestNode = neighbourNode;
}
之所以需要记录这个启发cost最小,是因为如果起点与终点不连通的情况下,findPath也需要计算出一条尽可能靠近目标的路径。当然如果起点和终点连通,则这个lastBestNode就是终点。在A*循环迭代完成之后,通过dtNode.parent来反向传播,计算出从起点到lastBestNode的Poly路径,如果lastBestNode不是最终目的地的话,返回值里也会携带相关信息:
dtStatus status = getPathToNode(lastBestNode, path, pathCount, maxPath);
if (lastBestNode->id != endRef)
status |= DT_PARTIAL_RESULT;
if (outOfNodes)
status |= DT_OUT_OF_NODES;
return status;
这个findPath返回的Poly路径中的路点就是相邻Poly的连接边中点,这样的路点连接而成的线段会有很多转角,不够直。所以会执行一个string pulling过程来做后处理,减少不必要的路点并拉直路线。
dtNavMeshQuery也提供了一个函数findStraightPath来执行拉绳过程,函数的开始先初始化拉绳时的拐点和对应的左右两个端点:
float portalApex[3], portalLeft[3], portalRight[3];
dtVcopy(portalApex, closestStartPos);
dtVcopy(portalLeft, portalApex);
dtVcopy(portalRight, portalApex);
int apexIndex = 0;
int leftIndex = 0;
int rightIndex = 0;
unsigned char leftPolyType = 0;
unsigned char rightPolyType = 0;
dtPolyRef leftPolyRef = path[0];
dtPolyRef rightPolyRef = path[0];
然后不断的遍历findPath返回路径中的两个相邻Poly,利用getPortalPoints函数获取对应的portal边对应的两个顶点存储到left,right中:
for (int i = 0; i < pathSize; ++i)
{
float left[3], right[3];
unsigned char toType;
if (i+1 < pathSize)
{
unsigned char fromType; // fromType is ignored.
// Next portal.
getPortalPoints(path[i], path[i+1], left, right, fromType, toType);
// 后续代码暂时省略
}
}
然后利用向量的叉积来分别判断新计算的left,right是否在当前portalLeft->portalApex->portalRight组成的锥形范围内:
- 如果在锥形范围内则替换对应的
portalLeft,portalRight, - 如果不在锥形范围内的话则需要将当前
portalApex加入到最终的路径中,并将拐点portalApex替换为对应的portalLeft或者portalRight,然后更新新的portalLeft和portalRight为portalApex
这部分逻辑对应的代码如下,由于对于左右两个节点的处理是镜像的,所以下面只贴出处理right节点的部分:
// 如果right在 portalApex->portalRight构成的直线的左侧 或者portalApex与portalRight重叠
// 即在锥形内
if (dtTriArea2D(portalApex, portalRight, right) <= 0.0f)
{
if (dtVequal(portalApex, portalRight) || dtTriArea2D(portalApex, portalLeft, right) > 0.0f)
{
// 如果portalApex与portalRight重叠 或者 right在portalApex->portalLeft的右侧
// 则直接更新portalRight为 right
dtVcopy(portalRight, right);
rightPolyRef = (i+1 < pathSize) ? path[i+1] : 0;
rightPolyType = toType;
rightIndex = i;
}
else
{
//当前right在portalApex->portalLeft的左侧 说明当前的portalLeft是一个新的拐点
// 如果开启了portal边记录 这里会存一下数据
if (options & (DT_STRAIGHTPATH_AREA_CROSSINGS | DT_STRAIGHTPATH_ALL_CROSSINGS))
{
stat = appendPortals(apexIndex, leftIndex, portalLeft, path,
straightPath, straightPathFlags, straightPathRefs,
straightPathCount, maxStraightPath, options);
if (stat != DT_IN_PROGRESS)
return stat;
}
// 将拐点设置为当前的portalleft
dtVcopy(portalApex, portalLeft);
apexIndex = leftIndex;
unsigned char flags = 0;
if (!leftPolyRef)
flags = DT_STRAIGHTPATH_END;
else if (leftPolyType == DT_POLYTYPE_OFFMESH_CONNECTION)
flags = DT_STRAIGHTPATH_OFFMESH_CONNECTION;
dtPolyRef ref = leftPolyRef;
// 添加当前拐点到最后的直线路径
stat = appendVertex(portalApex, flags, ref,
straightPath, straightPathFlags, straightPathRefs,
straightPathCount, maxStraightPath);
if (stat != DT_IN_PROGRESS)
return stat;
// 设置三个点重合
dtVcopy(portalLeft, portalApex);
dtVcopy(portalRight, portalApex);
leftIndex = apexIndex;
rightIndex = apexIndex;
// 将i重置为拐点对应的poly索引,重新触发后续的计算
i = apexIndex;
continue;
}
}
迭代整理完成之后straightPath中就存储了最后拉直了的线段列表,至此使用NavMesh的路径查询功能完成。
NavMesh的群体寻路
如果想要以findStraightPath返回的线段列表来驱动寻路entity的每帧位置更新,只需要让entity以一定的速度沿着线段列表进行位置插值计算即可。但是游戏场景里会有多个entity参与寻路,如果每个entity都独立的执行寻路位置更新,很容易就会出现不同entity之间的模型出现穿插。因为使用线段列表插值计算出来的是一个点,而游戏中的entity都是有模型外观的,其形状一般都会被抽象为圆柱体或者更为精确的胶囊体。一个更加合乎直觉的寻路系统不能只用点去驱动entity的位置更新,还需要加入碰撞避免(Collision Avoidance)部分,这部分会根据entity的形状半径来进行路径微调,以避免出现穿插。
因此RecastNavigation还提供了一个带有碰撞避免功能的DetourCrowd子系统,这个子系统负责多个entity的批量寻路更新,这个寻路处理不仅仅是从原点到目标点的路径规划,还包括分步骤的位置更新、碰撞避免、自适应速度等功能。他的管理单位为单个的寻路dtCrowdAgent,每个dtCrowdAgent都有对应的唯一index,与外部代码的交互就是通过index来进行:
const dtCrowdAgent* getAgent(const int idx);
/// Gets the specified agent from the pool.
/// @param[in] idx The agent index. [Limits: 0 <= value < #getAgentCount()]
/// @return The requested agent.
dtCrowdAgent* getEditableAgent(const int idx);
/// The maximum number of agents that can be managed by the object.
/// @return The maximum number of agents.
int getAgentCount() const;
/// Adds a new agent to the crowd.
/// @param[in] pos The requested position of the agent. [(x, y, z)]
/// @param[in] params The configutation of the agent.
/// @return The index of the agent in the agent pool. Or -1 if the agent could not be added.
int addAgent(const float* pos, const dtCrowdAgentParams* params);
/// Removes the agent from the crowd.
/// @param[in] idx The agent index. [Limits: 0 <= value < #getAgentCount()]
void removeAgent(const int idx);
每个dtCrowdAgent在碰撞避免时被当作一个圆柱体来看待,当然碰撞避免系统不仅仅需要Agent的形状参数,还有很多额外参数, 所以dtCrowdAgent里有一个dtCrowdAgentParams类型字段来统一封装所有的参数。使用addAgent初始化dtCrowdAgent时需要提供这个参数,同时运行时可以使用updateAgentParameters动态的修改这个参数:
struct dtCrowdAgentParams
{
float radius; ///< 圆柱体的半径
float height; ///< 圆柱体的高度
float maxAcceleration; ///< 最大加速度
float maxSpeed; ///< 最大速度
/// 碰撞避免预警范围
float collisionQueryRange;
float pathOptimizationRange; ///< 路径优化范围
/// 碰撞避免时的质量权重 质量越大 碰撞避免时对于原始路径的偏移越小
float separationWeight;
/// 更新时的一些标记位
unsigned char updateFlags;
// 碰撞避免类型 指向detourcrowd内部的一个 dtObstacleAvoidanceParams参数数组 用来配置速度改变的行为
unsigned char obstacleAvoidanceType;
/// 这个是dtQueryFilter的索引 detourcrowd内部有一个数组来存储一些queryfilter
unsigned char queryFilterType;
/// 外部提供的一些额外数据 不影响detourcrowd的运行 一般用来调试或者可视化
void* userData;
};
/// Updates the specified agent's configuration.
/// @param[in] idx The agent index. [Limits: 0 <= value < #getAgentCount()]
/// @param[in] params The new agent configuration.
void updateAgentParameters(const int idx, const dtCrowdAgentParams* params);
在初始化好了一个entity对应的dtCrowdAgent之后,dtCrowdAgent处于静止状态,外部可以调用下面的接口来指定寻路的目标点以切换为寻路状态:
/// Submits a new move request for the specified agent.
/// @param[in] idx The agent index. [Limits: 0 <= value < #getAgentCount()]
/// @param[in] ref The position's polygon reference.
/// @param[in] pos The position within the polygon. [(x, y, z)]
/// @return True if the request was successfully submitted.
bool requestMoveTarget(const int idx, dtPolyRef ref, const float* pos);
不过这个函数内部其实并没有做路径计算的相关操作,而是只记录目标点信息:
bool dtCrowd::requestMoveTarget(const int idx, dtPolyRef ref, const float* pos)
{
if (idx < 0 || idx >= m_maxAgents)
return false;
if (!ref)
return false;
dtCrowdAgent* ag = &m_agents[idx];
// Initialize request.
ag->targetRef = ref;
dtVcopy(ag->targetPos, pos);
ag->targetPathqRef = DT_PATHQ_INVALID;
ag->targetReplan = false;
if (ag->targetRef)
ag->targetState = DT_CROWDAGENT_TARGET_REQUESTING;
else
ag->targetState = DT_CROWDAGENT_TARGET_FAILED;
return true;
}
整个DetourCrowd的逻辑处理都在void dtCrowd::update(const float dt, dtCrowdAgentDebugInfo* debug)这个函数里,外部通过调用此接口来按照步长dt(也就是距离上次更新的时间差)更新内部所有agent的状态,包括位置、速度、规划路径等。这个函数比较大,下面就分步骤来解释函数内部代码流程。
生成规划路径
首先要做的就是先修正每个agent从当前点到目标点的规划路径,对应的代码如下:
dtCrowdAgent** agents = m_activeAgents;
int nagents = getActiveAgents(agents, m_maxAgents);
// Check that all agents still have valid paths.
checkPathValidity(agents, nagents, dt);
// Update async move request and path finder.
updateMoveRequest(dt);
// Optimize path topology.
updateTopologyOptimization(agents, nagents, dt);
这里的checkPathValidity会对于位置不在预定path或合法path上的agent,寻找附近离对应path最近的一个Poly,重新生成一次move request,从而进入到下面的updateMoveRequest。
之前的寻路开启函数requestMoveTarget只设置了一个agent的targetState为DT_CROWDAGENT_TARGET_REQUESTING,而updateMoveRequest则负责获取所有状态为DT_CROWDAGENT_TARGET_REQUESTING的agent,推动分步迭代计算一个寻路请求的完整路径:
const dtPolyRef* path = ag->corridor.getPath();
const int npath = ag->corridor.getPathCount();
dtAssert(npath);
static const int MAX_RES = 32;
float reqPos[3];
dtPolyRef reqPath[MAX_RES]; // The path to the request location
int reqPathCount = 0;
// Quick search towards the goal.
static const int MAX_ITER = 20;
m_navquery->initSlicedFindPath(path[0], ag->targetRef, ag->npos, ag->targetPos, &m_filters[ag->params.queryFilterType]);
m_navquery->updateSlicedFindPath(MAX_ITER, 0);
dtStatus status = 0;
if (ag->targetReplan) // && npath > 10)
{
// Try to use existing steady path during replan if possible.
status = m_navquery->finalizeSlicedFindPathPartial(path, npath, reqPath, &reqPathCount, MAX_RES);
}
else
{
// Try to move towards target when goal changes.
status = m_navquery->finalizeSlicedFindPath(reqPath, &reqPathCount, MAX_RES);
}
核心是调用如下三个接口:
initSlicedFindPath初始化一个寻路请求计算的相关资源updateSlicedFindPath内部执行的是一个有迭代次数上限的A*搜索,其代码与dtNavMeshQuery::findPath中的A*搜索实现基本一样finalizeSlicedFindPath释放initSlicedFindPath之前请求的迭代计算资源
但是仅仅在设置好的32次A*迭代就能获取到目标点的完整路径概率其实比较低,所以很大概率上面的三个步骤执行完成之后ag->corridor中存储的路径并没有连接到终点,此时需要记录当前agent的路径搜索未完成,需要后续继续推进:
if (!dtStatusFailed(status) && reqPathCount > 0)
{
// 如果计算出来的路径末端不是最终点
if (reqPath[reqPathCount-1] != ag->targetRef)
{
// 当前reqPath是个非完整路径 计算当前最后一个poly上离最终目标点targetPos最近的一个点 作为中转目标点
status = m_navquery->closestPointOnPoly(reqPath[reqPathCount-1], ag->targetPos, reqPos, 0);
if (dtStatusFailed(status))
reqPathCount = 0;
}
else // 当前是一个完整路径
{
dtVcopy(reqPos, ag->targetPos);
}
}
else
{
reqPathCount = 0;
}
if (!reqPathCount)
{
// Could not find path, start the request from current location.
dtVcopy(reqPos, ag->npos);
reqPath[0] = path[0];
reqPathCount = 1;
}
ag->corridor.setCorridor(reqPos, reqPath, reqPathCount);
ag->boundary.reset();
ag->partial = false;
if (reqPath[reqPathCount-1] == ag->targetRef) // 如果完成了路径搜索 则agent切换为可以寻路的状态
{
ag->targetState = DT_CROWDAGENT_TARGET_VALID;
ag->targetReplanTime = 0.0;
}
else // 否则标记当前agent的路径还未完成 需要后续的推进
{
ag->targetState = DT_CROWDAGENT_TARGET_WAITING_FOR_QUEUE;
}
由于当前处理的是多个agent的寻路,所以可能会有多个agent同时处于路径未完成的状态,DetourCrowd使用了一个有最大容量限制的有序数组queue来存储所有需要后续推进路径查询的agent:
if (ag->targetState == DT_CROWDAGENT_TARGET_WAITING_FOR_QUEUE)
{
nqueue = addToPathQueue(ag, queue, nqueue, PATH_MAX_AGENTS);
}
上面的addToPathQueue其实就是一个插入排序,排序的依据为agent->targetReplanTime,代表下一次路径计算的期望时间,值越小则优先级越大。
在收集好了未完成路径搜索的排序好的agent数组queue之后,会放入一个DetourPathQueue m_pathq的容器中,记录对应的未完成部分的路径查询:
for (int i = 0; i < nqueue; ++i)
{
dtCrowdAgent* ag = queue[i];
ag->targetPathqRef = m_pathq.request(ag->corridor.getLastPoly(), ag->targetRef,
ag->corridor.getTarget(), ag->targetPos, &m_filters[ag->params.queryFilterType]);
if (ag->targetPathqRef != DT_PATHQ_INVALID) //添加成功才能切换到waiting_for_path状态
ag->targetState = DT_CROWDAGENT_TARGET_WAITING_FOR_PATH;
}
不过这里的m_pathq其实也是有容量上限的,最大支持static const int MAX_QUEUE = 8 个元素,所以如果添加不进去的话,当前agent的状态会维持在DT_CROWDAGENT_TARGET_WAITING_FOR_QUEUE状态,如果添加成功,才能切换到DT_CROWDAGENT_TARGET_WAITING_FOR_PATH状态。
在detourPathQueue添加request完成之后,执行一次统一更新来驱动所有的未完成路径的推进:
static const int MAX_ITERS_PER_UPDATE = 100;
// Update requests.
m_pathq.update(MAX_ITERS_PER_UPDATE);
不过这个update函数也是有最大迭代次数上限的:
void dtPathQueue::update(const int maxIters)
{
static const int MAX_KEEP_ALIVE = 2; // in update ticks.
// Update path request until there is nothing to update
// or upto maxIters pathfinder iterations has been consumed.
int iterCount = maxIters;
for (int i = 0; i < MAX_QUEUE; ++i)
{
PathQuery& q = m_queue[m_queueHead % MAX_QUEUE];
// Skip inactive requests.
if (q.ref == DT_PATHQ_INVALID)
{
m_queueHead++;
continue;
}
// 遍历当前pathqueue中需要处理的寻路请求
// Handle completed request.
if (dtStatusSucceed(q.status) || dtStatusFailed(q.status))
{
// 如果路径计算完成但是外部长时间没有读取路径查询状态 则释放当前寻路请求所占据的槽位
q.keepAlive++;
if (q.keepAlive > MAX_KEEP_ALIVE)
{
q.ref = DT_PATHQ_INVALID; // 标记为当前槽位可用
q.status = 0;
}
m_queueHead++;
continue;
}
// status为0 代表还未初始化当前查询
if (q.status == 0)
{
q.status = m_navquery->initSlicedFindPath(q.startRef, q.endRef, q.startPos, q.endPos, q.filter);
}
// 推进路径查询的迭代 最大迭代次数为iterCount 迭代完成之后扣除剩余迭代次数
if (dtStatusInProgress(q.status))
{
int iters = 0;
q.status = m_navquery->updateSlicedFindPath(iterCount, &iters);
iterCount -= iters;
}
if (dtStatusSucceed(q.status)) // 路过路径查询完成 则可以释放相关资源
{
q.status = m_navquery->finalizeSlicedFindPath(q.path, &q.npath, m_maxPathSize);
}
if (iterCount <= 0) // 如果整体迭代次数已经用完 则退出循环
break;
m_queueHead++;
}
}
注意上面的m_queueHead,这个字段用来指定下一次循环处理m_queue中哪一个slot,每次处理完之后都递增,以增加不同请求之间的公平性。因为每次都从0开始遍历会导致slot越大优先级越低的情况, 极端情况下后面的几个slot的请求永远不会被处理,出现饥饿现象。不过上面代码的最后一个部分也有问题,如果一个长路径请求没有完成,则会导致每次update执行时都尝试推进这个长路径请求,在路径不可达的情况下会阻塞住所有其他请求的更新。所以应该将m_queueHead++放到if (iterCount <= 0)的前面,这样才能增加公平性。
m_pathq.update执行完成之后,需要遍历所有状态为DT_CROWDAGENT_TARGET_WAITING_FOR_PATH的agent, 获取路径查询的推进状态,只有真正完成了路径查询的agent才会切换到DT_CROWDAGENT_TARGET_VALID状态:
// 获取pathq中路径查询结果已经出来的
if (ag->targetState == DT_CROWDAGENT_TARGET_WAITING_FOR_PATH)
{
// 获取路径查询的结果
status = m_pathq.getRequestStatus(ag->targetPathqRef);
if (dtStatusFailed(status)) // 路径查询失败
{
// Path find failed, retry if the target location is still valid.
ag->targetPathqRef = DT_PATHQ_INVALID;
if (ag->targetRef)
ag->targetState = DT_CROWDAGENT_TARGET_REQUESTING;
else
ag->targetState = DT_CROWDAGENT_TARGET_FAILED;
ag->targetReplanTime = 0.0;
}
else if (dtStatusSucceed(status)) // 路径查询成功
{
const dtPolyRef* path = ag->corridor.getPath();
const int npath = ag->corridor.getPathCount();
dtAssert(npath);
// Apply results.
float targetPos[3];
dtVcopy(targetPos, ag->targetPos);
dtPolyRef* res = m_pathResult;
bool valid = true;
int nres = 0;
status = m_pathq.getPathResult(ag->targetPathqRef, res, &nres, m_maxPathResult);
if (dtStatusFailed(status) || !nres)
valid = false;
if (dtStatusDetail(status, DT_PARTIAL_RESULT))
ag->partial = true;
else
ag->partial = false;
// 由于agent可能重新发起了移动请求 所以这里需要检查corridor的末尾是否等于当前查询的开始
if (valid && path[npath-1] != res[0])
valid = false;
if (valid)
{
if (npath > 1)
{
// 这部分代码负责将原来的路径与新查询的路径做合并
// 路径中出现A->B->A的状况,则会把B->A 这个线段删除
}
// 如果仍然没有到达目标点 则计算末尾poly中离目标点最近的点
if (res[nres-1] != ag->targetRef)
{
// Partial path, constrain target position inside the last polygon.
float nearest[3];
status = m_navquery->closestPointOnPoly(res[nres-1], targetPos, nearest, 0);
if (dtStatusSucceed(status))
dtVcopy(targetPos, nearest);
else
valid = false;
}
}
if (valid)
{
// 更新corridor
ag->corridor.setCorridor(targetPos, res, nres);
// 由于agent开始移动了 所以要清楚之前计算的周围障碍物信息
ag->boundary.reset();
ag->targetState = DT_CROWDAGENT_TARGET_VALID; // valid代表可以开始移动了
}
else
{
// 请求失败
ag->targetState = DT_CROWDAGENT_TARGET_FAILED;
}
ag->targetReplanTime = 0.0;
}
}
至此updateMoveRequest的函数体结束,整体而言updateMoveRequest实现了一个比较公平的多agent的寻路请求带上限的时间片机制,通过这个时间片机制避免了完整的计算寻路路径时消耗时间太长的问题。,使得dtcrowd::update函数的执行时间总体可控,这样才能更好的接入游戏循环,避免dtcrowd::update可能引发的卡帧现象。
updateTopologyOptimization函数则负责矫正一些agent位置由于碰撞避免强制调整位置系统引发的corridor偏移现象,此时会定期的对corridor进行重新计算。这里也使用了一个带迭代上限和优先级的时间片机制,每个agent的路径优化间隔要求大于0.5s:
void dtCrowd::updateTopologyOptimization(dtCrowdAgent** agents, const int nagents, const float dt)
{
if (!nagents)
return;
const float OPT_TIME_THR = 0.5f; // seconds
const int OPT_MAX_AGENTS = 1; // 这里的常量为1 代表本次最多处理一个agent的路径优化
dtCrowdAgent* queue[OPT_MAX_AGENTS];
int nqueue = 0;
for (int i = 0; i < nagents; ++i)
{
dtCrowdAgent* ag = agents[i];
if (ag->state != DT_CROWDAGENT_STATE_WALKING)
continue;
if (ag->targetState == DT_CROWDAGENT_TARGET_NONE || ag->targetState == DT_CROWDAGENT_TARGET_VELOCITY)
continue;
if ((ag->params.updateFlags & DT_CROWD_OPTIMIZE_TOPO) == 0)
continue;
ag->topologyOptTime += dt;
if (ag->topologyOptTime >= OPT_TIME_THR) // 只有间隔时间大于0.5的才会考虑优化 避免频繁重算
nqueue = addToOptQueue(ag, queue, nqueue, OPT_MAX_AGENTS);
}
for (int i = 0; i < nqueue; ++i) // 对于上面收集的需要重算的agent 调用对应corridor的路径优化函数
{
dtCrowdAgent* ag = queue[i];
// 这里的optimizePathTopology 其实就是执行一次开始到末尾的有32次迭代次数限制的A*搜索
// 搜索出来的临时路径会与之前的完整路径做合并
ag->corridor.optimizePathTopology(m_navquery, &m_filters[ag->params.queryFilterType]);
ag->topologyOptTime = 0;
}
}
周围阻挡物计算
在完成了初始的路径规划之后,接下来需要获取每个agent周围阻挡范围内的其他agent的集合,以及周围不可通行的多边形的边集合,以计算agent接受的排斥力的合力。
获取周围一定半径的的agent集合就是我们在之前介绍过的AOI系统,DetourCrowd使用的是最常见的九宫格系统,其逻辑都被dtProximityGrid这个类型承担了:
// 先把所有的agent都添加到dtProximityGrid中
m_grid->clear();
for (int i = 0; i < nagents; ++i)
{
dtCrowdAgent* ag = agents[i];
const float* p = ag->npos;
const float r = ag->params.radius;
m_grid->addItem((unsigned short)i, p[0]-r, p[2]-r, p[0]+r, p[2]+r);
}
// 计算每个agent周围的阻挡poly和其他agent
for (int i = 0; i < nagents; ++i)
{
dtCrowdAgent* ag = agents[i];
if (ag->state != DT_CROWDAGENT_STATE_WALKING)
continue;
// ag->boundary里负责存储当前agent一定范围内的不可通行poly的边
// 由于每次都重新计算boundary会很消耗时间 因此只有当agent与上次计算的位置相差大于一定范围之后才触发重新计算
const float updateThr = ag->params.collisionQueryRange*0.25f;
if (dtVdist2DSqr(ag->npos, ag->boundary.getCenter()) > dtSqr(updateThr) ||
!ag->boundary.isValid(m_navquery, &m_filters[ag->params.queryFilterType]))
{
ag->boundary.update(ag->corridor.getFirstPoly(), ag->npos, ag->params.collisionQueryRange,
m_navquery, &m_filters[ag->params.queryFilterType]);
}
// 使用dtProximityGrid实现的九宫格来查询周围一定范围内的其他agent
ag->nneis = getNeighbours(ag->npos, ag->params.height, ag->params.collisionQueryRange,
ag, ag->neis, DT_CROWDAGENT_MAX_NEIGHBOURS,
agents, nagents, m_grid);
for (int j = 0; j < ag->nneis; j++)
ag->neis[j].idx = getAgentIndex(agents[ag->neis[j].idx]);
}
由于dtProximityGrid的实现与常规的九宫格AOI实现基本相同,所以这里就直接掠过,重点介绍一下ag->boundary的计算:
static const int DT_VERTS_PER_POLYGON = 6;
void dtLocalBoundary::update(dtPolyRef ref, const float* pos, const float collisionQueryRange,
dtNavMeshQuery* navquery, const dtQueryFilter* filter)
{
static const int MAX_SEGS_PER_POLY = DT_VERTS_PER_POLYGON*3; // 18
if (!ref)
{
dtVset(m_center, DT_REAL_MAX,DT_REAL_MAX,DT_REAL_MAX);
m_nsegs = 0;
m_npolys = 0;
return;
}
dtVcopy(m_center, pos);
// 这里先查询当前一定半径内的与当前agent所在poly不重叠的所有其他poly
navquery->findLocalNeighbourhood(ref, pos, collisionQueryRange,
filter, m_polys, 0, &m_npolys, MAX_LOCAL_POLYS);
// Secondly, store all polygon edges.
m_nsegs = 0;
float segs[MAX_SEGS_PER_POLY*6];
int nsegs = 0;
for (int j = 0; j < m_npolys; ++j)
{
// 这里会计算这个poly中当前agent 的filter无法通过的边集合
navquery->getPolyWallSegments(m_polys[j], filter, segs, 0, &nsegs, MAX_SEGS_PER_POLY);
for (int k = 0; k < nsegs; ++k)
{
const float* s = &segs[k*6];
// Skip too distant segments.
float tseg;
const float distSqr = dtDistancePtSegSqr2D(pos, s, s+3, tseg);
if (distSqr > dtSqr(collisionQueryRange)) // 如果当前agent离这条边太远 则忽略
continue;
addSegment(distSqr, s); // 这里会存储不可通行边和对应的距离
}
}
}
dtLocalBoundary内部对于阻挡边的存储也使用了一个带上限的有序数组,数组中存储的元素则是阻挡边的两个端点和当前agent位置到阻挡边的距离:
class dtLocalBoundary
{
static const int MAX_LOCAL_SEGS = 8;
static const int MAX_LOCAL_POLYS = 16;
struct Segment
{
float s[6]; ///< Segment start/end
float d; ///< Distance for pruning.
};
float m_center[3]; // 每次update时agent的位置
Segment m_segs[MAX_LOCAL_SEGS]; // 阻挡边数组
int m_nsegs; // 阻挡边个数
dtPolyRef m_polys[MAX_LOCAL_POLYS]; //周围的多边形
int m_npolys;
void addSegment(const float dist, const float* s);
}
速度计算
期望最大速度
为了计算速度,我们首先需要获取每个agent路径上的每个拐点,这部分逻辑由ag->corridor.findCorners负责,其实就是调用之前介绍的findStraightPath来执行拉绳算法并获取拐点。计算好每一个拐点之后,开始来校正速度偏向。首先执行下面的逻辑:
// Calculate steering direction.
if (ag->params.updateFlags & DT_CROWD_ANTICIPATE_TURNS)
calcSmoothSteerDirection(ag, dvel);
else
calcStraightSteerDirection(ag, dvel);
calcSmoothSteerDirection 流程简略版如下:
- 设置当前节点为
np, 第一个拐点为p0, 第二个拐点为p1 - 向量
d0为p0 - np,len0为d0长度,向量d1为p1 - np,len1为d1长度 - 归一化
d0, d1为单位向量 - 计算
d2 = d0 - d1 * 0.5,然后归一化为单位向量,返回d2这里的减法,相当于朝下下个拐点的反方向偏移,避免靠的太近,从而形成一个光滑的圆弧。而calcStraightSteerDirection则简单多了,直接计算d0的单位向量返回即可。
计算完偏向力之后,我们再来计算速度的衰减:这个只有在靠近目标点的时候才会出发这个衰减,计算方式大概为speedscale = min(1, distance(np, dest_p)/ slowDownRadius)。
计算完上面这几个参数之后,我们计算出agent的期望最大速度dvel = maxSpeed * d2 * speedScale。这个devl就是纯的不考虑任何碰撞避免寻路时的速度计算。
碰撞避免速度修正
为了避免多个agent寻路出现重叠,会给每个agent上设置一个碰撞避免距离separationDist。对于当前agent距离separationDist内的所有其他agent,都会给当前agent施加一个斥力。斥力大小与两者距离反比,计算公式为max(0, 1 - distance(onp - anp) / range),其中anp为当前agent的坐标, onp为其他agent的坐标, range为分离半径。然后一个agent上的所有斥力向量和的结果为这个agent的disp向量, 同时施加了斥力的agent数量为isp_num。有了这几个参数之后,我们进一步修正上一步计算的速度偏向:
dvel = dvel + disp/isp_num
上面的分离斥力只是在进入碰撞之后的疏解措施,最好的方法是预先规划出来的路径可以避免碰撞重叠的发生。为此我们先构造碰撞环境,然后再进行碰撞寻路速度修正。碰撞环境就是agent的邻居及对应的碰撞半径,以及自身路径规划里的poly边界:
m_obstacleQuery->reset();
// Add neighbours as obstacles.
for (int j = 0; j < ag->nneis; ++j)
{
const dtCrowdAgent* nei = &m_agents[ag->neis[j].idx];
m_obstacleQuery->addCircle(nei->npos, nei->params.radius, nei->vel, nei->dvel);
}
// Append neighbour segments as obstacles.
for (int j = 0; j < ag->boundary.getSegmentCount(); ++j)
{
const float* s = ag->boundary.getSegment(j);
// 注意这里利用了叉积的方向来过滤不需要处理的边
if (dtTriArea2D(ag->npos, s, s+3) < 0.0f)
continue;
m_obstacleQuery->addSegment(s, s+3);
}
而后的速度规划又有两种模式:
const dtObstacleAvoidanceParams* params = &m_obstacleQueryParams[ag->params.obstacleAvoidanceType];
if (adaptive)
{
ns = m_obstacleQuery->sampleVelocityAdaptive(ag->npos, ag->params.radius, ag->desiredSpeed,
ag->vel, ag->dvel, ag->nvel, params, vod);
}
else
{
ns = m_obstacleQuery->sampleVelocityGrid(ag->npos, ag->params.radius, ag->desiredSpeed,
ag->vel, ag->dvel, ag->nvel, params, vod);
}
先来看简单版本的sampleVelocityGrid,这个函数会构造一个可选的速度集合,遍历集合中的每个合法的速度vcand,来计算在此速度下与障碍物相撞的惩罚系数:
int dtObstacleAvoidanceQuery::sampleVelocityGrid(const float* pos, const float rad, const float vmax,
const float* vel, const float* dvel, float* nvel,
const dtObstacleAvoidanceParams* params,
dtObstacleAvoidanceDebugData* debug)
{
prepare(pos, dvel);
memcpy(&m_params, params, sizeof(dtObstacleAvoidanceParams));
m_invHorizTime = 1.0f / m_params.horizTime;
m_vmax = vmax;
m_invVmax = vmax > 0 ? 1.0f / vmax : DT_REAL_MAX;
dtVset(nvel, 0,0,0);
if (debug)
debug->reset();
const float cvx = dvel[0] * m_params.velBias;
const float cvz = dvel[2] * m_params.velBias;
const float cs = vmax * 2 * (1 - m_params.velBias) / (float)(m_params.gridSize-1); // 速度变化的最小单位
const float half = (m_params.gridSize-1)*cs*0.5f; // x z 两个方向速度的最大变动范围
float minPenalty = DT_REAL_MAX;
int ns = 0;
// 这里会生成一个gridSize * gridSize的采样
for (int y = 0; y < m_params.gridSize; ++y)
{
for (int x = 0; x < m_params.gridSize; ++x)
{
float vcand[3]; // 构造一个随机扰动后的速度
vcand[0] = cvx + x*cs - half;
vcand[1] = 0;
vcand[2] = cvz + y*cs - half;
// 如果速度超过最大值一定阈值则放弃这个速度
if (dtSqr(vcand[0])+dtSqr(vcand[2]) > dtSqr(vmax+cs/2)) continue;
// 计算当前速度下的碰撞惩罚值
const float penalty = processSample(vcand, cs, pos,rad,vel,dvel, minPenalty, debug);
ns++;
if (penalty < minPenalty)// 获取惩罚值最小的速度
{
minPenalty = penalty;
dtVcopy(nvel, vcand);
}
}
}
return ns;
}
通过processSample计算出当前可选速度的惩罚值之后,选取惩罚最小的,计算出新的修正速度。这里的processSample计算penalty不仅考虑了当前速度下与周围障碍物相撞的最早时间,还考虑了为了避免与agent碰撞引发的速度修正惩罚(这里需要考虑当前速度和之前路径规划计算的期望速度),以及正面相撞的惩罚:
// penalty for straying away from the desired and current velocities
const float vpen = m_params.weightDesVel * (dtVdist2D(vcand, dvel) * m_invVmax); // 与当前无阻挡期望速度之间的差值
const float vcpen = m_params.weightCurVel * (dtVdist2D(vcand, vel) * m_invVmax); // 与当前实际速度之间的差值
float tmin = m_params.horizTime;
float side = 0; // 代表冲击系数 这个值越大代表agent之间的正面对撞的趋势越大
int nside = 0; // 代表与多少个agent相交
for (int i = 0; i < m_ncircles; ++i)
{
// 计算在当前速度下与其他agent相撞的最早时间 其实就是计算两个带有速度的圆形何时相撞
const dtObstacleCircle* cir = &m_circles[i];
float vab[3];
dtVscale(vab, vcand, 2);
dtVsub(vab, vab, vel);
dtVsub(vab, vab, cir->vel);
// cir->dp代表两个agent之间连线的单位向量 cir->np 代表与dp垂直的单位向量
side += dtClamp<float>(dtMin(dtVdot2D(cir->dp,vab)*0.5f+0.5f, dtVdot2D(cir->np,vab)*2), 0.0f, 1.0f);
nside++;
float htmin = 0, htmax = 0;
// 省略一些代码
}
for (int i = 0; i < m_nsegments; ++i)
{
// 计算当前速度方向与周围不可通行边的最早相撞时间
const dtObstacleSegment* seg = &m_segments[i];
float htmin = 0;
// 省略一些代码
}
// Normalize side bias, to prevent it dominating too much.
if (nside)
side /= nside;
const float spen = m_params.weightSide * side;
const float tpen = m_params.weightToi * (1.0f/(0.1f+tmin*m_invHorizTime)); // 这部分则是碰撞事件的惩罚项
const float penalty = vpen + vcpen + spen + tpen;
而sampleVelocityAdaptive与前面的sampleVelocityGrid大同小异,他首先设置一个速度差异采样半径r,然后在当前速度dvel末端为圆心半径为r的圆上以均匀角度间隔进行速度采样v,获取processSample计算出来的惩罚最小速度。然后再将采样半径r进行收缩一定比例,在v末端以r为半径的园上再次进行速度采样获取其中惩罚最小速度,重复这个过程多次直到相邻两次迭代的惩罚系数差值小于一定值,或者达到了最大迭代次数上限。sampleVelocityAdaptive的调用processSample的次数会比sampleVelocityGrid大很多,好处是能够获得一个更好的避障速度。不过实际场景中一般都是运行速度优先,选择的都是sampleVelocityGrid,以至于sampleVelocityAdaptive代码里面有数组越界,还是在我自己跑样例测试的时候发现的,对应的issue在https://github.com/recastnavigation/recastnavigation/issues/496。
位置更新
基于速度的位置更新
在前面计算好速度之后,调用integrate(dtCrowdAgent* ag, const float dt)来更新agent的位置,这里考虑了这个agent在最大加速情况下的位置移动长度。
static void integrate(dtCrowdAgent* ag, const float dt)
{
// Fake dynamic constraint.
const float maxDelta = ag->params.maxAcceleration * dt;
float dv[3];
dtVsub(dv, ag->nvel, ag->vel); // nvel是指定方向上的最大速度 这里计算当前速度与期望最大速度的差值
float ds = dtVlen(dv);
if (ds > maxDelta) // 以最大加速度来限制速度的变化范围
dtVscale(dv, dv, maxDelta/ds);
dtVadd(ag->vel, ag->vel, dv); // 最后更新速度到vel上
// 速度乘以时间就是本次update中当前agent的位置偏移值
if (dtVlen(ag->vel) > 0.0001f)
dtVmad(ag->npos, ag->npos, ag->vel, dt);
else // 速度太小则直接设置为静止
dtVset(ag->vel,0,0,0);
}
碰撞避免位置微调
在上面的位置更新之后,我们需要重新计算一下位置下的所有agent之间的碰撞惩罚,然后再微调一下碰撞斥力因为的位置更新。有四轮微调,每次都用agent的调整之后的位置,每一对agent B对agent A的位置更新计算如下:
diff = a.npos - b.npos计算两个agent之间的位置差,dist为欧几里得距离pen = (1 / dist) *(radius_a + radius_b - dist) * Factor,为两者的碰撞半径减去两者的距离然后再除以两者之间的距离,作为碰撞惩罚值isp_offset = average(diff * pen),计算所有agent贡献的偏移量的均值,作为位置修正的值npos = npos + isp_offset, 更新目标位置,加上新计算出来的修正值
注意这里进行碰撞避免微调的时候是无视了不可通行多边形的,所以这里微调结束之后可能会出现位置已经不在可行走表面的情况,所以后续还需要一步来将调整后的位置拉回可行走表面。
将位置限制在表面
上面我们计算的位置更新都是基于2d的位置更新,我们需要将这个2d位置映射到3d寻路网格上的点。此时不再需要投影计算所有的相交Poly,只需要利用之前路径规划的Poly结果缩小检索范围即可,对应的函数为dtPathCorridor::movePosition:
bool dtPathCorridor::movePosition(const dtReal_t* npos, dtNavMeshQuery* navquery, const dtQueryFilter* filter)
{
dtAssert(m_path);
dtAssert(m_npath);
// Move along navmesh and update new position.
dtReal_t result[3];
static const int MAX_VISITED = 16;
dtPolyRef visited[MAX_VISITED];
int nvisited = 0;
// 从m_pos 移动到npos 记录其经过的一些poly 如果npos不可达则result会记录可行走表面上离它最近的位置
dtStatus status = navquery->moveAlongSurface(m_path[0], m_pos, npos, filter,
result, visited, &nvisited, MAX_VISITED);
if (dtStatusSucceed(status)) {
// 删除原始路径开头已经走完的poly
m_npath = dtMergeCorridorStartMoved(m_path, m_npath, m_maxPath, visited, nvisited);
// 然后再计算result在mesh上的高度
dtReal_t h = m_pos[1];
navquery->getPolyHeight(m_path[0], result, &h);
result[1] = h;
dtVcopy(m_pos, result);
return true;
}
return false;
}
上面的核心函数为moveAlongSurface其实执行的也是一次A*搜索,搜索了从m_pos到n_pos经过的多边形路径,如果n_pos不可达则会选择周围可行走多边形里离npos最近的一个位置,并更新到result中。一般来说在单次update时间内m_pos与npos之间的多边形路径长度在两个以内,所以这个函数的整体执行时间还是很短的。