Recast Navigation 详解
Recast Navigation自2012年开源在github上之后,由于其生成NavMesh的速度快,运行时内存占用小,接入方便等有点,迅速的成为了游戏业界三维场景地表寻路的标准解决方案。两大主流游戏引擎Unity、Unreal以及网易的Messiah、NeoX引擎等自带的寻路方案都是基于开源版本进行的修改迭代而来。由于Recast Navigation作为寻路解决基础方案的重要性,我们将在本章节中对其生成NavMesh的工作流程进行详解,方便理解其原理以及后续的参数调优。
recast navigation 的基本步骤
recast navigation软件按照功能可以分为三个部分:
- 负责生成场景对应
NavMesh的recast部分 - 使用
NavMesh来执行连通路径寻找的detour部分 - 使用连通路径驱动多个寻路
entity位置更新的DetourCrowd部分
此外此软件自带一个可视化的编辑器RecastDemo来展示recast和detour的各阶段执行结果。
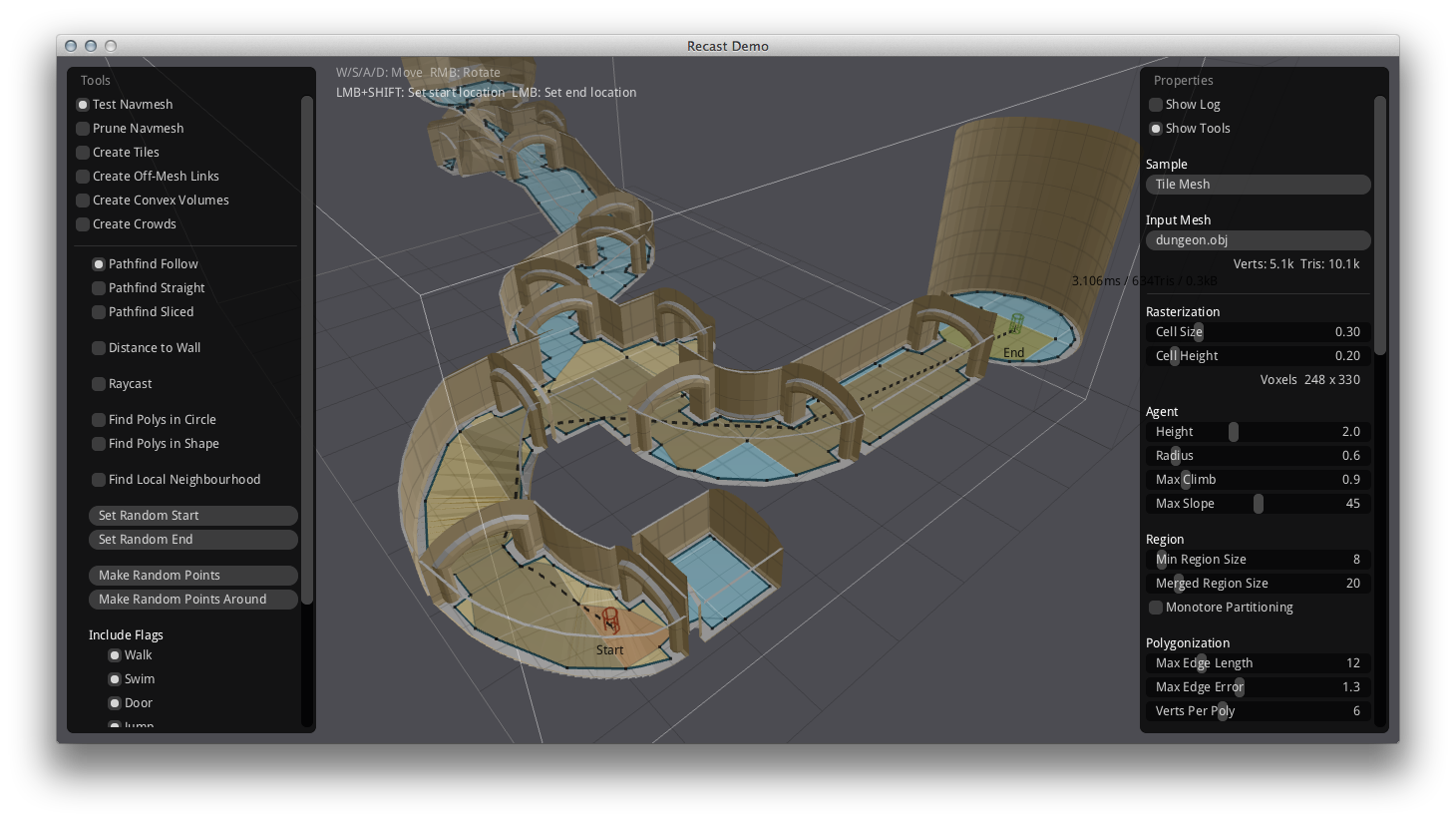
本章内容主要介绍其中的Recast部分,Detour和DetourCrowd部分将在后面的群体寻路章节中进行介绍。在这个RecastDemo程序中,我们首先需要导入obj格式的场景文件:
导入完成之后,配置好相关的参数,再点击生成按钮,即可获取如下的带NavMesh可视化的结果,图中的浅蓝色区域代表NavMesh中的多边形构造的可行走表面:

当然从场景数据生成NavMesh的过程并不是点击几下按钮这么简单,它其实包括了如下几个步骤:
- 导入场景并配置生成
NavMesh的相关参数

- 将场景进行体素化

-
筛选可行走表面 这里主要过滤掉一些会引起圆柱体寻路时与环境穿插的情况
-
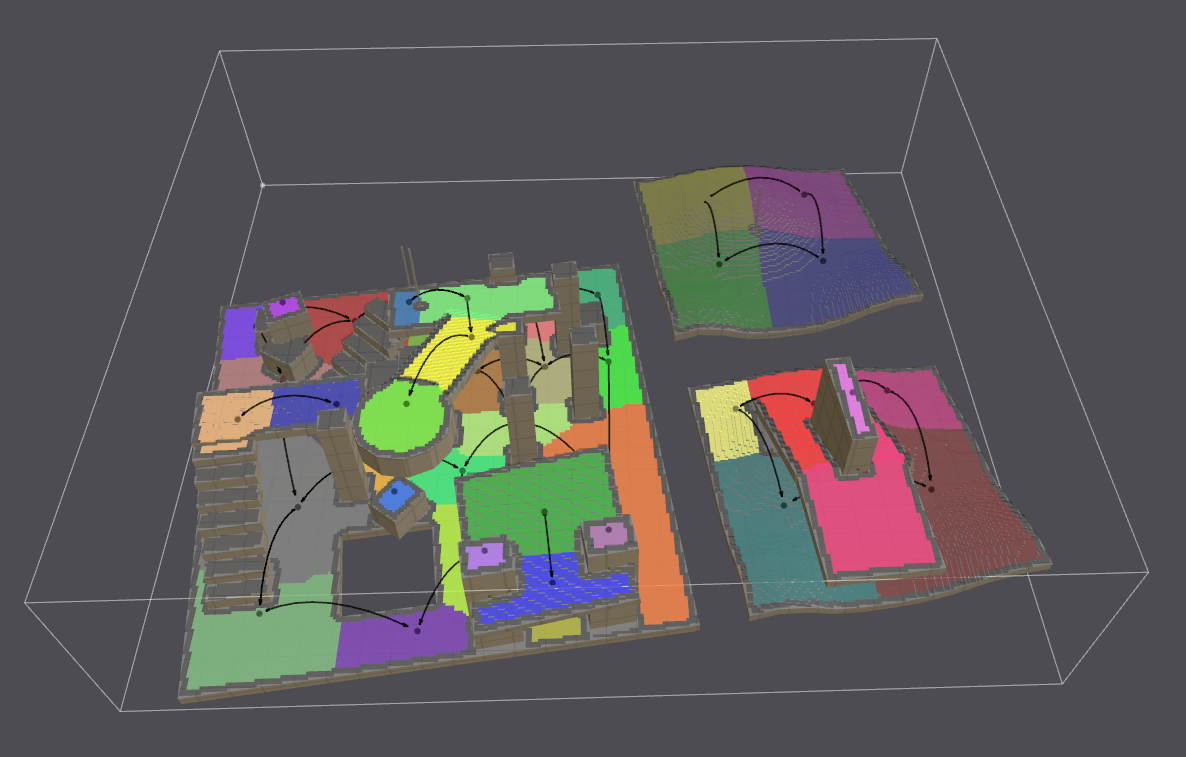
将可行走表面拆分为多片连续的区域,下图中每个颜色代表一个区域,每条黑色的弧形边代表对应的两个区域连通
- 将各个区域的轮廓进行平滑,减少用来后续要处理的顶点数量


- 对各个区域进行三角划分,然后执行三角合并,生成凸多边形
Mesh

- 创建细节
Mesh数据以贴合地表

- 生成最后的导航网格
后续我们将对这八个步骤对照源代码进行详解。
加载场景数据
Recast支持的场景描述文件为Wavefront格式的OBJ文件,在源码目录的RecastDemo/Bin/Meshes里提供了多个样例文件。这个OBJ格式规范比较简单,是基于行的文本文件。OBJ文件由一行行文本组成,注释行以一个#为开头,空格和空行可以随意加到文件中以增加文件的可读性。有字的行都由一两个标记字母也就是关键字(Keyword)开头,关键字可以说明这一行是什么样的数据。多行可以逻辑地连接在一起表示一行,方法是在每一行最后添加一个连接符\。Recast支持了下面几种基本关键字:
v几何体顶点(Geometric vertices)后续接着三个浮点数代表这个顶点的坐标,例如v -0.58 0.84 0,所有的顶点都会赋予一个隐式的递增编号,编号的值为此顶点的出现顺序,第一个编号为1vn顶点法线(Vertex normals)后续接着三个浮点数代表此法线的坐标,例如vn 0.000000 -1.000000 0.000000,这个顶点法线也有一个隐士递增编号,规则与几何体顶点一样vt贴图坐标点(Texture vertices)后续接着两个浮点数,例如vt 0.0 0.5,贴图坐标点也有类似于几何体顶点的编号规则f代表多边形的面 后续接着多个个三元组, 每个三元组都有一个整数,分别索引到几何体顶点、顶点法线、贴图坐标点,样例f 1/1/1 2/2/2 4/4/3就声明了一个三角形,多边形内的点的坐标以逆时针排列
recast加载OBJ格式文件的代码在bool rcMeshLoaderObj::load(const std::string& filename)中,其加载逻辑忽略了所有的vn、vt分量,同时对于读取到的多边形面数据,进行拆分为多个三角形:
nv = parseFace(row+1, face, 32, m_vertCount);
for (int i = 2; i < nv; ++i)
{
const int a = face[0];
const int b = face[i-1];
const int c = face[i];
if (a < 0 || a >= m_vertCount || b < 0 || b >= m_vertCount || c < 0 || c >= m_vertCount)
continue;
addTriangle(a, b, c, tcap);
}
添加完成所有的三角形之后,再分别计算每个三角形的面法线数据:
// Calculate normals.
m_normals = new float[m_triCount*3];
for (int i = 0; i < m_triCount*3; i += 3)
{
const float* v0 = &m_verts[m_tris[i]*3];
const float* v1 = &m_verts[m_tris[i+1]*3];
const float* v2 = &m_verts[m_tris[i+2]*3];
float e0[3], e1[3];
for (int j = 0; j < 3; ++j)
{
e0[j] = v1[j] - v0[j];
e1[j] = v2[j] - v0[j];
}
float* n = &m_normals[i];
n[0] = e0[1]*e1[2] - e0[2]*e1[1];
n[1] = e0[2]*e1[0] - e0[0]*e1[2];
n[2] = e0[0]*e1[1] - e0[1]*e1[0];
float d = std::sqrt(n[0]*n[0] + n[1]*n[1] + n[2]*n[2]);
if (d > 0)
{
d = 1.0f/d;
n[0] *= d;
n[1] *= d;
n[2] *= d;
}
}
上面循环中的e0,e1代表三角形的两条首尾相连逆时针的边,而n则是这两个向量计算出来的叉积,这个叉积的方向一定是与当前面垂直的,同时代表当前面的正向,最后再单位化。
同时在RecastDemo中为了支持点击获取三角形的操作,还对加载好的OBJ文件做了一个BVH结构,创建了一个rcChunkyTriMesh来加速点选查询:
#define float float
bool rcCreateChunkyTriMesh(const float* verts, const int* tris, int ntris,
int trisPerChunk, rcChunkyTriMesh* cm)
参数中的verts存储了所有的节点,tris存储了所有的三角形面,ntris代表有多少个三角形,trisPerChunk代表BVH树的叶子节点里存储的三角形的数量。这个函数初始时需要构造好所有的BVH Node和所有三角形的AABB Bound:
struct BoundsItem
{
float bmin[2];
float bmax[2];
int i;
};
int nchunks = (ntris + trisPerChunk-1) / trisPerChunk;
cm->nodes = new rcChunkyTriMeshNode[nchunks*4];
if (!cm->nodes)
return false;
cm->tris = new int[ntris*3];
if (!cm->tris)
return false;
cm->ntris = ntris;
// Build tree
BoundsItem* items = new BoundsItem[ntris];
if (!items)
return false;
for (int i = 0; i < ntris; i++)
{
const int* t = &tris[i*3];
BoundsItem& it = items[i];
it.i = i;
// 这里有一些代码负责计算三角形的在XZ平面的AABB bound 直接忽略了高度轴Y轴
}
这里引入了两个结构体:
struct BoundsItem
{
float bmin[2];
float bmax[2];
int i;
};
struct rcChunkyTriMeshNode
{
float bmin[2];
float bmax[2];
int i;
int n;
};
BoundsItem就代表一个只在XZ平面的AABB包围盒,而rcChunkyTriMeshNode代表BVH树之中的节点,这里除了有包围盒信息之外,还有两个字段i,n:
i如果为非负数则代表这个节点是叶子节点,i的值就是其包含的多个连续三角形在cm->tris的开始索引,此时n则代表内部包含的三角形的个数i如果为负数,则其绝对值代表其下面各个层级的子节点的总数,
这里不存储左右两个子节点的偏移量是因为左子节点相对于当前节点的偏移量永远是1,即使用了下图的存储方式
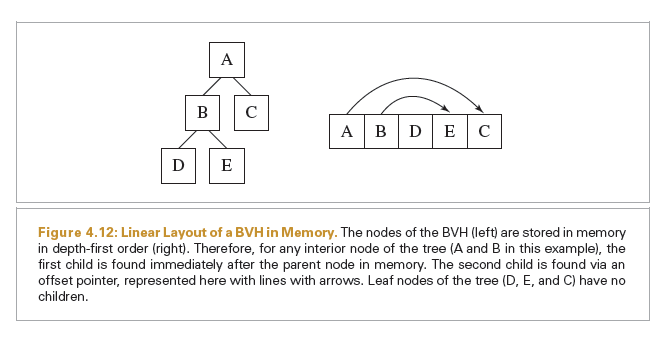
这里用一个连续的数组来存储BVH树。做好这些准备工作之后,开始调用subdivide函数执行BVH的递归划分过程:
int curTri = 0;
int curNode = 0;
subdivide(items, ntris, 0, ntris, trisPerChunk, curNode, cm->nodes, nchunks*4, curTri, cm->tris, tris);
delete [] items;
cm->nnodes = curNode; //存储最终使用了多少个节点
这个函数的签名如下:
static void subdivide(BoundsItem* items, int nitems, int imin, int imax, int trisPerChunk,
int& curNode, rcChunkyTriMeshNode* nodes, const int maxNodes,
int& curTri, int* outTris, const int* inTris)
这里需要讲解一下相关的参数定义:
items代表存储mesh中所有三角形包围盒的数组开始指针,递归时此参数不变nitems代表mesh中三角形的个数,递归时此参数不变imin代表当前节点要处理的三角形的开始索引imax代表当前节点要处理的三角形的结束索引trisPerChunk代表叶子节点里存储的三角形最大个数,递归时此参数不变curNode,代表当前的BVH节点的索引,每次执行subdivide之后这个值都会递增,这样就做到了一个节点内的所有子节点都是连续分配的nodes代表BVH节点的存储数组,递归时此参数不变maxNodes代表nodes里最大可用索引,递归时此参数不变curTri代表下一个可以使用的存储三角形顶点序列数组的索引outTris代表存储三角形顶点序列的数组开始地址,递归时此参数不变inTris代表最开始mesh中三角形的存储数组开始地址
了解这些参数的定义之后,我们才能更好的理解递归划分的流程。首先记录当前需要处理的节点索引以及三角形的数量:
int inum = imax - imin; // 当前节点内三角形的个数
int icur = curNode; // 当前节点的索引
rcChunkyTriMeshNode& node = nodes[curNode++];
然后判断剩余三角形的个数是否小于等于了trisPerChunk,此时不再执行递归划分:
if (inum <= trisPerChunk)
{
// 计算当前nodes aabb 包围盒大小
calcExtends(items, nitems, imin, imax, node.bmin, node.bmax);
// 将对应的三角形数据复制到outTris中
node.i = curTri;
node.n = inum;
for (int i = imin; i < imax; ++i)
{
const int* src = &inTris[items[i].i*3];
int* dst = &outTris[curTri*3];
curTri++; // 注意这里每次复制一个三角形,这里的索引都需要递增
dst[0] = src[0];
dst[1] = src[1];
dst[2] = src[2];
}
}
面对递归处理的情况,需要选择是从X轴还是从Z轴进行分裂,这里选用一个最简单的方法,计算AABB包围盒之后,使用包围盒长度最长的轴进行分裂:
// Split
calcExtends(items, nitems, imin, imax, node.bmin, node.bmax);
int axis = longestAxis(node.bmax[0] - node.bmin[0],
node.bmax[1] - node.bmin[1]);
if (axis == 0)
{
// Sort along x-axis
qsort(items+imin, static_cast<size_t>(inum), sizeof(BoundsItem), compareItemX);
}
else if (axis == 1)
{
// Sort along y-axis
qsort(items+imin, static_cast<size_t>(inum), sizeof(BoundsItem), compareItemY);
}
这里使用了一个快速排序,将[items+imin, items+imax)区间内的数据进行了按照对应的坐标轴数组进行排序。排完序之后,使用中点的索引进行切分为两组连续的三角形,执行递归调用:
int isplit = imin+inum/2; // 中点的索引
// Left
subdivide(items, nitems, imin, isplit, trisPerChunk, curNode, nodes, maxNodes, curTri, outTris, inTris);
// Right
subdivide(items, nitems, isplit, imax, trisPerChunk, curNode, nodes, maxNodes, curTri, outTris, inTris);
注意这里是先执行左子节点[imin, isplit)的subdivide,然后再执行右子节点[isplit, imax)的subdivide,因为只有这样才能保证左子节点的索引为父节点的索引加1。两个子节点都划分好了之后,curNode里存储的就是下一个可以使用的节点索引,减去当前节点的索引我们就可以得到当前节点的所有子节点的个数:
int iescape = curNode - icur;
// 这里用负数来存 用来跟叶子节点区分开
node.i = -iescape;
至此一个基于数组连续存储的BVH递归划分结束。这个BVH主要是用来支持raycast操作,即查询一条线段与Mesh的相交点,最典型的应用就是查询当前点在Mesh上的投影位置。期间会有一个初步筛选的工作来获取所有与这个线段相交的BVH节点:
int rcGetChunksOverlappingSegment(const rcChunkyTriMesh* cm,
float p[2], float q[2],
int* ids, const int maxIds)
{
// Traverse tree
int i = 0;
int n = 0;
while (i < cm->nnodes)
{
const rcChunkyTriMeshNode* node = &cm->nodes[i];
const bool overlap = checkOverlapSegment(p, q, node->bmin, node->bmax);
const bool isLeafNode = node->i >= 0;
if (isLeafNode && overlap)
{
if (n < maxIds)
{
ids[n] = i;
n++;
}
}
if (overlap || isLeafNode)
i++;
else
{
const int escapeIndex = -node->i;
i += escapeIndex;
}
}
return n;
}
初始的时候使用将要处理的节点设置为根节点,然后每次对当前要处理的节点进行如下操作:
- 计算当前节点的
AABB包围盒是否与线段相交 - 如果当前节点是叶子节点且相交 则将这个节点记录到结果中
- 如果当前节点的包围盒与线段相交或者当前节点是叶子节点,则将节点索引加
1,进行下一步处理 - 如果包围盒不相交且不是叶子节点,则跳过当前节点的所有子节点,因为这些子节点一定不会再与线段相交
上面的步骤3中的加1操作其实就是获取二叉树先序遍历树时当前节点的后继,这里对应了三种情况:
- 当前节点是非叶子节点,先序遍历的后继就是当前节点的左子节点,
- 当前节点是叶子节点,且是父节点的左子节点,先序遍历的后继就是当前父节点的右子节点,
- 当前节点是叶子节点,且是父节点的右子节点,先序遍历的后继则需要递归找到其父节点链条中第一个作为左子节点存在的点,然后获取这个节点的兄弟节点
之前我们构造BVH树分配节点索引的规则刚好满足这三种情况下的后继节点的索引都只需要加1即可获得。有了这个函数之后,真正的raycast函数执行的逻辑就比较简单了:
bool InputGeom::raycastMesh(float* src, float* dst, float& tmin)
{
// Prune hit ray.
float btmin, btmax;
if (!isectSegAABB(src, dst, m_meshBMin, m_meshBMax, btmin, btmax))
return false;
float p[2], q[2];
p[0] = src[0] + (dst[0]-src[0])*btmin;
p[1] = src[2] + (dst[2]-src[2])*btmin;
q[0] = src[0] + (dst[0]-src[0])*btmax;
q[1] = src[2] + (dst[2]-src[2])*btmax;
int cid[512];
const int ncid = rcGetChunksOverlappingSegment(m_chunkyMesh, p, q, cid, 512);
if (!ncid)
return false;
tmin = 1.0f;
bool hit = false;
const float* verts = m_mesh->getVerts();
for (int i = 0; i < ncid; ++i)
{
const rcChunkyTriMeshNode& node = m_chunkyMesh->nodes[cid[i]];
const int* tris = &m_chunkyMesh->tris[node.i*3];
const int ntris = node.n;
for (int j = 0; j < ntris*3; j += 3)
{
float t = 1;
if (intersectSegmentTriangle(src, dst,
&verts[tris[j]*3],
&verts[tris[j+1]*3],
&verts[tris[j+2]*3], t))
{
if (t < tmin)
tmin = t;
hit = true;
}
}
}
return hit;
}
不过由于我们前面建立的BVH只处理了XZ平面,所以后面还需要执行一个for循环使用intersectSegmentTriangle去过滤掉不相交的三角形。这个函数调用还可以计算出相交点相对于起点的长度,最终结果选取长度最小的那个交点,作为第一个相交点。其具体执行流程为先计算三角形平面的法线,然后计算起点到这个平面的投影点,利用投影点计算出射线与三角形平面的交点,判断这个交点是否在三角形内。
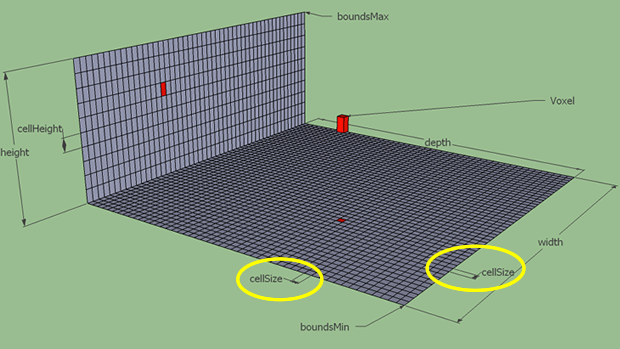
场景体素化
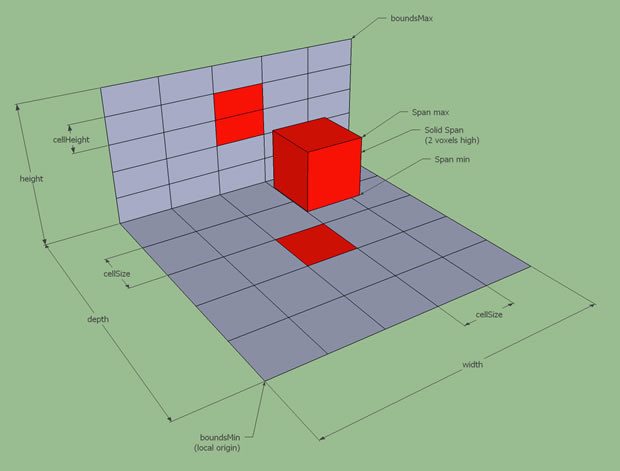
这里的体素化与前面章节里提到的体素化定义是一致的,不过前述章节中我们为了讨论方便,将体素设定为立方体的形状,在recast中放松了此设定,变成了一个底面为正方形的长方体:
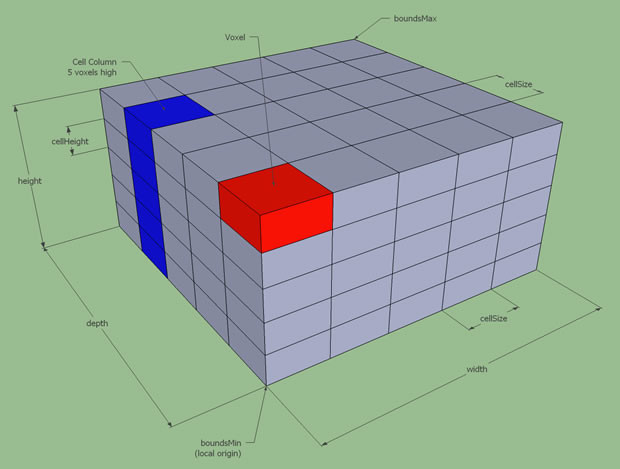
此时长方体有两个可配置项:
cellSize代表体素地面的正方形边长cellHeight代表体素的高度
cellSize使用较低的值使得生成的网格更接近源几何形状,下图中就是使用大cellSize时最后生成的网格:
将这个参数调整小之后,就能获取一个更贴近边界的网格:
cellSize不是越小越好,设定的太小则需要更高的处理和内存成本,因为存储空间大概与cellSize*cellSize的大小成反比:
至于cellHeight这个参数,较小的值使得最终的网格更贴近几何形状的表面:
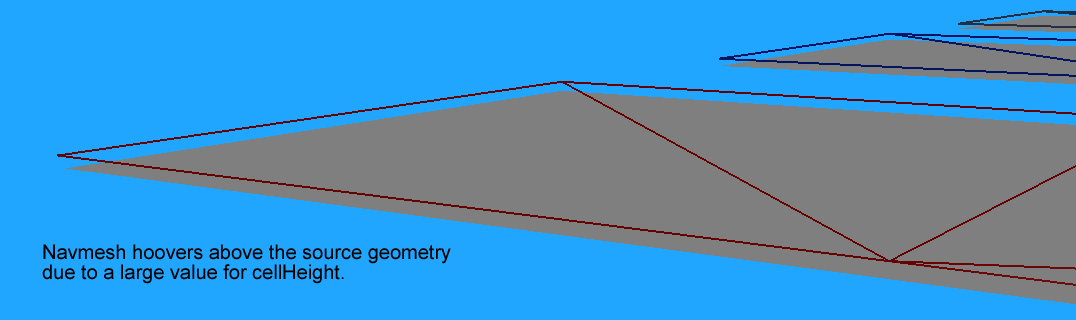
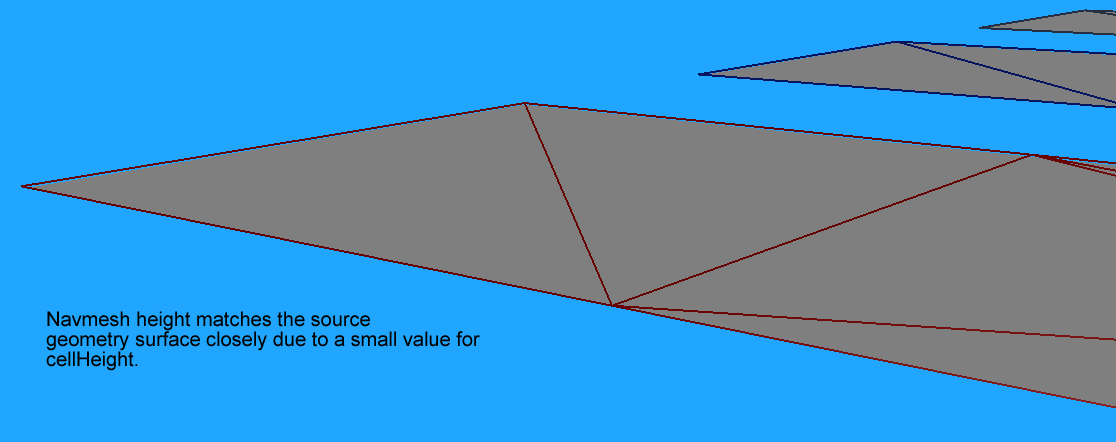
这个参数的设置会影响后续流程中所需要处理的多个参数,walkableHeight、walkableClimb 和 detailSampleMaxError需要大于这个值才能正常工作,所以经验值为walkableHeight、walkableClimb、cellSize,detailSampleMaxError的最小值的三分之一。
不过与cellSize不同的地方在于,使用较低的cellHeight值虽然同样会增加处理的耗时,但是不会显著增加内存使用,因为我们在存储每一列数据的时候使用了span这样的结构去优化。不过这里使用的span记录的是连续的实心阻挡区域,而前面章节的span记录的是连续的空心非阻挡区域。
对应的结构体声明与我们之前定义的span类似:
/// Defines the number of bits allocated to rcSpan::smin and rcSpan::smax.
static const int RC_SPAN_HEIGHT_BITS = 13;
/// Defines the maximum value for rcSpan::smin and rcSpan::smax.
static const int RC_SPAN_MAX_HEIGHT = (1 << RC_SPAN_HEIGHT_BITS) - 1;
/// Represents a span in a heightfield.
/// @see rcHeightfield
struct rcSpan
{
unsigned int smin : RC_SPAN_HEIGHT_BITS; ///< The lower limit of the span. [Limit: < #smax]
unsigned int smax : RC_SPAN_HEIGHT_BITS; ///< The upper limit of the span. [Limit: <= #RC_SPAN_MAX_HEIGHT]
unsigned int area : 6; ///< The area id assigned to the span.
rcSpan* next; ///< The next span higher up in column.
};
不过这里为了省内存,使用了13个bit来存储以cellHeight来计算的高度,在cellHeight设置为10cm时,支持的场景最大高度为800M。rcSpan中还有一个area字段来做span的区域标记,默认情况下来标记这个span的上表面是否可以行走。
有了这个rcSpan之后,对应的实心高度场结构体定义如下:
/// The number of spans allocated per span spool.
/// @see rcSpanPool
static const int RC_SPANS_PER_POOL = 2048;
/// A memory pool used for quick allocation of spans within a heightfield.
/// @see rcHeightfield
struct rcSpanPool
{
rcSpanPool* next; ///< The next span pool.
rcSpan items[RC_SPANS_PER_POOL]; ///< Array of spans in the pool.
};
/// A dynamic heightfield representing obstructed space.
/// @ingroup recast
struct rcHeightfield
{
int width; ///< The width of the heightfield. (Along the x-axis in cell units.)
int height; ///< The height of the heightfield. (Along the z-axis in cell units.)
float bmin[3]; ///< The minimum bounds in world space. [(x, y, z)]
float bmax[3]; ///< The maximum bounds in world space. [(x, y, z)]
float cs; ///< The size of each cell. (On the xz-plane.)
float ch; ///< The height of each cell. (The minimum increment along the y-axis.)
rcSpan** spans; ///< Heightfield of spans (width*height).
rcSpanPool* pools; ///< Linked list of span pools.
rcSpan* freelist; ///< The next free span.
};
这里的spans就是一个行优先的二维数组,数组里每个rcSpan都是由rcSpanPool来进行分配的。采用Pool分配的好处就是避免频繁的调用malloc,直接走批量分配。而且由于所有的rcSpan的生命周期都是与rcHeightfield一致的,所以也不需要考虑单个rcSpan的free操作了,直接挂靠到freelist的开头即可。
static rcSpan* allocSpan(rcHeightfield& hf)
{
// If running out of memory, allocate new page and update the freelist.
if (!hf.freelist || !hf.freelist->next)
{
// Create new page.
// Allocate memory for the new pool.
rcSpanPool* pool = (rcSpanPool*)rcAlloc(sizeof(rcSpanPool), RC_ALLOC_PERM);
if (!pool) return 0;
// Add the pool into the list of pools.
pool->next = hf.pools;
hf.pools = pool;
// Add new items to the free list.
rcSpan* freelist = hf.freelist;
rcSpan* head = &pool->items[0];
rcSpan* it = &pool->items[RC_SPANS_PER_POOL];
do
{
--it;
it->next = freelist;
freelist = it;
}
while (it != head);
hf.freelist = it;
}
// Pop item from in front of the free list.
rcSpan* it = hf.freelist;
hf.freelist = hf.freelist->next;
return it;
}
static void freeSpan(rcHeightfield& hf, rcSpan* ptr)
{
if (!ptr) return;
// Add the node in front of the free list.
ptr->next = hf.freelist;
hf.freelist = ptr;
}
最后构造出来的实心高度场结构可视化如下图:
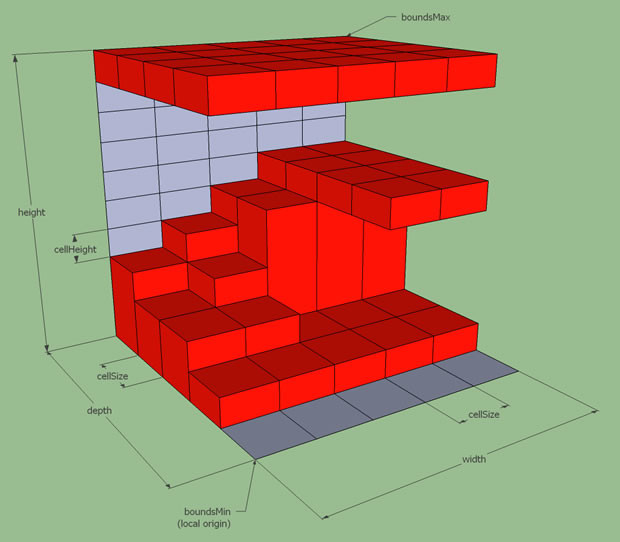
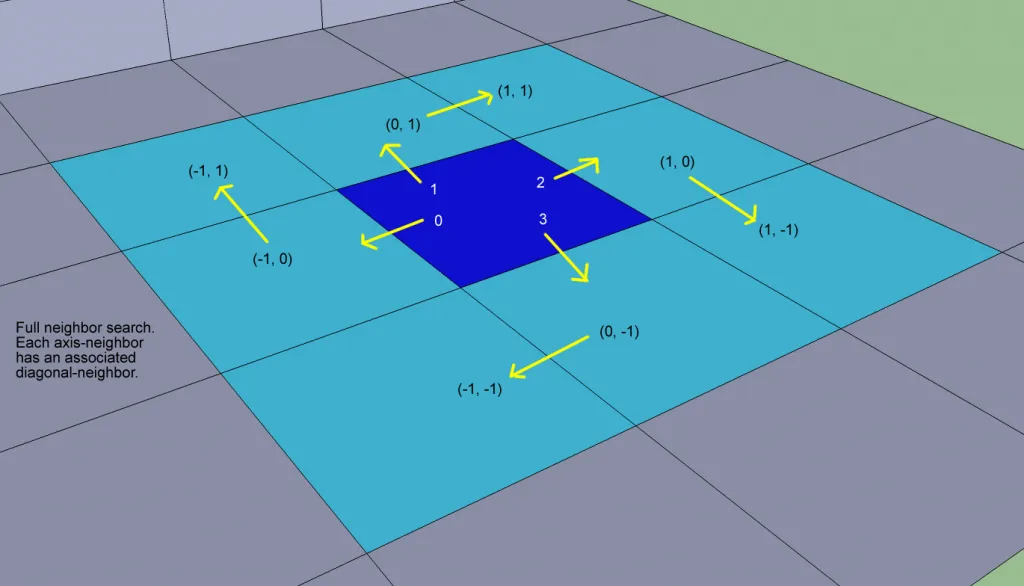
由于后续操作中经常需要执行搜索特定rcSpan的周围的邻居rcSpan的操作,这里的邻居rcSpan要满足两个需求:
- 投影在
XZ平面的网格与当前rcSpan网格相邻,即下图中的浅蓝色的8个格子
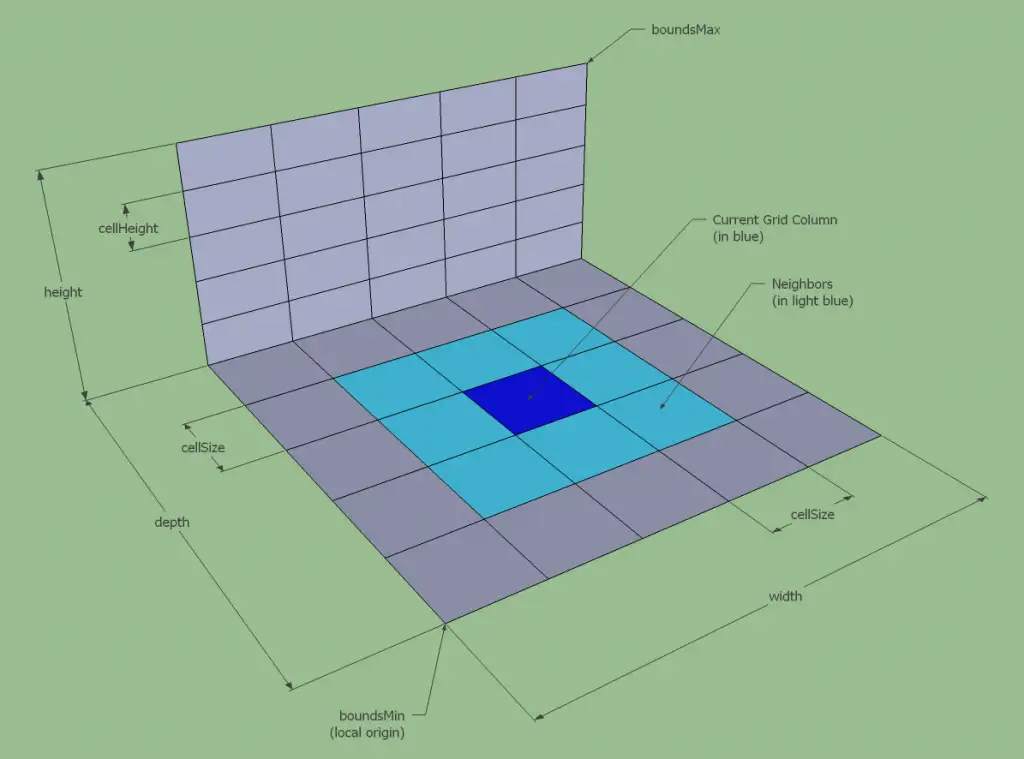
- 高度很接近
所以最终在高度场中一个rcspan的邻居rcspan如下:
有了存储所有体素数据的高度场结构定义之后,我们开始将输入Mesh里的所有三角形进行体素化,生成一个一个的体素并将相邻的体素合并为rcspan。
每个三角形都使用保守体素化的方式进行体素化并添加到高度场中。保守体素化是一种确保多边形表面完全被生成的体素包围的算法。下面是使用保守体素化包围三角形的一个例子:

对应的体素化实现函数声明如下:
static bool rasterizeTri(const float* v0, const float* v1, const float* v2,
const unsigned char area, rcHeightfield& hf,
const float* bmin, const float* bmax,
const float cs, const float ics, const float ich,
const int flagMergeThr)
这个函数包含了两重循环:
-
最外层循环是遍历这个三角形在
Z轴上的以cellSize计量的[z_begin, z_end)中的z,计算经过(0,0,z)的XY平面与三角形的相交区域生成的位于此平面左侧的凸多边形A,同时将右侧的三角形替换原始三角形 -
第二层循环则遍历这个
A的AABB在X轴投影[x_begin, x_end)中的x,计算经过(x,0,0)的YZ平面与A的相交区域生成的位于此平面左侧凸多边形B,计算B在Y轴以CellHeight计量的坐标[y_begin, y_end),构造对应的rcSpan,添加到高度场(x,z)对应的列的头部,同时将右侧的多边形替换原始的A
这里两层循环的执行都依赖于获取一个多边形与特定坐标轴垂直平面相交切分为两个凸多边形的计算,对应的函数声明定义如下:
// divides a convex polygons into two convex polygons on both sides of a line
static void dividePoly(const float* in, int nin,
float* out1, int* nout1,
float* out2, int* nout2,
float x, int axis)
这里的(in, nin)代表输入的多边形的坐标数组,axis代表对应的坐标轴索引,取值范围为0,1,2分别对应x,y,z三个轴,而 x则代表裁剪平面在此轴上的取值,out1,nout1和out2,nout2分别代表两个输出结果多边形的顶点列表,out1存储在对应坐标轴投影值都大于x值的多边形,out2则存储在对应坐标轴上投影值都小于x的多边形。了解了上述参数定义之后,我们再来看函数体:
float d[12]; // 存储原来的多边形的每个顶点与分割轴平面的距离
for (int i = 0; i < nin; ++i)
d[i] = x - in[i*3+axis];
int m = 0, n = 0;
for (int i = 0, j = nin-1; i < nin; j=i, ++i)
{
bool ina = d[j] >= 0;
bool inb = d[i] >= 0;
if (ina != inb) // 如果当前点与前一个点分属于 分割平面的两侧
{
float s = d[j] / (d[j] - d[i]); // 计算(i,j)两点之间的直线与分割平面相交的点的坐标
out1[m*3+0] = in[j*3+0] + (in[i*3+0] - in[j*3+0])*s;
out1[m*3+1] = in[j*3+1] + (in[i*3+1] - in[j*3+1])*s;
out1[m*3+2] = in[j*3+2] + (in[i*3+2] - in[j*3+2])*s;
rcVcopy(out2 + n*3, out1 + m*3);
// 分割点需要同时存入左右两个多边形的顶点列表中
m++;
n++;
// add the i'th point to the right polygon. Do NOT add points that are on the dividing line
// since these were already added above
if (d[i] > 0)
{
// 如果当前点在投影轴上的值大于x 则也加入到out1对应的多边形中
rcVcopy(out1 + m*3, in + i*3);
m++;
}
else if (d[i] < 0)
{
// 如果当前点在投影轴上的值小于x 则也加入到out2对应的多边形中
rcVcopy(out2 + n*3, in + i*3);
n++;
}
}
else // 如果都在平面的同一侧 则根据与x的差值计算是否加入到out1还是out2
{
// add the i'th point to the right polygon. Addition is done even for points on the dividing line
if (d[i] >= 0)
{
rcVcopy(out1 + m*3, in + i*3);
m++;
if (d[i] != 0) // 注意这里 如果当前点落在了分割平面上 则则个点会同时加入到两个多边形中
continue;
}
rcVcopy(out2 + n*3, in + i*3);
n++;
}
}
*nout1 = m;
*nout2 = n;

至此场景Mesh体素化的流程走完,高度场中已经拥有了基本的体素span信息,接下来我们需要对span的上表面计算是否可以行走,并更新area字段。这里是否可以行走的判定主要是通过判断这个体素来源的三角形的倾斜角度是否小于配置的参数walkableSlopeAngle,倾斜角小于这个值则代表可以行走,大于这个值则代表不可以行走:

对应的判定函数为rcMarkWalkableTriangles,其函数体比较简单,纯粹的几何向量运算:
/// The default area id used to indicate a walkable polygon.
/// This is also the maximum allowed area id, and the only non-null area id
/// recognized by some steps in the build process.
static const unsigned char RC_WALKABLE_AREA = 63;
void rcMarkWalkableTriangles(rcContext* ctx, const float walkableSlopeAngle,
const float* verts, int nv,
const int* tris, int nt,
unsigned char* areas)
{
rcIgnoreUnused(ctx);
rcIgnoreUnused(nv);
// 计算对应倾斜角度单位向量在x轴的投影值
const float walkableThr = std::cos(walkableSlopeAngle/180.0f*RC_PI);
float norm[3];
for (int i = 0; i < nt; ++i)
{
const int* tri = &tris[i*3];
// 计算这个三角形的单位法线向量 使用叉积计算法线方向然后单位化即可
calcTriNormal(&verts[tri[0]*3], &verts[tri[1]*3], &verts[tri[2]*3], norm);
// 这里的norm[1]就是与Y轴的投影值 如果投影值大于夹角的cos 则代表这个三角形与XZ平面的夹角小于 walkableSlopeAngle 可以行走
if (norm[1] > walkableThr)
areas[i] = RC_WALKABLE_AREA;
}
}
这里计算出来的area负责标记一个三角形体素化添加的所有rcSpan,但是由于多个三角形构造的rcSpan可能重叠,在执行rcSpan的合并时也要对area标记进行合并。两个rcSpan进行合并时,其对应的area标记更新规则如下:
-
如果两者的顶部高度相差小于爬升高度
walkableClimb则执行两个rcspan::area的最大值来更新 -
否则选取顶部最高的
rcSpan的area来更新
筛选可行走表面
rcSpan里的area标记了当前rcSpan是否是可以行走的,判定条件就是三角形的坡度小于walkableSlopeAngle。但是这个只是一个初步的筛选,通过了这个筛选也有可能是不可行走的,例如单独的悬空低坡度小三角形。一个rcSpan的顶部是否可以行走还需要做一些额外的后处理判定,来过滤掉一些特殊情况。这里的特殊情况主要包括如下三种:
-
筛选低垂的可行走障碍 对应的函数为
rcFilterLowHangingWalkableObstacles -
过滤跳台区间 对应的函数为
rcFilterLedgeSpans -
过滤可行走的低高度区间 对应的函数为
rcFilterWalkableLowHeightSpans
//
// Step 3. Filter walkables surfaces.
//
// Once all geoemtry is rasterized, we do initial pass of filtering to
// remove unwanted overhangs caused by the conservative rasterization
// as well as filter spans where the character cannot possibly stand.
if (m_filterLowHangingObstacles)
rcFilterLowHangingWalkableObstacles(m_ctx, m_cfg.walkableClimb, *m_solid);
if (m_filterLedgeSpans)
rcFilterLedgeSpans(m_ctx, m_cfg.walkableHeight, m_cfg.walkableClimb, *m_solid);
if (m_filterWalkableLowHeightSpans)
rcFilterWalkableLowHeightSpans(m_ctx, m_cfg.walkableHeight, *m_solid);
这三种过滤方式都可以通过配置参数来开启,下面我们来分别介绍这三个过滤规则的细节与目的。
筛选低垂的可行走障碍
这个筛选的目的是将一些小的障碍物标记为可行走:如果某个不可行走的rcSpan同一列中有一个高度差不超过爬坡高度的可行走rcSpan,则此rcSpan标记为可以行走.
算法比较简单:迭代每一列,从下往上遍历rcSpan,对于同列任意两个相邻的span1(下)和span2(上),当span1可走,并且span2不可走的时候,计算这两个span的上表面高度差Diff,如果Diff小于配置参数walkableClimb,则将span2设置为可行走:
void rcFilterLowHangingWalkableObstacles(rcContext* ctx, const int walkableClimb, rcHeightfield& solid)
{
rcAssert(ctx);
rcScopedTimer timer(ctx, RC_TIMER_FILTER_LOW_OBSTACLES);
const int w = solid.width;
const int h = solid.height;
for (int y = 0; y < h; ++y)
{
for (int x = 0; x < w; ++x)
{
rcSpan* ps = 0;
bool previousWalkable = false;
unsigned char previousArea = RC_NULL_AREA;
for (rcSpan* s = solid.spans[x + y*w]; s; ps = s, s = s->next)
{
const bool walkable = s->area != RC_NULL_AREA;
// If current span is not walkable, but there is walkable
// span just below it, mark the span above it walkable too.
if (!walkable && previousWalkable)
{
if (rcAbs((int)s->smax - (int)ps->smax) <= walkableClimb)
s->area = previousArea;
}
// Copy walkable flag so that it cannot propagate
// past multiple non-walkable objects.
previousWalkable = walkable;
previousArea = s->area;
}
}
}
}
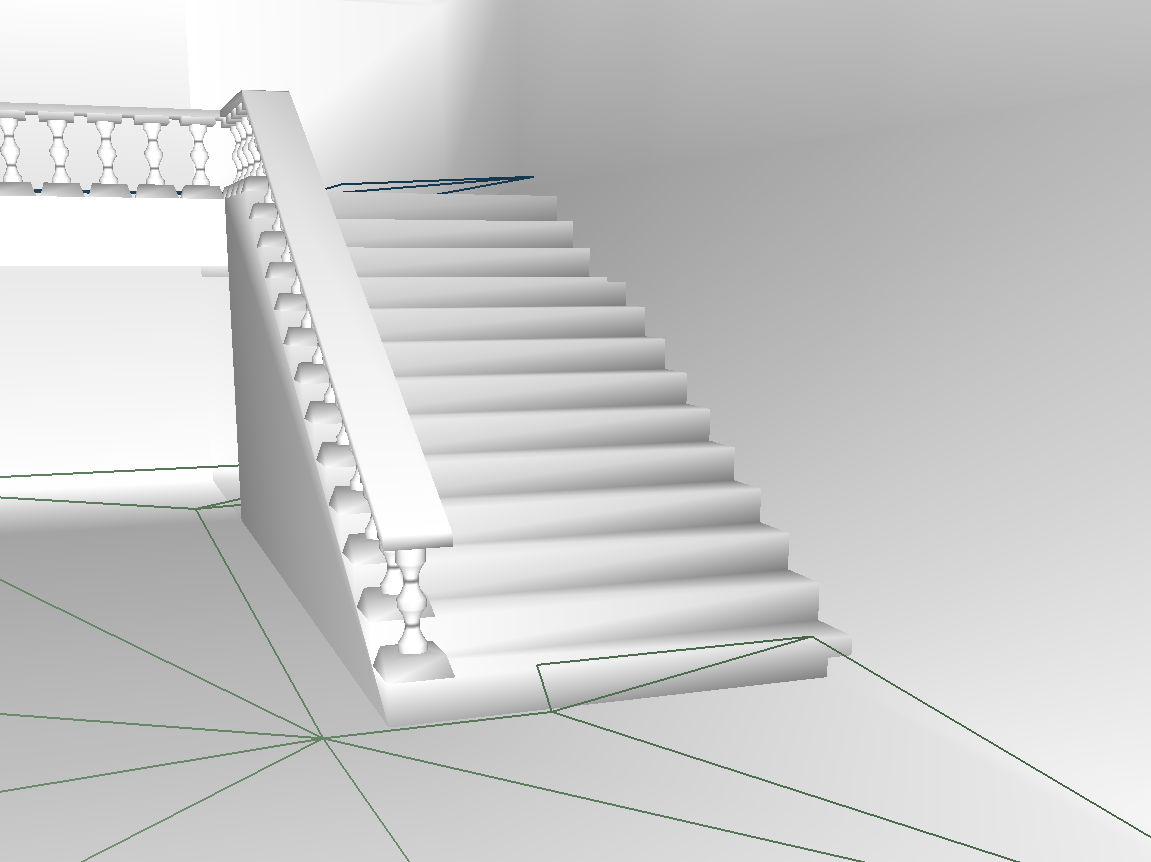
这部分主要是将一些楼梯台阶形式的行走表面连通起来:

如果这个参数设置的太小,则导致楼梯无法连通:
如果这个参数设置的太高,会导致桌子甚至房顶都可以直接从地面寻路过去:

过滤可行走的低高度区间
在使用Detour进行寻路时,参与寻路的Agent会有一个身高参数walkableHeight。如果在可行走的span(A)上方的障碍物底面与当前span(A)的顶面高度差小于这个指定的walkableHeight,那么span(A)的顶面则是不可行走的。

对应的实现也很简单:
void rcFilterWalkableLowHeightSpans(rcContext* ctx, int walkableHeight, rcHeightfield& solid)
{
rcAssert(ctx);
rcScopedTimer timer(ctx, RC_TIMER_FILTER_WALKABLE);
const int w = solid.width;
const int h = solid.height;
const int MAX_HEIGHT = 0xffff;
// Remove walkable flag from spans which do not have enough
// space above them for the agent to stand there.
for (int y = 0; y < h; ++y)
{
for (int x = 0; x < w; ++x)
{
for (rcSpan* s = solid.spans[x + y*w]; s; s = s->next)
{
const int bot = (int)(s->smax);
const int top = s->next ? (int)(s->next->smin) : MAX_HEIGHT;
if ((top - bot) <= walkableHeight)
s->area = RC_NULL_AREA;
}
}
}
}
这个参数也需要设置为合适的值去匹配参与寻路的entity的高度,下图就是选取了合适的参数之后,桌子下面的区域不再可通行:
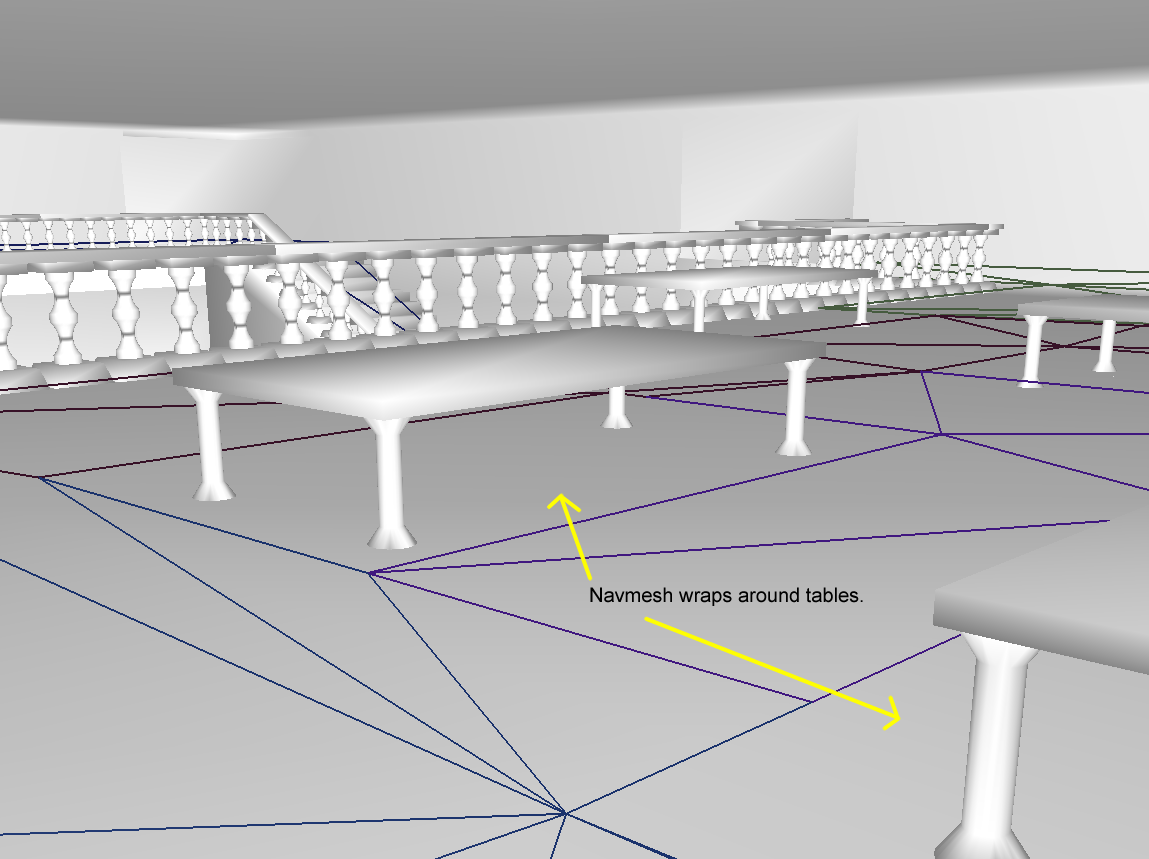
如果这个参数设置的过小,则桌子下面的区域会变得可通行,如果真实高度大于桌子高度但是又是可通行的,则会引起模型与场景的穿插:
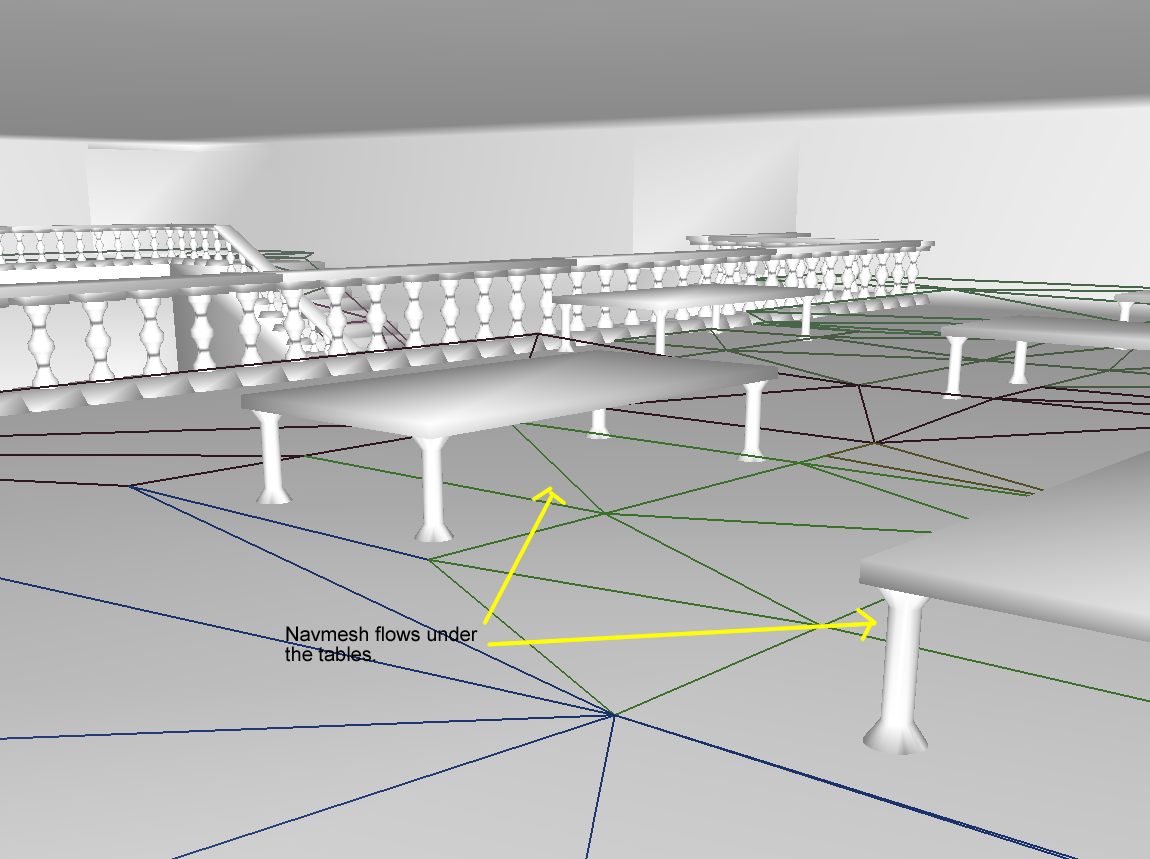
当然太大也不行,会导致下图中天花板下方的区域都不可通行:
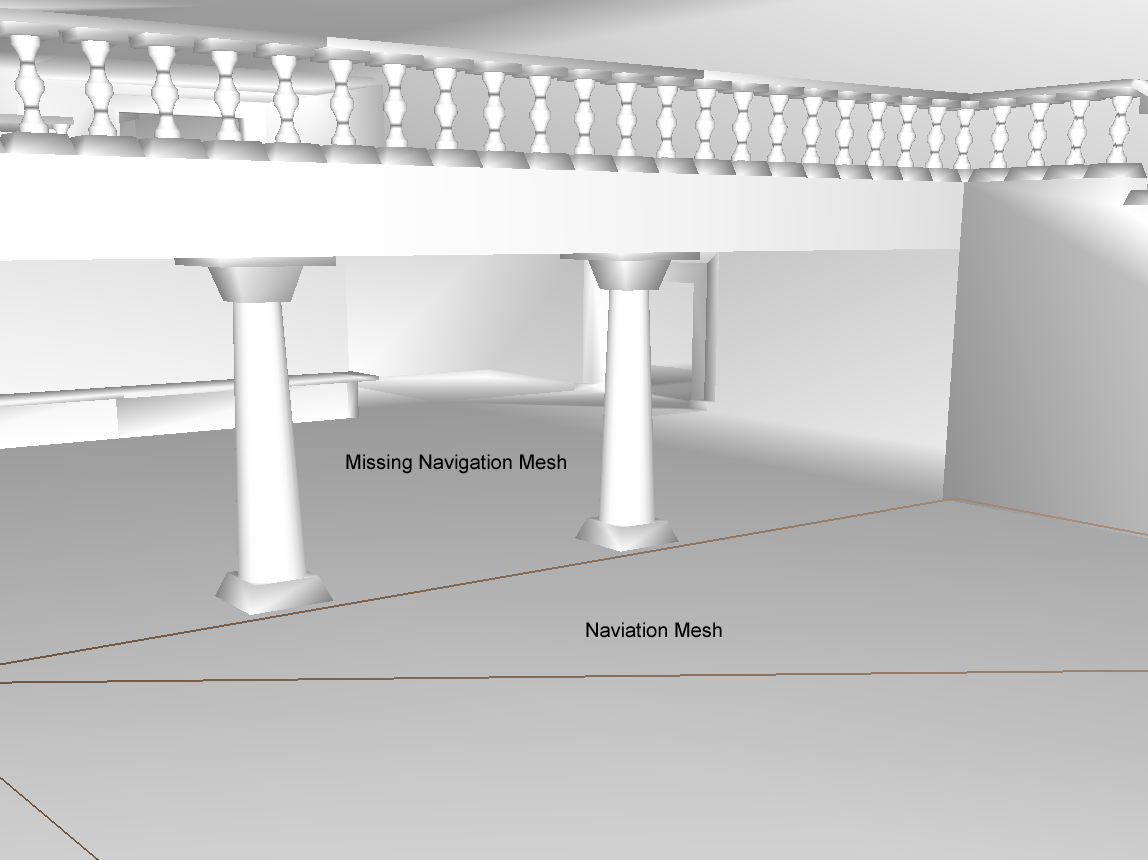
过滤跳台区间
这个步骤负责将处理跨列移动时的规则过滤,避免出现高度下降过快的情况。这里的跨列移动就是从一个可行走span(A)移动到可行走的归属于其他列的span(B),这样的移动需要满足如下条件:
-
span(B)所在的列是span(A)所在列的四个轴向邻居之一 -
Span(B)的顶面高度减去span(A)的顶面高度要小于攀爬高度walkableClimb -
span(A)移动到Span(B)时不会触发walkableHeight高度限制引发的阻挡,此时我们需要获得span(A)上面邻居span(A2)以及span(B)的上面邻居span(B2),计算A2, B2的底面最小值减去A, B的顶面最大值就是从A移动到B的最大允许高度,要求这个值要大于walkableHeight
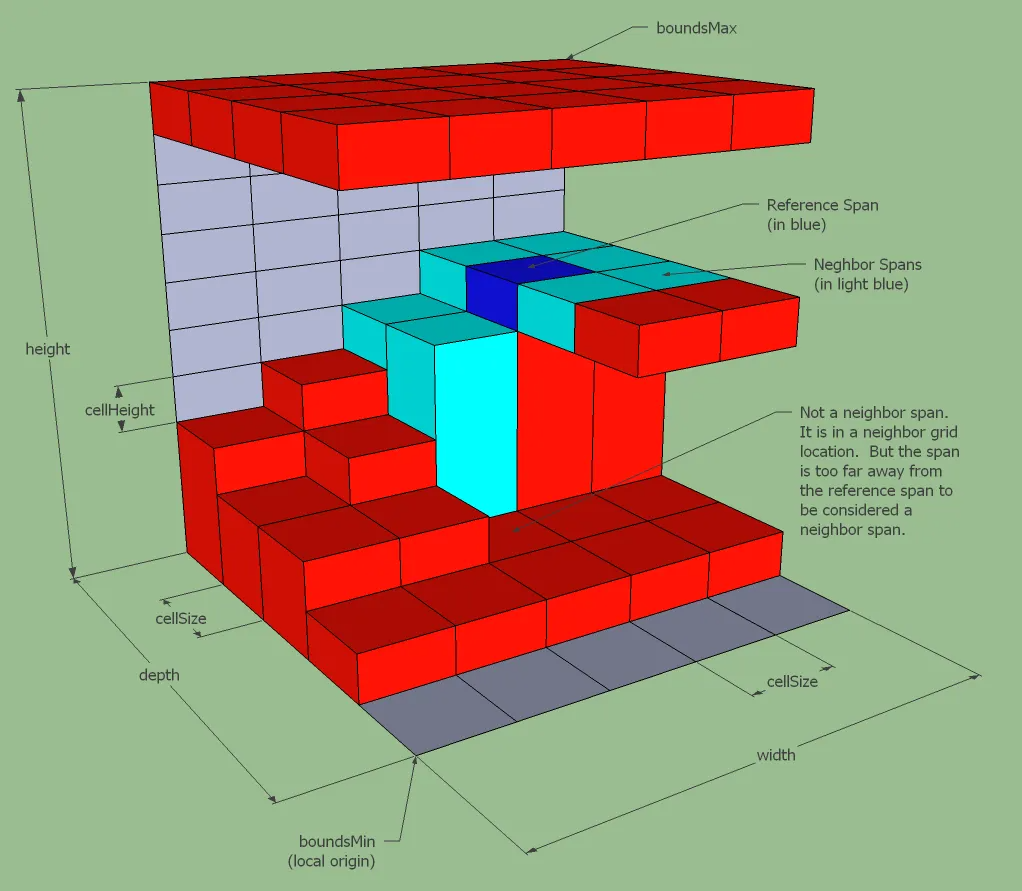
满足上述条件的span(B)被定义为Span(A)的一个跨列邻居。下图中的浅蓝色span就是当前蓝色span的跨列邻居:
有了跨列邻居之后我们再来定义跳台区间:对于一个span(A)而言,遍历其周围四个轴邻居,对于每个轴邻居获取其中上表面低于当前span(A)上表面高度的跨列邻居span(B)中高度最高者,计算这几个span(B)与span(A)上表面高度差的最小值,如果这个最小值大于指定参数walkableClimb,则当前span(A)为跳台区间。如果span(A)对应的列在场景边界上或者在某个方向的邻居列中没有跨列邻居,则也定义为跳台区间。我们需要将所有为跳台区间的rcSpan标记为不可行走:

在上图中蓝色的span就是所谓的跳台区间,红色的span则是正常区间。这个过滤函数需要处理每一个可行走的rcspan的四个方向邻居列的每个有效跨列移动,因此会出现五重循环:
/// @see rcHeightfield, rcConfig
void rcFilterLedgeSpans(rcContext* ctx, const int walkableHeight, const int walkableClimb,
rcHeightfield& solid)
{
rcAssert(ctx);
rcScopedTimer timer(ctx, RC_TIMER_FILTER_BORDER);
const int w = solid.width;
const int h = solid.height;
const int MAX_HEIGHT = 0xffff;
// Mark border spans.
for (int y = 0; y < h; ++y)
{
for (int x = 0; x < w; ++x)
{
for (rcSpan* s = solid.spans[x + y*w]; s; s = s->next)
{
// Skip non walkable spans.
if (s->area == RC_NULL_AREA)
continue;
// 遍历每个原来可以行走的span
const int bot = (int)(s->smax);
const int top = s->next ? (int)(s->next->smin) : MAX_HEIGHT;
// 跨列邻居的最小高度
int minh = MAX_HEIGHT;
// Min and max height of accessible neighbours.
int asmin = s->smax;
int asmax = s->smax;
// 四方向邻居遍历
for (int dir = 0; dir < 4; ++dir)
{
int dx = x + rcGetDirOffsetX(dir);
int dy = y + rcGetDirOffsetY(dir);
// 超过边界时 不处理
if (dx < 0 || dy < 0 || dx >= w || dy >= h)
{
minh = rcMin(minh, -walkableClimb - bot);
continue;
}
// From minus infinity to the first span.
rcSpan* ns = solid.spans[dx + dy*w];
int nbot = -walkableClimb;
int ntop = ns ? (int)ns->smin : MAX_HEIGHT;
// 这里使用agent的高度过滤掉不可连通的邻居
if (rcMin(top,ntop) - rcMax(bot,nbot) > walkableHeight)
minh = rcMin(minh, nbot - bot);
// Rest of the spans.
for (ns = solid.spans[dx + dy*w]; ns; ns = ns->next)
{
nbot = (int)ns->smax;
ntop = ns->next ? (int)ns->next->smin : MAX_HEIGHT;
// 这里使用agent的高度过滤掉不可连通的邻居
if (rcMin(top,ntop) - rcMax(bot,nbot) > walkableHeight)
{
// 更新跨列邻居减去当前span顶面高度的最小值
minh = rcMin(minh, nbot - bot);
// 如果当前差值在爬升范围内 更新当前span可以上升的最大高度和最小高度
if (rcAbs(nbot - bot) <= walkableClimb)
{
if (nbot < asmin) asmin = nbot;
if (nbot > asmax) asmax = nbot;
}
}
}
}
// 如果存在一个跨列邻居使得从当前span下降到这个跨列邻居所需高度大于爬升高度 则设置为不可行走
if (minh < -walkableClimb)
{
s->area = RC_NULL_AREA;
}
// 如果当前span所能达到的最高高度与最低高度的差值大于爬升高度,则也标记为不可行走
else if ((asmax - asmin) > walkableClimb)
{
s->area = RC_NULL_AREA;
}
}
}
}
}
值得注意的是上面的过滤除了处理了当前span的下降高度之外,还处理了当前span的有效到达高度的最大值与最小值,如果这个区间长度大于爬升高度,则认为当前span会引发一个间接的快速下降过程,因此这种情况下也把当前span设置为了跳台span,标记为不可通行。
区域分割
这一阶段的目标是生成以体素表示的输入Mesh的可通过表面,并将可通过的区域分割成可以最终形成简单多边形的相邻的span(表面)区域。此时为了计算连通性,我们需要使用空心的rcCompactSpan来替代原来的rcSpan,
对应的高度场数据也从实心高度场数据rcHeightField转换到了空心压缩高度场数据rcCompactHeightField。
/// Provides information on the content of a cell column in a compact heightfield.
struct rcCompactCell
{
unsigned int index : 24; ///< Index to the first span in the column.
unsigned int count : 8; ///< Number of spans in the column.
};
/// Represents a span of unobstructed space within a compact heightfield.
struct rcCompactSpan
{
unsigned short y; ///< The lower extent of the span. (Measured from the heightfield's base.)
unsigned short reg; ///< The id of the region the span belongs to. (Or zero if not in a region.)
unsigned int con : 24; ///< Packed neighbor connection data.
unsigned int h : 8; ///< The height of the span. (Measured from #y.)
};
/// A compact, static heightfield representing unobstructed space.
/// @ingroup recast
struct rcCompactHeightfield
{
rcCompactHeightfield();
~rcCompactHeightfield();
int width; ///< The width of the heightfield. (Along the x-axis in cell units.)
int height; ///< The height of the heightfield. (Along the z-axis in cell units.)
int spanCount; ///< The number of spans in the heightfield.
int walkableHeight; ///< The walkable height used during the build of the field. (See: rcConfig::walkableHeight)
int walkableClimb; ///< The walkable climb used during the build of the field. (See: rcConfig::walkableClimb)
int borderSize; ///< The AABB border size used during the build of the field. (See: rcConfig::borderSize)
unsigned short maxDistance; ///< The maximum distance value of any span within the field.
unsigned short maxRegions; ///< The maximum region id of any span within the field.
float bmin[3]; ///< The minimum bounds in world space. [(x, y, z)]
float bmax[3]; ///< The maximum bounds in world space. [(x, y, z)]
float cs; ///< The size of each cell. (On the xz-plane.)
float ch; ///< The height of each cell. (The minimum increment along the y-axis.)
rcCompactCell* cells; ///< Array of cells. [Size: #width*#height]
rcCompactSpan* spans; ///< Array of spans. [Size: #spanCount]
unsigned short* dist; ///< Array containing border distance data. [Size: #spanCount]
unsigned char* areas; ///< Array containing area id data. [Size: #spanCount]
};
在上面的结构体定义中,高度场二维平面里的每个cell都有一个rcCompactCell,总体以行优先的形式存储在cells中。然后每个cell内的rcCompactSpan是连续存储的,其存储区域在spans中,所以此时不再使用链表来关联了。rcCompactCell中的index代表其内部的第一个span的在spans里的开始索引,count字段代表当前cell有多少个span。每个rcCompactSpan里用y存储下表面高度,用h存储span的长度,con字段存储了当前span与周围四个邻居cell中相连接的第一个span的数据。
将原有的实心高度场数据rcHeightField转换到空心压缩高度场数据rcCompactHeightField的函数为rcBuildCompactHeightfield,其逻辑很简单。首先预先分配spans对应的内存大小,这部分可以通过rcGetHeightFieldSpanCount计算而来,然后遍历每个rcCompactCell,获取原来实心高度场里对应的rcSpan链表,链表里每个顶面可以行走的rcSpan都会生成一个rcCompactSpan:
const int MAX_HEIGHT = 0xffff;
// Fill in cells and spans.
int idx = 0;
for (int y = 0; y < h; ++y)
{
for (int x = 0; x < w; ++x)
{
const rcSpan* s = hf.spans[x + y*w];
// If there are no spans at this cell, just leave the data to index=0, count=0.
if (!s) continue;
rcCompactCell& c = chf.cells[x+y*w];
c.index = idx;
c.count = 0;
while (s)
{
if (s->area != RC_NULL_AREA)
{
const int bot = (int)s->smax;
const int top = s->next ? (int)s->next->smin : MAX_HEIGHT;
chf.spans[idx].y = (unsigned short)rcClamp(bot, 0, 0xffff);
chf.spans[idx].h = (unsigned char)rcClamp(top - bot, 0, 0xff);
chf.areas[idx] = s->area;
idx++;
c.count++;
}
s = s->next;
}
}
}
初始化了所有rcCompactSpan的区间和area数据之后,为了后续连通性计算方便,还需要计算周围邻居数据。这里的周围邻居只包括当前rcCompactCell的四个轴向移动的其他rcCompactCell,这里使用了[0,4)作为方向标识,这四个方向邻居以顺时针形式排列:
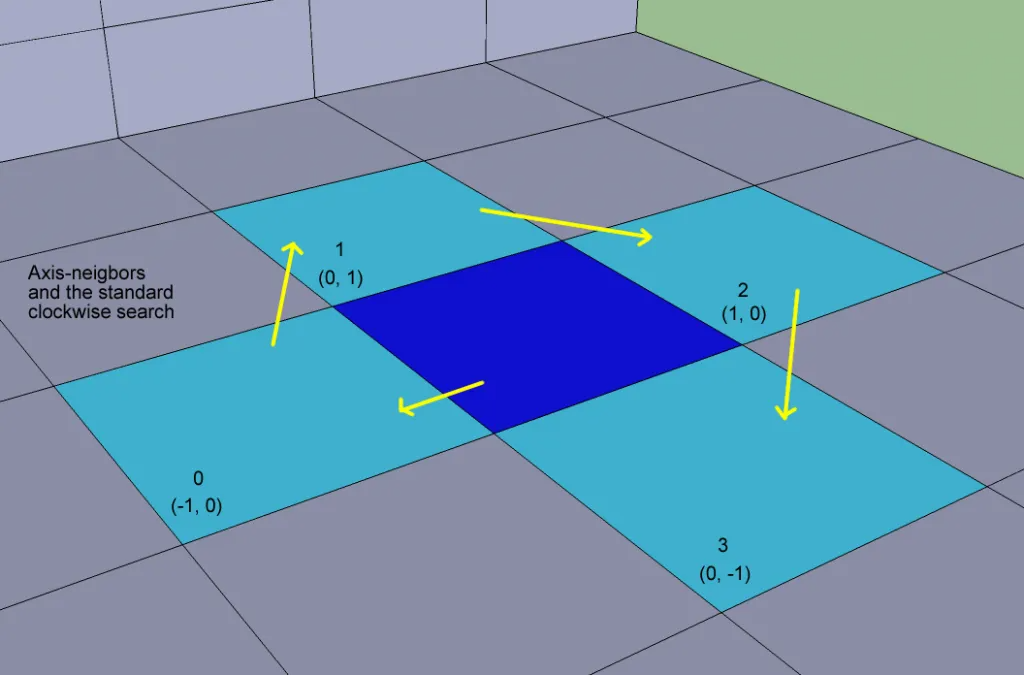
在后续的代码中,经常使用循环来遍历当前cell的邻居cell,为了避免分支判断,提供了下面的几个辅助函数来计算XZ方向上的偏移:
/// Gets the standard width (x-axis) offset for the specified direction.
/// @param[in] dir The direction. [Limits: 0 <= value < 4]
/// @return The width offset to apply to the current cell position to move
/// in the direction.
inline int rcGetDirOffsetX(int dir)
{
static const int offset[4] = { -1, 0, 1, 0, };
return offset[dir&0x03];
}
/// Gets the standard height (z-axis) offset for the specified direction.
/// @param[in] dir The direction. [Limits: 0 <= value < 4]
/// @return The height offset to apply to the current cell position to move
/// in the direction.
inline int rcGetDirOffsetY(int dir)
{
static const int offset[4] = { 0, 1, 0, -1 };
return offset[dir&0x03];
}
/// Gets the direction for the specified offset. One of x and y should be 0.
/// @param[in] x The x offset. [Limits: -1 <= value <= 1]
/// @param[in] y The y offset. [Limits: -1 <= value <= 1]
/// @return The direction that represents the offset.
inline int rcGetDirForOffset(int x, int y)
{
static const int dirs[5] = { 3, 0, -1, 2, 1 };
return dirs[((y+1)<<1)+x];
}
有了上述的邻居定义和辅助函数之后,计算当前rcCompactSpan的代码就简短了很多:
// Find neighbour connections.
const int MAX_LAYERS = RC_NOT_CONNECTED-1; //62
int tooHighNeighbour = 0;
for (int y = 0; y < h; ++y)
{
for (int x = 0; x < w; ++x)
{
const rcCompactCell& c = chf.cells[x+y*w];
for (int i = (int)c.index, ni = (int)(c.index+c.count); i < ni; ++i)
{
// 遍历当前cell里的所有span
rcCompactSpan& s = chf.spans[i];
for (int dir = 0; dir < 4; ++dir)
{
rcSetCon(s, dir, RC_NOT_CONNECTED);
const int nx = x + rcGetDirOffsetX(dir);
const int ny = y + rcGetDirOffsetY(dir);
// First check that the neighbour cell is in bounds.
if (nx < 0 || ny < 0 || nx >= w || ny >= h)
continue;
// 获取当前dir方向上的邻居cell
const rcCompactCell& nc = chf.cells[nx+ny*w];
for (int k = (int)nc.index, nk = (int)(nc.index+nc.count); k < nk; ++k)
{
const rcCompactSpan& ns = chf.spans[k];
const int bot = rcMax(s.y, ns.y);
const int top = rcMin(s.y+s.h, ns.y+ns.h);
// 遍历邻居cell里的所有空心span 获取一个跨列移动的邻居
// 两个span的高度差不能超过walkableClimb 且允许walkableHeight高度的单位进行通过
if ((top - bot) >= walkableHeight && rcAbs((int)ns.y - (int)s.y) <= walkableClimb)
{
const int lidx = k - (int)nc.index;
if (lidx < 0 || lidx > MAX_LAYERS)
{
tooHighNeighbour = rcMax(tooHighNeighbour, lidx);
continue;
}
// 记录当前方向上的跨列邻居 每一列都只记录一个
rcSetCon(s, dir, lidx);
break;
}
}
}
}
}
}
这里的rcSetCon实现的非常巧妙,尽可能的减少了数据的大小,每个方向的跨列邻居索引压缩为只使用6bit来存储,这样四个方向只需要24bit的空间即可,每次对特定方向的跨列邻居索引做get set的时候都通过位操作来进行:
/// Sets the neighbor connection data for the specified direction.
/// @param[in] s The span to update.
/// @param[in] dir The direction to set. [Limits: 0 <= value < 4]
/// @param[in] i The index of the neighbor span.
inline void rcSetCon(rcCompactSpan& s, int dir, int i)
{
const unsigned int shift = (unsigned int)dir*6;
unsigned int con = s.con;
s.con = (con & ~(0x3f << shift)) | (((unsigned int)i & 0x3f) << shift);
}
/// Gets neighbor connection data for the specified direction.
/// @param[in] s The span to check.
/// @param[in] dir The direction to check. [Limits: 0 <= value < 4]
/// @return The neighbor connection data for the specified direction,
/// or #RC_NOT_CONNECTED if there is no connection.
inline int rcGetCon(const rcCompactSpan& s, int dir)
{
const unsigned int shift = (unsigned int)dir*6;
return (s.con >> shift) & 0x3f;
}
为了省这部分内存带来的限制就是单rcCompactCell内只能有最多63个rcCompactSpan,因为63这个索引被定义为了不可通行。
搞定了压缩高度场的建立之后,下一步需要根据参数walkableRadius来把可通行区域的边缘过滤掉,这个参数的值一般设置为参与寻路的角色胶囊体半径。这个过滤的目的是为了避免寻路角色在区域边缘时出现异常,例如在悬崖边缘浮空或者与围墙穿插,所以要设置这个胶囊体半径的边缘为不可行走。
为了实现这个边缘特定范围过滤,我们需要给每个span赋予一个uint8 dis的值,代表这个span离边缘的距离。以下面的规则来初始化所有的span的dis:
-
如果这个
span不可行走,则设置为0 -
如果这个
span四个方向里存在至少一个列没有跨列邻居,则设置为0,此时需要检查rccompactSpan->con里四个方向的分量是否有等于63的 -
除此之外的
span的dis设置为255,即uint8的上限
然后执行洪泛(FloodFill)法来更新所有span的dis(A),这个更新规则如下:
-
遍历当前
span的四个轴向邻居,获取其中最小的dis(B),然后dis(A) = min(dis(A) , dis(B) + 2),这里使用2作为距离而不是1是因为使用的是最大可能距离而不是中心距离 -
遍历当前
span的四个对角线邻居,获取其中最小的dis(C),然后dis(A) = min(dis(A) , dis(C) + 3),这里使用3作为距离而不是2是因为使用的是最大可能距离而不是中心距离
这个简单的更新规则有个前置条件,即这个span九宫格周围八个span的距离已经更新好了,真要这么做就需要做一个排序。所以recast里使用了一个非常巧妙的方法,执行两次遍历:
- 第一次遍历从左下角
(0, 0)遍历到右上角(w,h),此时只计算当前span的cell偏移量为(-1, 0), (-1, -1),(0, -1), (1, -1)这四个邻居cell里的跨列邻居span,这四个span对应的cell要么在当前cell的正左边,要么在当前cell的下边,肯定在当前cell之前被当前遍历处理过了
for (int y = 0; y < h; ++y)
{
for (int x = 0; x < w; ++x)
{
// 遍历当前cell里的每个span 的(-1, 0), (-1, -1),(0, -1), (1, -1) 跨列邻居
}
}
这次遍历处理完成之后,span对应的dis值存储的就是当前span到正左边或者下边所有不可通行span距离的最小值
- 第二次遍历从右上角
(w,h)遍历到坐下角(0, 0),此时只计算当前span的cell偏移量为(1, 0), (-1, 1),(0, 1), (1, 1)这四个邻居cell里的跨列邻居span,这四个span对应的cell要么在当前cell的正右边,要么在当前cell的上边,肯定在当前cell之前被当前遍历处理过了
for (int y = h-1; y >= 0; --y)
{
for (int x = w-1; x >= 0; --x)
{
// 遍历当前cell里的每个span 的(1, 0), (-1, 1),(0, 1), (1, 1) 跨列邻居
}
}
这次遍历处理完成之后,span对应的dis值存储的就是当前span到所有有不可通行span距离的最小值
我们在span中只存储了四个轴的跨列邻居,那么是如何计算当前span的对角线邻居呢?其实调用两次获取轴向邻居就可以获得对角线邻居。这里以获取span(A)的(-1, -1)偏移量对角线邻居为例,先获取(-1, 0)方向的跨列邻居span(B),然后再获取span(B)在(0, -1)方向的跨列邻居span(C),这就是所需要的对角线邻居:
const rcCompactSpan& s = chf.spans[i];
if (rcGetCon(s, 0) != RC_NOT_CONNECTED)
{
// (-1,0)
const int ax = x + rcGetDirOffsetX(0);
const int ay = y + rcGetDirOffsetY(0);
const int ai = (int)chf.cells[ax+ay*w].index + rcGetCon(s, 0);
const rcCompactSpan& as = chf.spans[ai];
nd = (unsigned char)rcMin((int)dist[ai]+2, 255);
if (nd < dist[i])
dist[i] = nd;
// (-1,-1)
if (rcGetCon(as, 3) != RC_NOT_CONNECTED)
{
const int aax = ax + rcGetDirOffsetX(3);
const int aay = ay + rcGetDirOffsetY(3);
const int aai = (int)chf.cells[aax+aay*w].index + rcGetCon(as, 3);
nd = (unsigned char)rcMin((int)dist[aai]+3, 255);
if (nd < dist[i])
dist[i] = nd;
}
}
两轮过后,每个span参考了周围8个span的dis进行了dis更新,从而得到了正确的dis值。然后将所有dis小于两倍障碍半径的span设置为不可通行:
const unsigned char thr = (unsigned char)(radius*2);
for (int i = 0; i < chf.spanCount; ++i)
if (dist[i] < thr)
chf.areas[i] = RC_NULL_AREA;
做完了边界区域特定半径内禁止通行之后,recast还会调用rcMarkConvexPolyArea对场景中设置的area凸包围盒进行处理,这种包围盒的目的是将其内部的所有span下表面修改span::area字段,以方便后续的业务逻辑做处理。典型的应用场景为标记水体、沼泽地、公路等与平地不一样的区域。函数的执行体很简单,获取这个凸包围盒在XZ平面上的AABB包围盒之后,遍历在这个AABB内的所有cell,将底面中心点在此poly内的span设置对应的area。
for (int z = minz; z <= maxz; ++z)
{
for (int x = minx; x <= maxx; ++x)
{
const rcCompactCell& c = chf.cells[x+z*chf.width];
for (int i = (int)c.index, ni = (int)(c.index+c.count); i < ni; ++i)
{
rcCompactSpan& s = chf.spans[i];
if (chf.areas[i] == RC_NULL_AREA)
continue;
if ((int)s.y >= miny && (int)s.y <= maxy)
{
float p[3];
p[0] = chf.bmin[0] + (x+0.5f)*chf.cs;
p[1] = 0;
p[2] = chf.bmin[2] + (z+0.5f)*chf.cs;
if (pointInPoly(nverts, verts, p))
{
chf.areas[i] = areaId;
}
}
}
}
}
这一步做完之后最终到了使用压缩高度场数据生成区域的逻辑,不过这里的区域生成算法有三种,根据配置调用不同的函数来执行区域生成:
enum SamplePartitionType
{
SAMPLE_PARTITION_WATERSHED,
SAMPLE_PARTITION_MONOTONE,
SAMPLE_PARTITION_LAYERS,
};
-
SAMPLE_PARTITION_WATERSHED代表的是分水岭算法,其函数入口为rcBuildRegions -
SAMPLE_PARTITION_MONOTONE代表的是单调分区算法,其函数入口为rcBuildRegionsMonotone -
SAMPLE_PARTITION_LAYERS代表的是按层分区算法,其函数入口为rcBuildLayerRegions
使用分水岭算法进行区域分割
分水岭算法介绍
分水岭算法是在图像处理中经常使用的图片分区算法,这个算法要求将图形数据转换为二维平面的灰度数据,灰度值代表此像素的深度,也就是高度的负值。算法流程就是不断地对二维平面进行水平面增长,形成多个独立不相连的水域,深度高的地方将优先得到水域覆盖。随着水平面增长,有些原本不相连的水域开始连通,这些水域之间的连通边界就是所谓的分水岭。而在水平面提升过程中形成的水域被这些分水岭边界切分后就是我们所需要的场景区域划分。这里用文字来描述有点乏力,我们用图形来展示。假设初始时平面场景配置如下,网格中深度值为0的代表不可通行:
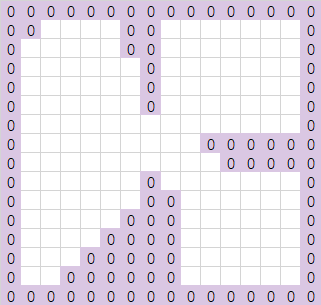
有了这个阻挡信息之后,我们计算网格中每个点到不可通行的网格的最短距离,这里有一个专门的名词叫做距离场(Distance Field)。这个过程类似于前面我们为了做边缘过滤时的处理,这里我们套用recast里的规定,轴向移动的距离为2,对角线移动的距离为3,从而得到了下面的距离场数据:

这里的距离场数据就是分水岭算法所期望的深度数据。有了深度数据之后,我们开始来抬升水平面,初始水平面为最大深度值。同时我们获取水平面初始化之后生成的各个独立水域,这里我们给每个水域都赋予一个字母代表的唯一标识符。上图中最大深度为8,对应的点只有一个点,我们为之分配一个区域a。当然实际情况中最大深度对应的点不止有一个,而且点之间可能连通。相同深度且可直接连接的点需要合并区域,不能分配不同的区域标识符。
有了初始水域集合之后,我们记录当前最低水位为h,同时开始抬升水位。但是由于recast设定相邻单元格之间的距离为2,所以每抬升一次,要处理的深度范围在[h-1,h]内的网格:
-
如果网格与当前某个水域相连通,则将这个网格加入此水域
-
如果网格没有与任意水域相连通,则创建一个新的水域,赋予一个新的唯一标识符
下图就是第一次抬升水平面的结果,对应的水域区间为[7, 8],此时a区域增加了两个深度为7的邻接点:

再一次抬升水位,此时水位区间为[5,6],会引发两个新水域的创建,同时a区域进行扩大:

继续抬升水位,此时水位区间为[3,4],三个区域继续扩大,此时会第一次遇到作为分水岭的格子,连通了多个水域,对于分水岭上的格子区域归属我们使用一个简单的规则,采用连通区域中唯一标识符最大的区域。这样可以避免出现小标识符的区域赢家通吃的局面,区域划分更加均衡:
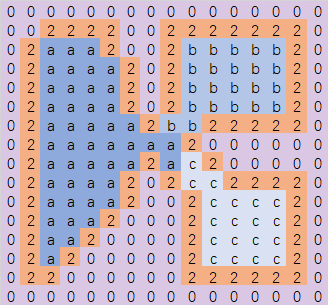
最后一次抬升水位,处理水位区间为[1,2]之间的格子,整个图像分割完毕:

在了解完整体算法核心流程之后,我们再来对照recast的源码进行分析。
距离场创建
分水岭算法的第一步要求把输入数据转换为深度图,在recast中对应的函数为rcBuildDistanceField,内部按序调用两个函数:
-
calculateDistanceField这个就是前面所说的距离场计算函数,这里的逻辑跟前述边界距离计算基本相同,不过前面是以不可行走的span为边界,二距离场计算时遇到span::area不同时就认为遇到了边界 -
boxBlur这个函数用来将距离执行一个周围均值计算,每个span的距离值等于自身距离值加上周围八个邻居span的距离值总和的平均值,这样就可以避免相邻span之间距离差异太大
在RecastDemo中可以可视化的将距离场数据展示出来,以灰度来表明距离区域边界的值,颜色越白代表距离边界越远,颜色越黑代表距离边界越近。
分水岭算法执行
搞定了距离场之后,开始正式的执行分水岭算法的流程,对应的函数为rcBuildRegions。函数开始时负责初始化一些变量,然后开始分水岭的持续迭代:
const int LOG_NB_STACKS = 3;
const int NB_STACKS = 1 << LOG_NB_STACKS; // 8
rcTempVector<LevelStackEntry> lvlStacks[NB_STACKS]; // 这是迭代时作为数组队列使用的结构
for (int i=0; i<NB_STACKS; ++i)
lvlStacks[i].reserve(256);
rcTempVector<LevelStackEntry> stack;
stack.reserve(256);
unsigned short regionId = 1;// 下一个有效的区域id 作为计数器使用
unsigned short level = (chf.maxDistance+1) & ~1; // 距离场的最大距离 + 1
// TODO: Figure better formula, expandIters defines how much the
// watershed "overflows" and simplifies the regions. Tying it to
// agent radius was usually good indication how greedy it could be.
// const int expandIters = 4 + walkableRadius * 2;
const int expandIters = 8;
int sId = -1;
while (level > 0)
{
level = level >= 2 ? level-2 : 0; // 每次迭代时level减2 因为我们定义的相邻span进行轴向移动时的距离为2
sId = (sId+1) & (NB_STACKS-1); // 更新当前要使用的是那一个LevelStackEntry
if (sId == 0)
// 如果迭代次数整除8了 那么遍历距离场里的span 将距离值在[level, level + 16)中的span投递到这八个LevelStackEntry中
// 投递的索引为 (dis - level)/2
sortCellsByLevel(level, chf, srcReg, NB_STACKS, lvlStacks, 1);
else
// 否则将上一次迭代中还没有分配有效region_id的span添加到当前迭代中来使用
appendStacks(lvlStacks[sId-1], lvlStacks[sId], srcReg);
// 分水岭算法的迭代逻辑
// expandRegions
// FloodRegions
}
这里使用sId来索引预先分配的八个LevelStackEntry是为了节省内存,如果每次迭代中都分配一个LevelStackEntry会造成内存很大的浪费,如果只采用双缓冲的话又会导致频繁的去调用sortCellsByLevel执行距离场的遍历,这里为了权衡效率使用了常见的8作为预先分配的数组个数。这样的操作之后,lvlStacks[sId]就存储了当前level里要考虑的span了,现在我们使用expandRegions进行区域扩张,看看哪些span能够合并到现有的区域之中:
static void expandRegions(int maxIter, unsigned short level,
rcCompactHeightfield& chf,
unsigned short* srcReg, unsigned short* srcDist,
rcTempVector<LevelStackEntry>& stack,
bool fillStack)
这个函数的第一个参数代表执行多少次迭代,每次迭代都会执行下面的代码,来尝试将stack里没有region_id的spans合并到相邻的region中:
for (int j = 0; j < stack.size(); j++)
{
int x = stack[j].x;
int y = stack[j].y;
int i = stack[j].index; // 这里的index字段为负数代表已经分配了对应的region
if (i < 0)
{
failed++;
continue;
}
// 所以当前span还没有分配对应region
unsigned short r = srcReg[i];
unsigned short d2 = 0xffff;
const unsigned char area = chf.areas[i];
const rcCompactSpan& s = chf.spans[i];
for (int dir = 0; dir < 4; ++dir)
{
// 遍历四个方向上的邻居
if (rcGetCon(s, dir) == RC_NOT_CONNECTED) continue;
const int ax = x + rcGetDirOffsetX(dir);
const int ay = y + rcGetDirOffsetY(dir);
const int ai = (int)chf.cells[ax+ay*w].index + rcGetCon(s, dir);
// 如果此邻居的表面类型与当前span的表面类型不一样 那么不参与与这个邻居的区域合并
if (chf.areas[ai] != area) continue;
if (srcReg[ai] > 0 && (srcReg[ai] & RC_BORDER_REG) == 0)
{
// srcReg[ai] 大于0代表不是边界,RC_BORDER_REG这个bit代表这个span在高度场的边界内
if ((int)srcDist[ai]+2 < (int)d2)
{
// 选择周围邻居中深度最小的那个作为合并region
// 这里并没有对深度相同时做更多的判断
r = srcReg[ai];
d2 = srcDist[ai]+2;
}
}
}
if (r)//如果从上面的四个邻居中找到了合并的目标region
{
stack[j].index = -1; // 标记为已经合并
dirtyEntries.push_back(DirtyEntry(i, r, d2)); //将合并的数据存下来
}
else
{
// 否则等待下一轮迭代处理
failed++;
}
}
对于在expandRegion执行后stack里还未设置对应region的span,调用floodRegion去尝试分配新的region_id:
// Mark new regions with IDs.
for (int j = 0; j<lvlStacks[sId].size(); j++)
{
LevelStackEntry current = lvlStacks[sId][j];
int x = current.x;
int y = current.y;
int i = current.index;
if (i >= 0 && srcReg[i] == 0)
{
if (floodRegion(x, y, i, level, regionId, chf, srcReg, srcDist, stack))
{
if (regionId == 0xFFFF)
{
ctx->log(RC_LOG_ERROR, "rcBuildRegions: Region ID overflow");
return false;
}
regionId++;
}
}
}
在这个floodRegion中,会执行用栈模拟的DFS遍历,将能从当前span连通的所有其他span都设置上对应的新region_id。不过这里递归时也是有条件的,如果当前要处理的span的八个邻居中存在一个已经分配了区域的span,那这个span不能加入到当前region中,需要等待下一次expandRegion时计算距离最短的region来赋值。这里遍历八个邻居的算法很巧妙,完全通过索引数组来计算的:
// 以顺时针遍历所有的八个邻居
for (int dir = 0; dir < 4; ++dir)
{
// 8 connected
if (rcGetCon(cs, dir) != RC_NOT_CONNECTED)
{
const int ax = cx + rcGetDirOffsetX(dir);
const int ay = cy + rcGetDirOffsetY(dir);
const int ai = (int)chf.cells[ax+ay*w].index + rcGetCon(cs, dir);
// as就是当前的轴向邻居
const rcCompactSpan& as = chf.spans[ai];
const int dir2 = (dir+1) & 0x3;
if (rcGetCon(as, dir2) != RC_NOT_CONNECTED)
{
const int ax2 = ax + rcGetDirOffsetX(dir2);
const int ay2 = ay + rcGetDirOffsetY(dir2);
const int ai2 = (int)chf.cells[ax2+ay2*w].index + rcGetCon(as, dir2);
// as2就是顺时针顺序中as的下一个
const rcCompactSpan& as2 = chf.spans[ai2];
}
}
}
下图就是对应的邻居遍历顺序:
至此,分水岭算法执行区域划分的流程结束。整体流程的时间复杂度大概为span的数量乘以距离场里的最大值,由于单cell中span数量最多为64,所以最坏时间复杂度大概为XZ平面边长的立方。因此随着场景的变大,此过程的执行时间会膨胀的很快。不过NavMesh一般都是离线执行的,所以一般来说也不在乎生成时间,同时又由于分水岭的区域分割效果比较好,因此默认选取这个算法作为区域生成算法。
region 结构体创建
在分水岭算法将span都标记好了对应的区域之后,开始调用mergeAndFilterRegions创建region信息。
struct rcRegion
{
inline rcRegion(unsigned short i) :
spanCount(0),
id(i),
areaType(0),
remap(false),
visited(false),
overlap(false),
connectsToBorder(false),
ymin(0xffff),
ymax(0)
{}
int spanCount; // 当前region内有多少个span
unsigned short id; // 当前region的唯一标识符 大于0
unsigned char areaType; // 当前region的区域类型
bool remap;
bool visited; // 这是一个临时变量不用管
bool overlap; // 当前region是否会跨层 即包括同一个cell里的多个span
bool connectsToBorder; // 当前region是否在边缘
unsigned short ymin, ymax; // 当前region的高度上下界
rcIntArray connections; // 与当前region连通的其他region的id
rcIntArray floors; //这里存储在`XZ`平面上与当前region有重叠的其他region的id
};
这里connections字段的初始化逻辑比较复杂,采用了下面的逻辑来处理:
// Check if this cell is next to a border.
int ndir = -1;
for (int dir = 0; dir < 4; ++dir)
{
if (isSolidEdge(chf, srcReg, x, y, i, dir))
{
ndir = dir;
break;
}
}
if (ndir != -1)
{
// The cell is at border.
// Walk around the contour to find all the neighbours.
walkContour(x, y, i, ndir, chf, srcReg, reg.connections);
}
首先遍历当前span的四个方向邻居,调用isSolidEdge来判定当前span在dir方向的邻居是否归属于其他region。如果当前span存在某个方向能连接到其他region,则调用walkContour从这个span出来沿着当前region的边界上的span进行遍历,同时收集与当前region邻接的region_id存储到connections中。
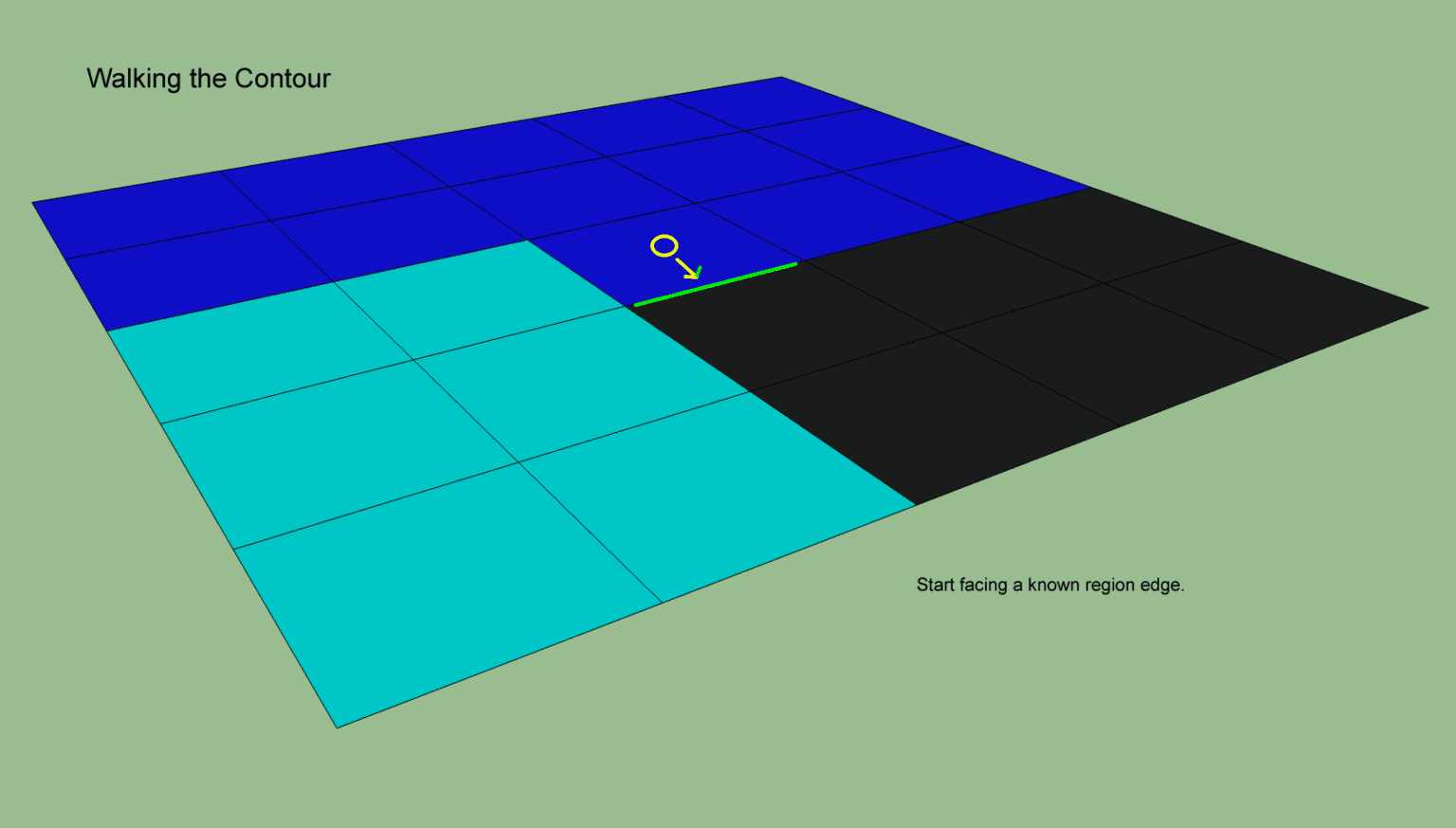
static void walkContour(int x, int y, int i, int dir,
rcCompactHeightfield& chf,
const unsigned short* srcReg,
rcIntArray& cont)
{
// 初始的时候 cells[x][y] 上的span[i] 在dir方向能连通到其他区域 因此当前span肯定是当前region边界上的一个span
int startDir = dir;
int starti = i;
const rcCompactSpan& ss = chf.spans[i];
unsigned short curReg = 0;
if (rcGetCon(ss, dir) != RC_NOT_CONNECTED)
{
// 这个连通判断在外面已经判断通过了
const int ax = x + rcGetDirOffsetX(dir);
const int ay = y + rcGetDirOffsetY(dir);
const int ai = (int)chf.cells[ax+ay*chf.width].index + rcGetCon(ss, dir);
curReg = srcReg[ai];
}
cont.push(curReg); // 加入到连通数组中
int iter = 0;
while (++iter < 40000)
{
const rcCompactSpan& s = chf.spans[i];
// 获取当前要处理的span在当前dir方向是否能连接到其他region
if (isSolidEdge(chf, srcReg, x, y, i, dir))
{
// r代表此方向上的连通region
unsigned short r = 0;
if (rcGetCon(s, dir) != RC_NOT_CONNECTED)
{
const int ax = x + rcGetDirOffsetX(dir);
const int ay = y + rcGetDirOffsetY(dir);
const int ai = (int)chf.cells[ax+ay*chf.width].index + rcGetCon(s, dir);
r = srcReg[ai];
}
if (r != curReg)
{
curReg = r;
cont.push(curReg);
}
// 然后更新下一个判断方向,为顺时针遍历
dir = (dir+1) & 0x3; // Rotate CW
}
else
{
// 如果此方向上的邻居还属于当前region
int ni = -1;
const int nx = x + rcGetDirOffsetX(dir);
const int ny = y + rcGetDirOffsetY(dir);
if (rcGetCon(s, dir) != RC_NOT_CONNECTED)
{
const rcCompactCell& nc = chf.cells[nx+ny*chf.width];
ni = (int)nc.index + rcGetCon(s, dir);
}
if (ni == -1)
{
// Should not happen.
return;
}
// 则将span进行更新 同时方向逆时针回拨
x = nx;
y = ny;
i = ni;
dir = (dir+3) & 0x3; // Rotate CCW
}
if (starti == i && startDir == dir)
{
// 到这里说明已经回到了初始点的初始方向 遍历边界结束
break;
}
}
// 由于region与region之间的边界是连续的 所以con数组有很多连续相同的元素 这里会进行连续重复元素的精简
if (cont.size() > 1)
{
for (int j = 0; j < cont.size(); )
{
int nj = (j+1) % cont.size();
if (cont[j] == cont[nj])
{
for (int k = j; k < cont.size()-1; ++k)
cont[k] = cont[k+1];
cont.pop();
}
else
++j;
}
}
}
上面的遍历边界流程可以用下面的图形来可视化的展示,初始的时候我们选择这条浅蓝色的边,箭头指向的方向为其邻居region的连通方向:
然后继续遍历当前span顺时针下去的其他方向,直到某个方向上连接的是自身区域:
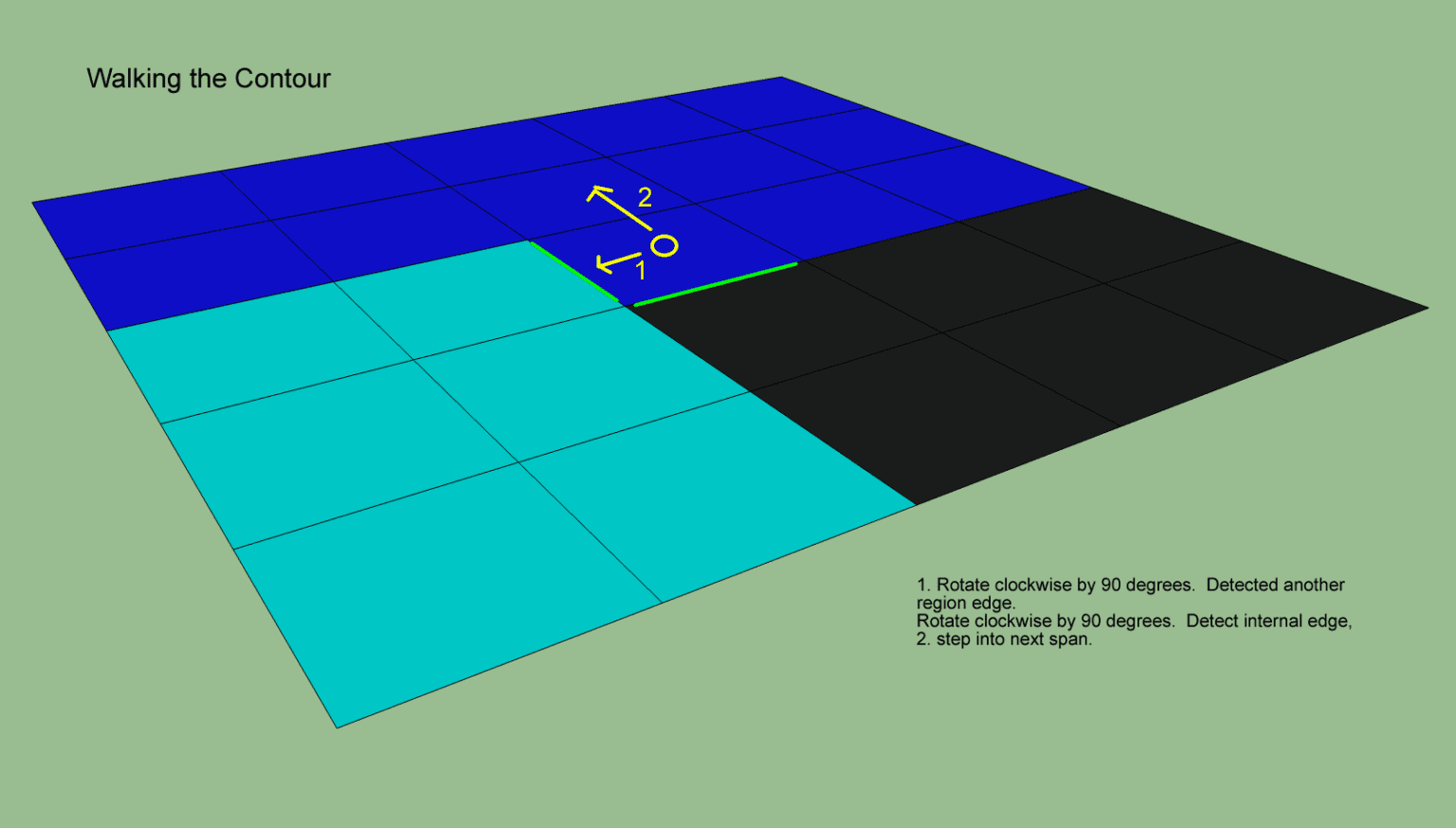
此时需要切换span,同时方向逆时针回拨90度,然后继续开始遍历边界,下面的带序号的边代表在对应的span里遍历四个轴方向的顺序:

面积过小区域合并
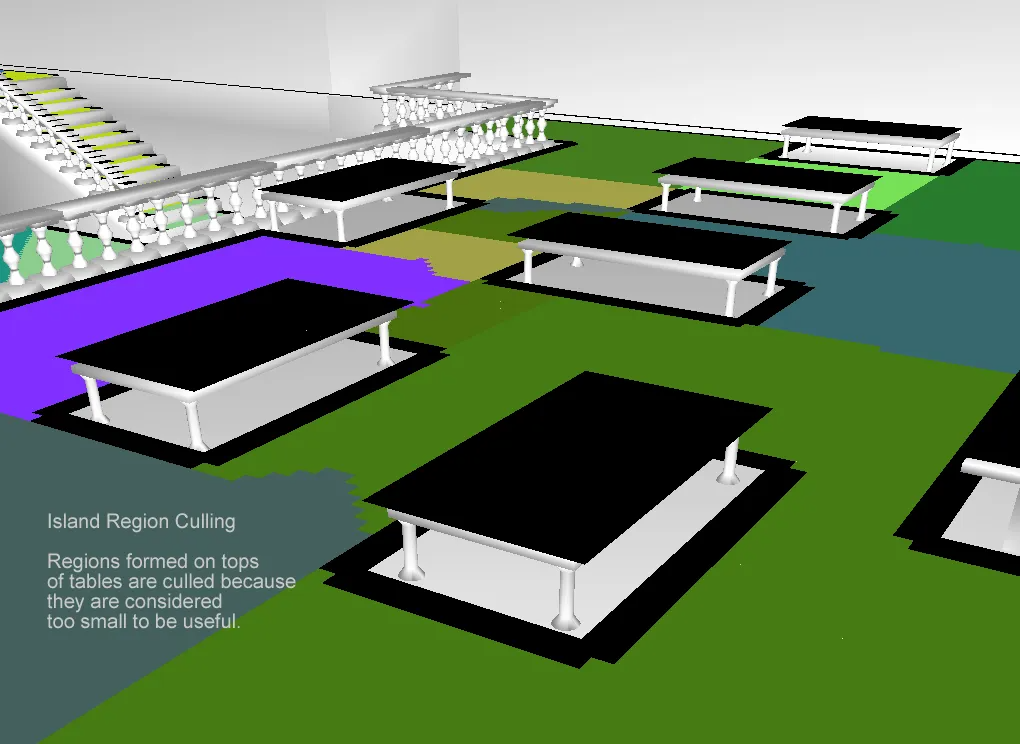
建立了初始的区域之后还要接入一个后处理,删除一些面积过于小的区域。因为分水岭算法经常会造成一小块凸起区域被周围的一个大区域围住,导致后续的多边形划分出现问题。这里有个配置参数minRegionArea,代表最小可行走区域面积,用此参数来删除所有的小区域。实现上就是遍历所有生成的region,如果从这个region可直接或间接连通的所有region的span总数小于这个minRegionArea,这把这些连通的小region都删除:
// Remove too small regions.
rcIntArray stack(32);
rcIntArray trace(32);
for (int i = 0; i < nreg; ++i)
{
rcRegion& reg = regions[i];
if (reg.id == 0 || (reg.id & RC_BORDER_REG)) //边界region不处理
continue;
if (reg.spanCount == 0) //异常region不处理
continue;
if (reg.visited) // 已经在之前遍历的region连通过了 不处理
continue;
// Count the total size of all the connected regions.
// Also keep track of the regions connects to a tile border.
bool connectsToBorder = false;
int spanCount = 0;
stack.clear();
trace.clear();
reg.visited = true;
stack.push(i);
// 下面计算所有可以从当前region出发能到达的region的集合 其实就是一个无向图的连通分量
while (stack.size())
{
// Pop
int ri = stack.pop();
rcRegion& creg = regions[ri];
spanCount += creg.spanCount;
trace.push(ri);
for (int j = 0; j < creg.connections.size(); ++j)
{
if (creg.connections[j] & RC_BORDER_REG)
{
connectsToBorder = true;
continue;
}
rcRegion& neireg = regions[creg.connections[j]];
if (neireg.visited)
continue;
if (neireg.id == 0 || (neireg.id & RC_BORDER_REG))
continue;
// Visit
stack.push(neireg.id);
neireg.visited = true;
}
}
// 如果当前连通分量的span数量小于指定值,且不是tile边界上的的区域 则删除当前连通分量里的所有region
if (spanCount < minRegionArea && !connectsToBorder)
{
// Kill all visited regions.
for (int j = 0; j < trace.size(); ++j)
{
regions[trace[j]].spanCount = 0;
regions[trace[j]].id = 0;
}
}
}
最终成果就是将下图中的桌面设置为了不可行走,因为其表面积太小了:
裁剪完成之后,一些小区域仍然可能残留下来,因为其连通着某些大区域,此时需要将这些小区域合并到对应的大区域中,这里有一个配置参数mergeRegionSize,span数量小于此配置的region将会被合并,不过两个region能否合并还需要通过一个额外的测试:
static bool canMergeWithRegion(const rcRegion& rega, const rcRegion& regb)
{
// 两个区域的表面类型不同 无法合并
if (rega.areaType != regb.areaType)
return false;
int n = 0;
for (int i = 0; i < rega.connections.size(); ++i)
{
if (rega.connections[i] == regb.id)
n++;
}
// 如果两者之间有多条邻接边 合并时可能导致新的大region把原来的某个临接region包围住 因此不能合并
if (n > 1)
return false;
// 如果两个区域在XZ平面上有重叠,也不能参与合并
for (int i = 0; i < rega.floors.size(); ++i)
{
if (rega.floors[i] == regb.id)
return false;
}
return true;
}
有了上面这个合并限制之后,开始循环检测所有的region中是否有可以合并的:
// Merge too small regions to neighbour regions.
int mergeCount = 0 ;
do
{
mergeCount = 0;
for (int i = 0; i < nreg; ++i)
{
rcRegion& reg = regions[i];
if (reg.id == 0 || (reg.id & RC_BORDER_REG)) // 不可行走或者tile边界区域不会合并
continue;
if (reg.overlap) // 有跨层联通span的不会合并
continue;
if (reg.spanCount == 0) // 异常区域不会合并
continue;
// span数量大于这个值 且有个边界区域邻居的 不参与合并
if (reg.spanCount > mergeRegionSize && isRegionConnectedToBorder(reg))
continue;
// 遍历当前所有的邻居区域找到其中span数量最小的region
int smallest = 0xfffffff;
unsigned short mergeId = reg.id;
for (int j = 0; j < reg.connections.size(); ++j)
{
if (reg.connections[j] & RC_BORDER_REG) continue;
rcRegion& mreg = regions[reg.connections[j]];
// 这里要排除所有与边界region连通的邻居
if (mreg.id == 0 || (mreg.id & RC_BORDER_REG) || mreg.overlap) continue;
if (mreg.spanCount < smallest &&
canMergeWithRegion(reg, mreg) &&
canMergeWithRegion(mreg, reg))
{
smallest = mreg.spanCount;
mergeId = mreg.id;
}
}
// 找到一个邻居 将当前region合并过去
if (mergeId != reg.id)
{
unsigned short oldId = reg.id;
rcRegion& target = regions[mergeId];
// 执行span的合并 更新邻居列表
if (mergeRegions(target, reg))
{
for (int j = 0; j < nreg; ++j)
{
if (regions[j].id == 0 || (regions[j].id & RC_BORDER_REG)) continue;
// 如果之前有一个region已经被合并到了当前region 更新其合并目标为新的region
if (regions[j].id == oldId)
regions[j].id = mergeId;
// 将原来所有region里指向当前region的边 都替换为指向要合并的region
replaceNeighbour(regions[j], oldId, mergeId);
}
mergeCount++;
}
}
}
}
while (mergeCount > 0); // 直到一轮循环过后没有新的region触发合并 才结束整体的合并流程
区域重映射
经过区域裁剪和合并后,有效region会变少。为了减少后续操作中不必要的内存开销,现在需要对区域的regionID执行remap操作来重新映射为连续的数字,以此来降低regionID的最大值。
// Compress region Ids.
for (int i = 0; i < nreg; ++i)
{
regions[i].remap = false;
if (regions[i].id == 0) continue; // Skip nil regions.
if (regions[i].id & RC_BORDER_REG) continue; // Skip external regions.
regions[i].remap = true; // 标记所有可行走的且非边界上的区域为可重定向
}
unsigned short regIdGen = 0;
for (int i = 0; i < nreg; ++i)
{
if (!regions[i].remap) // 如果已经被重定向了 则不需要处理
continue;
unsigned short oldId = regions[i].id;
unsigned short newId = ++regIdGen;
// 合并组里的id统一更换
for (int j = i; j < nreg; ++j)
{
if (regions[j].id == oldId)
{
regions[j].id = newId;
regions[j].remap = false;
}
}
}
maxRegionId = regIdGen;
// 最后更新span对应的区域id
for (int i = 0; i < chf.spanCount; ++i)
{
if ((srcReg[i] & RC_BORDER_REG) == 0)
srcReg[i] = regions[srcReg[i]].id;
}
区域的重叠问题
这里其实还有最后一个步骤,将所有含有跨层数据的区域的id记录下来并返回:
// Return regions that we found to be overlapping.
for (int i = 0; i < nreg; ++i)
if (regions[i].overlap)
overlaps.push(regions[i].id);
但是其实外部并没有对这个数组做处理,只是在注释里说要把这些与自身重叠的区域拆成多个不重叠的:
// Merge regions and filter out smalle regions.
rcIntArray overlaps;
chf.maxRegions = regionId;
if (!mergeAndFilterRegions(ctx, minRegionArea, mergeRegionArea, chf.maxRegions, chf, srcReg, overlaps))
return false;
// If overlapping regions were found during merging, split those regions.
if (overlaps.size() > 0)
{
ctx->log(RC_LOG_ERROR, "rcBuildRegions: %d overlapping regions.", overlaps.size());
}
看来只是写了一个TODO,但是没有具体实现,打了一个错误日志对使用者进行警告。那这种overlap的情况会带来怎样的危害呢,请看下图:

在这张图中,我们发现在旋转楼梯上出现了一个很不符合直觉的可行走三角形,同时一些本来应该在楼梯上的三角形并没有生成。造成这个异常的原因是螺旋楼梯中的一部分跨层数据归属于同一个region,然后这种跨层region在后续的三角形切分时无法正确的被处理。
如果想要去解决这个overlap问题,则需要将这个region继续做切分。最简单的做法就是选择一个特定高度Y的XZ平面将原有的区域切分成为上中下三个部分,所有底面高度大于Y+walkableClimb的span划分到一个region,所有底面高度小于Y-walkableClimb的span划分到一个region,剩下的span划分为一个region, 如果切分后的region还有重叠部分再继续切割。例如上图中选择旋转楼梯的转角平面部分作为切分平面,两个切分平面构造出五个不再overlap的区域。当然这个方法也不保证一定有效,所以recast官方也暂时将此问题搁置了。
使用单调分区算法进行区域分割
单调分区算法相对于分水岭算法来说就简单很多了,在平面网格上进行一次二维遍历即可得到结果区域,下面我们继续使用之前使用的平面网格示例来介绍其算法核心思想。初始时的平面网格如下:
在这个地图上我们开始从下到上从左到右的逐行扫描,如果遇到一个不与之前分配好的region连通的可行走网格,则分配一个新的region。所以扫描了第一行之后,我们创建了两个新的区域:
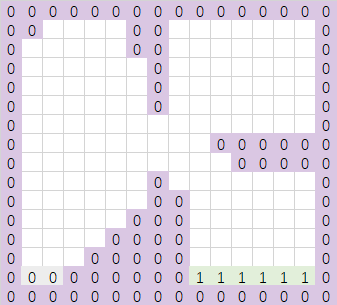
再向上扫描一行,得到下面的区域扩散结果:
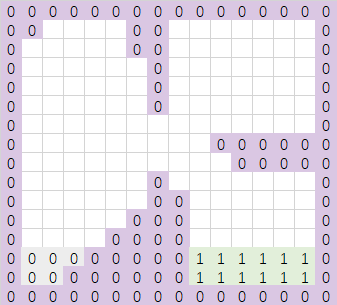
继续扫描四行,结果如下:
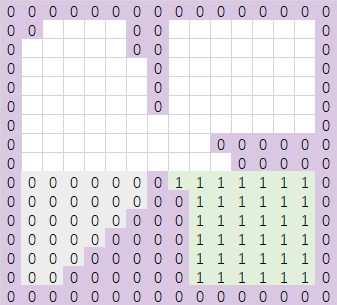
此时要扫描的下一行有点特殊,因为这一行会同时与区域0和区域1相交,对于这种同时与多个区域相连通的连续行,分配一个新的region,继续向上扫描两行之后得到了下面的结果:
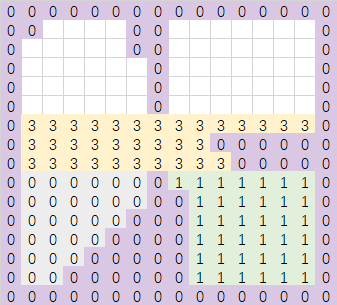
再上面一行会出现两个不连通的连续区域,此时将这两个区域分配新的region,然后继续向上,得到的最终结果如下:
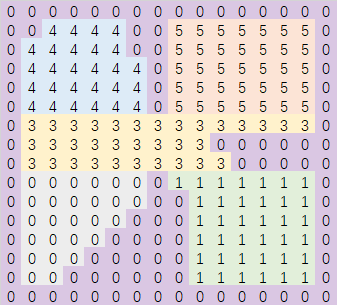
在Recast的源码中负责这个流程的函数为rcBuildRegionsMonotone, 在函数流程中为了方便记录每一行切分出来的每条连续网格组成的条带,使用了下面的数据结构:
struct rcSweepSpan
{
unsigned short rid; // 当前条带在所属行里的条带id
unsigned short id; // 当前条带分配的区域id
unsigned short ns; // 当前条带里的span数量
unsigned short nei; // 当前条带下方的邻居区域id 0代表没有初始化 RC_NULL_NEI 代表有多个
};
算法开始时需要分配好一些资源:
const int nsweeps = rcMax(chf.width,chf.height); // 最坏情况下每个cell单独一个条带
rcScopedDelete<rcSweepSpan> sweeps((rcSweepSpan*)rcAlloc(sizeof(rcSweepSpan)*nsweeps, RC_ALLOC_TEMP));
rcIntArray prev(256); // 存储
unsigned short id = 1; // 用来分配区域id的计数器
// 每次扫描XZ平面的一行
for (int y = borderSize; y < h-borderSize; ++y)
{
// Collect spans from this row.
prev.resize(id+1);
memset(&prev[0],0,sizeof(int)*id);
unsigned short rid = 1;
for (int x = borderSize; x < w-borderSize; ++x)
{
// 遍历这行中的每一个cell
const rcCompactCell& c = chf.cells[x+y*w];
for (int i = (int)c.index, ni = (int)(c.index+c.count); i < ni; ++i)
{
// 遍历当前cell里的每一个span
const rcCompactSpan& s = chf.spans[i];
if (chf.areas[i] == RC_NULL_AREA) continue;
// 找到当前spanXZ平面左边的邻居对应的已分配区域id
unsigned short previd = 0;
if (rcGetCon(s, 0) != RC_NOT_CONNECTED)
{
const int ax = x + rcGetDirOffsetX(0);
const int ay = y + rcGetDirOffsetY(0);
const int ai = (int)chf.cells[ax+ay*w].index + rcGetCon(s, 0);
if ((srcReg[ai] & RC_BORDER_REG) == 0 && chf.areas[i] == chf.areas[ai])
previd = srcReg[ai];
}
if (!previd) // 如果左边没有邻居 说明当前span是一个新的条带的开始 分配一个新的条带id
{
previd = rid++;
sweeps[previd].rid = previd;
sweeps[previd].ns = 0;
sweeps[previd].nei = 0;
}
// 然后再找当前span下方邻居对应的区域id
if (rcGetCon(s,3) != RC_NOT_CONNECTED)
{
const int ax = x + rcGetDirOffsetX(3);
const int ay = y + rcGetDirOffsetY(3);
const int ai = (int)chf.cells[ax+ay*w].index + rcGetCon(s, 3);
if (srcReg[ai] && (srcReg[ai] & RC_BORDER_REG) == 0 && chf.areas[i] == chf.areas[ai])
{
unsigned short nr = srcReg[ai];
if (!sweeps[previd].nei || sweeps[previd].nei == nr)
{
// 如果前面条带下方邻居区域没有初始化过 或者下方的邻居所属区域等于前面计算好的邻居区域id
// 则把当前点加入到前面条带中
sweeps[previd].nei = nr;
sweeps[previd].ns++;
prev[nr]++;
}
else
{
// 前面条带下面有多个不同区域的邻居 需要分配单独的区域id
sweeps[previd].nei = RC_NULL_NEI;
}
}
}
// 先暂时赋值为条带id 等待后续条带id分配了region id之后再修正
srcReg[i] = previd;
}
}
// Create unique ID.
for (int i = 1; i < rid; ++i)
{
// 遍历前面分割出来的多个条带
if (sweeps[i].nei != RC_NULL_NEI && sweeps[i].nei != 0 &&
prev[sweeps[i].nei] == (int)sweeps[i].ns)
{
// 如果这个条带下方的邻居区域只有一个 且这个邻居区域上方的条带也只有一个
// 则当前条带的区域id等于其下方邻居所属的区域id
sweeps[i].id = sweeps[i].nei;
}
else
{
// 下方有多个相邻区域 或者与多个条带共享当前下方的邻居
// 需要分配一个新的区域id
sweeps[i].id = id++;
}
}
// 所有的条带id都分配了一个对应的region id之后
// 将每个span的region id正确的赋值为对应条带的region id
for (int x = borderSize; x < w-borderSize; ++x)
{
const rcCompactCell& c = chf.cells[x+y*w];
for (int i = (int)c.index, ni = (int)(c.index+c.count); i < ni; ++i)
{
if (srcReg[i] > 0 && srcReg[i] < rid)
srcReg[i] = sweeps[srcReg[i]].id;
}
}
}
上面的部分就是执行monotone算法的过程,函数整体就是使用三重循环去遍历所有的span,所以整个monotone算法的时间复杂度为span数量的常数,已经不可能再降低下去了。但是这个算法过于追求速度导致了区域的形状非常不令人满意,会出现很多的长条,唯一的好处就是这种分区方法不会造成前述的overlap问题。
执行完成之后也会调用mergeAndFilterRegions这个函数来创建Region结构体并合并一些过于小的区域到周围的大区域中。
{
rcScopedTimer timerFilter(ctx, RC_TIMER_BUILD_REGIONS_FILTER);
// Merge regions and filter out small regions.
rcIntArray overlaps;
chf.maxRegions = id;
if (!mergeAndFilterRegions(ctx, minRegionArea, mergeRegionArea, chf.maxRegions, chf, srcReg, overlaps))
return false;
// Monotone partitioning does not generate overlapping regions.
}
由于mergeAndFilterRegions的时间复杂度也是span数量的常数,所以整体不影响rcBuildRegionsMonotone的整体时间复杂度。,但是调用mergeAndFilterRegions合并之后可能会导致region的overlap。除非是运行时生成NavMesh。正常情况下不会去选择monotone作为生成方式。
使用分层算法进行区域分割
这里分层算法的入口是rcBuildLayerRegions,这个算法基本等价于monotone算法,唯一的修正就是进行最后的区域合并过程调用的不再是可能会造成overlap的mergeAndFilterRegions,换成了一个确保不会造成overlap的mergeAndFilterLayerRegions。不过这个函数与mergeAndFilterRegions的差异没多大,就下面部分体现出了不同,这部分代码在创建初始Region之后:
// Create 2D layers from regions.
unsigned short layerId = 1;
for (int i = 0; i < nreg; ++i)
regions[i].id = 0;
// Merge montone regions to create non-overlapping areas.
rcIntArray stack(32);
for (int i = 1; i < nreg; ++i)
{
rcRegion& root = regions[i];
// Skip already visited.
if (root.id != 0)
continue;
// Start search.
root.id = layerId;
stack.clear();
stack.push(i);
while (stack.size() > 0)
{
// Pop front
rcRegion& reg = regions[stack[0]];
for (int j = 0; j < stack.size()-1; ++j)
stack[j] = stack[j+1];
stack.resize(stack.size()-1);
const int ncons = (int)reg.connections.size();
for (int j = 0; j < ncons; ++j)
{
const int nei = reg.connections[j];
rcRegion& regn = regions[nei];
// Skip already visited.
if (regn.id != 0)
continue;
// Skip if different area type, do not connect regions with different area type.
if (reg.areaType != regn.areaType)
continue;
// 如果当前邻居span所属的region与当前合并中的region有xz平面交集 则禁止合并
bool overlap = false;
for (int k = 0; k < root.floors.size(); k++)
{
if (root.floors[k] == nei)
{
overlap = true;
break;
}
}
if (overlap)
continue;
// Deepen
stack.push(nei);
// Mark layer id
regn.id = layerId;
// 如果合并进去了 则将地面xz的相交区域扩大
for (int k = 0; k < regn.floors.size(); ++k)
addUniqueFloorRegion(root, regn.floors[k]);
root.ymin = rcMin(root.ymin, regn.ymin);
root.ymax = rcMax(root.ymax, regn.ymax);
root.spanCount += regn.spanCount;
regn.spanCount = 0;
root.connectsToBorder = root.connectsToBorder || regn.connectsToBorder;
}
}
layerId++;
}
上面的代码就是查找连接过来的region时如果发现与当前计算出来的合并区域有overlap的地方,则不把这个区域与当前已经生成的合并区域进行合并。不过这个函数无法在分水岭生成的初始区域上执行,因为分水岭生成的初始区域可能已经有overlap了,这里再考虑避免overlap已经晚了。
区域轮廓生成与平滑
在经过区域生成之后,原有的压缩高度场里的span都分配好了对应的区域id。这些区域数据可以极大的加速原来基于span的联通路径查找,因为我们可以把整个场景的连通图从span连通图切换到区域连通图,节点数量会降低到原来的几十分之一甚至几百分之一。但是Recast并没有止步于此,因为存储span的压缩高度场数据消耗了过多的内存。为了打造一个更加完美的寻路数据结构,需要找到一个更省内存的描述区域数据的方法。Recast使用的方法是只存储区域的边界信息,生成一些简单的多边形,也就是区域的轮廓Contour,这个过程对应的函数为rcBuildContours。
标记在边界区域的span
这部分的代码很简单,遍历每个span查找其四个方向的邻居所属区域是否等于当前区域即可:
// 这里的flag数组标记每个span在四个方向是否与其他非自身可行区域相连 如果相连则对应方向的bit设置为1
// 如果与边界相邻 则设置为0
rcScopedDelete<unsigned char> flags((unsigned char*)rcAlloc(sizeof(unsigned char)*chf.spanCount, RC_ALLOC_TEMP));
// Mark boundaries.
for (int y = 0; y < h; ++y)
{
for (int x = 0; x < w; ++x)
{
const rcCompactCell& c = chf.cells[x+y*w];
for (int i = (int)c.index, ni = (int)(c.index+c.count); i < ni; ++i)
{
unsigned char res = 0;
const rcCompactSpan& s = chf.spans[i];
if (!chf.spans[i].reg || (chf.spans[i].reg & RC_BORDER_REG))
{
flags[i] = 0;
continue;
}
for (int dir = 0; dir < 4; ++dir)
{
unsigned short r = 0;
if (rcGetCon(s, dir) != RC_NOT_CONNECTED) // 找到当前方向的邻居span所在的区域
{
const int ax = x + rcGetDirOffsetX(dir);
const int ay = y + rcGetDirOffsetY(dir);
const int ai = (int)chf.cells[ax+ay*w].index + rcGetCon(s, dir);
r = chf.spans[ai].reg;
}
if (r == chf.spans[i].reg) // 如果邻居区域与当前span的区域相同
res |= (1 << dir); // 则这方向对应的bit设置为1
}
// 然后取反 所以某个方向的bit为1代表此方向连通到其他区域
flags[i] = res ^ 0xf;
}
}
}
构造区域轮廓点
这里定义了一个与之前创建Region时使用的WalkContour同名的函数来收集一个Region的顺时针存储的边界span列表。之所以同名是因为其逻辑类似,但是又有那么一些不同。
static void walkContour(int x, int y, int i,
rcCompactHeightfield& chf,
unsigned char* flags, rcIntArray& points)
{
// 找到第一个与其他区域连通的方向
unsigned char dir = 0;
while ((flags[i] & (1 << dir)) == 0)
dir++;
unsigned char startDir = dir;
int starti = i;
const unsigned char area = chf.areas[i];
int iter = 0;
while (++iter < 40000)
{
// 如果当前span在dir方向联通到了其他区域
if (flags[i] & (1 << dir))
{
bool isBorderVertex = false;
bool isAreaBorder = false;
// 下面的px py pz 代表当前点对应的轮廓点坐标
int px = x;
int py = getCornerHeight(x, y, i, dir, chf, isBorderVertex);
int pz = y;
switch(dir)
{
case 0: pz++; break;
case 1: px++; pz++; break;
case 2: px++; break;
}
int r = 0;
const rcCompactSpan& s = chf.spans[i];
if (rcGetCon(s, dir) != RC_NOT_CONNECTED)
{
const int ax = x + rcGetDirOffsetX(dir);
const int ay = y + rcGetDirOffsetY(dir);
const int ai = (int)chf.cells[ax+ay*chf.width].index + rcGetCon(s, dir);
r = (int)chf.spans[ai].reg;
if (area != chf.areas[ai]) // 检测邻居区域的地表类型是否改变
isAreaBorder = true;
}
if (isBorderVertex)
r |= RC_BORDER_VERTEX;
if (isAreaBorder)
r |= RC_AREA_BORDER;
// 将当前点加入到边界拐角点
points.push(px);
points.push(py);
points.push(pz);
points.push(r);
// 清除掉此方向的边界联通标记 避免后面的循环重复处理
flags[i] &= ~(1 << dir);
dir = (dir+1) & 0x3; // 顺时针旋转90度
}
else
{
// 如果此方向不与其他区域相连 那么应该是与当前同区域的一个span相连
int ni = -1; // 记录此方向 联通的邻居span的索引
const int nx = x + rcGetDirOffsetX(dir);
const int ny = y + rcGetDirOffsetY(dir);
const rcCompactSpan& s = chf.spans[i];
if (rcGetCon(s, dir) != RC_NOT_CONNECTED)
{
const rcCompactCell& nc = chf.cells[nx+ny*chf.width];
ni = (int)nc.index + rcGetCon(s, dir);
}
if (ni == -1)
{
// Should not happen.
return;
}
// 跳转到这个邻居span
x = nx;
y = ny;
i = ni;
dir = (dir+3) & 0x3; // 同时逆时针旋转90度
}
if (starti == i && startDir == dir) // 如果遇到了开始时的节点与方向 则迭代结束
{
break;
}
}
}
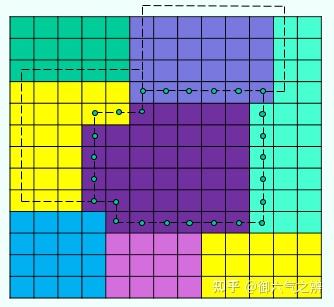
这个walkContour函数与区域构建时的walkContour唯一不同的地方在于计算了遍历时遇到的轮廓点(px, py, pz)。轮廓点连接起来则组成了当前Region的轮廓边,为了让相邻的两个区域共享同一条轮廓边,需要让两个连通且属于不同区域的span计算出来的轮廓点坐标相同。所以这里的轮廓点根据连通方向来选择:
- 连通方向为左边
dir=0,轮廓点选择当前span的XZ上方,即pz++ - 连通方向为上边
dir=1,轮廓点选择当前span的XZ右上方,即px++,pz++ - 连通方向为右边
dir=2,轮廓点选择当前span的XZ右方,即px++ - 连通方向为下边
dir=3,轮廓点取其自身
所以一个轮廓点会最多对应四个边界span。
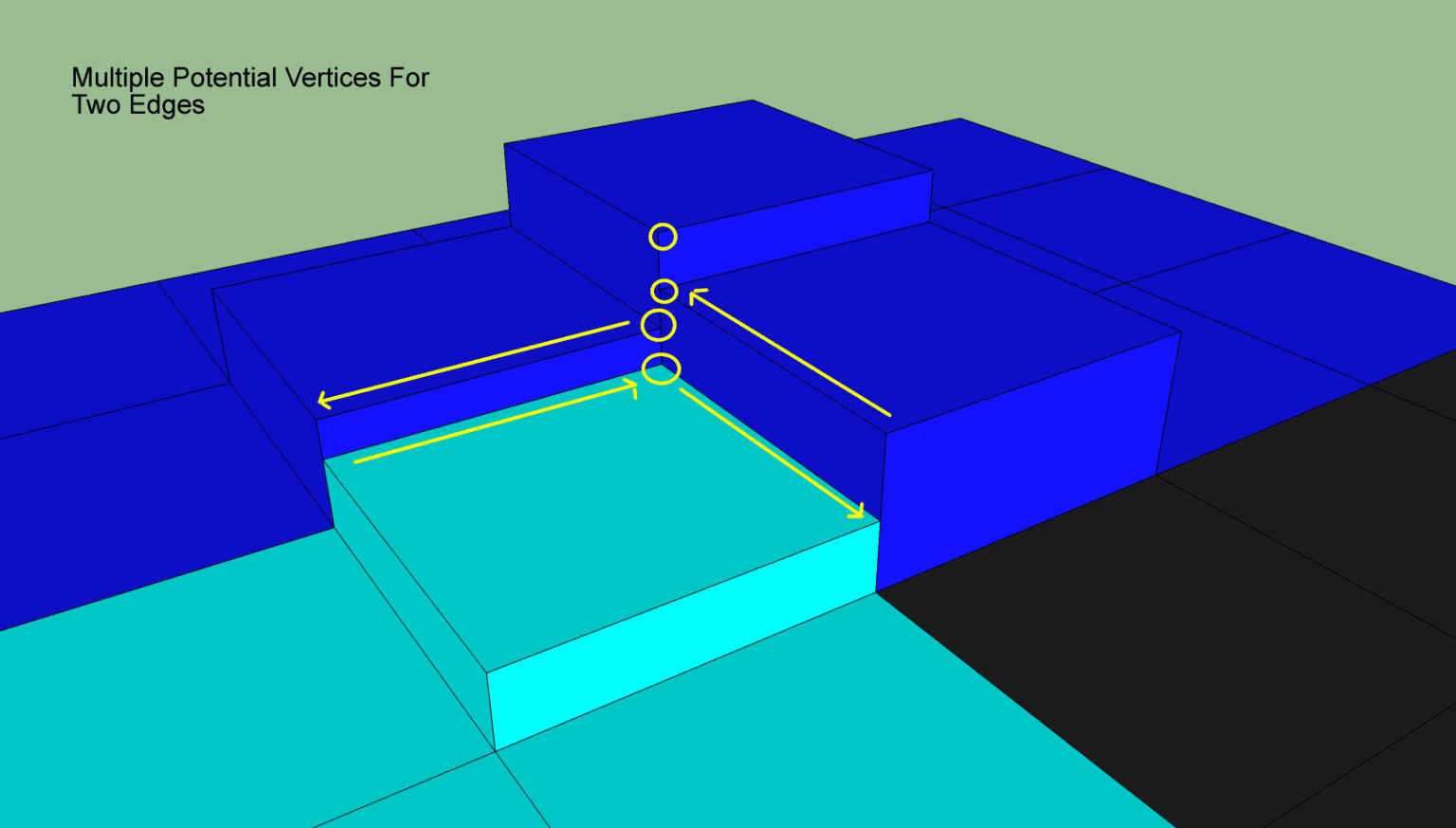
上面的规则只是计算出来了轮廓点的XZ平面坐标,我们还需要知道这个轮廓点的Y轴坐标。由于同一个span作为轮廓点可能出现四次,所以其Y轴坐标有四种选择方案:
为了避免出现太多的轮廓点,我们需要为这四种情况计算出相同的Y轴坐标,最安全的的方法就是选取表面高度最高的,这样能避免轮廓边与地表出现穿插:
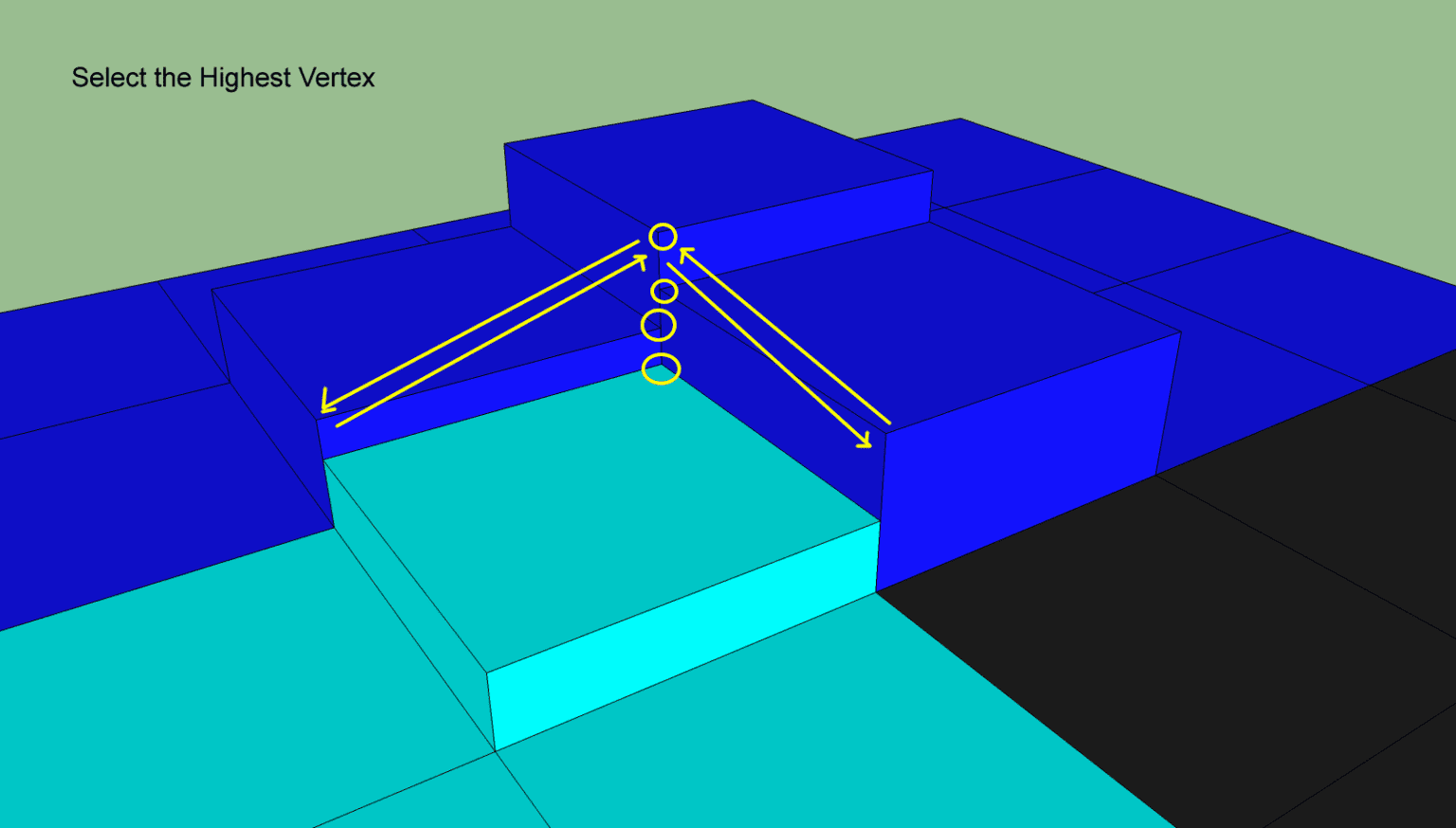
这部分使用了getCornerHeight(x, y, i, dir, chf, isBorderVertex)来计算,不过这个函数不仅计算了轮廓点的Y值,还计算了这个轮廓点是否处于边界上:
static int getCornerHeight(int x, int y, int i, int dir,
const rcCompactHeightfield& chf,
bool& isBorderVertex)
{
const rcCompactSpan& s = chf.spans[i];
int ch = (int)s.y;
int dirp = (dir+1) & 0x3; //顺时针旋转90度
// 一个轮廓点对应了四个span 0自身 1 dir方向 2 dir+45度 3 dir加90度
unsigned int regs[4] = {0,0,0,0};
// 每个int低16位代表邻居的区域id 高16位代表邻居的地表类型
// 在两个不同地表边界上的轮廓点会被标记起来
regs[0] = chf.spans[i].reg | (chf.areas[i] << 16);
if (rcGetCon(s, dir) != RC_NOT_CONNECTED)
{
const int ax = x + rcGetDirOffsetX(dir);
const int ay = y + rcGetDirOffsetY(dir);
const int ai = (int)chf.cells[ax+ay*chf.width].index + rcGetCon(s, dir);
const rcCompactSpan& as = chf.spans[ai];
ch = rcMax(ch, (int)as.y);
regs[1] = chf.spans[ai].reg | (chf.areas[ai] << 16); //
if (rcGetCon(as, dirp) != RC_NOT_CONNECTED)
{
// 这里就是dir + 45度的邻居
const int ax2 = ax + rcGetDirOffsetX(dirp);
const int ay2 = ay + rcGetDirOffsetY(dirp);
const int ai2 = (int)chf.cells[ax2+ay2*chf.width].index + rcGetCon(as, dirp);
const rcCompactSpan& as2 = chf.spans[ai2];
ch = rcMax(ch, (int)as2.y);
regs[2] = chf.spans[ai2].reg | (chf.areas[ai2] << 16);
}
}
if (rcGetCon(s, dirp) != RC_NOT_CONNECTED)
{
// 这里是dir + 90度的邻居
const int ax = x + rcGetDirOffsetX(dirp);
const int ay = y + rcGetDirOffsetY(dirp);
const int ai = (int)chf.cells[ax+ay*chf.width].index + rcGetCon(s, dirp);
const rcCompactSpan& as = chf.spans[ai];
ch = rcMax(ch, (int)as.y);
regs[3] = chf.spans[ai].reg | (chf.areas[ai] << 16);
if (rcGetCon(as, dir) != RC_NOT_CONNECTED)
{
// 这里又计算了一次dir + 45
const int ax2 = ax + rcGetDirOffsetX(dir);
const int ay2 = ay + rcGetDirOffsetY(dir);
const int ai2 = (int)chf.cells[ax2+ay2*chf.width].index + rcGetCon(as, dir);
const rcCompactSpan& as2 = chf.spans[ai2];
ch = rcMax(ch, (int)as2.y);
regs[2] = chf.spans[ai2].reg | (chf.areas[ai2] << 16);
}
}
// 检查是否是特殊边界顶点
for (int j = 0; j < 4; ++j)
{
// 构造顺时针顺序
const int a = j;
const int b = (j+1) & 0x3;
const int c = (j+2) & 0x3;
const int d = (j+3) & 0x3;
// 当前span与后面的span同属于一个边界区域
const bool twoSameExts = (regs[a] & regs[b] & RC_BORDER_REG) != 0 && regs[a] == regs[b];
// 剩下的两个span都不在边界区域内
const bool twoInts = ((regs[c] | regs[d]) & RC_BORDER_REG) == 0;
// 剩下的两个span的地表相同
const bool intsSameArea = (regs[c]>>16) == (regs[d]>>16);
// 四个点都是可行走平面
const bool noZeros = regs[a] != 0 && regs[b] != 0 && regs[c] != 0 && regs[d] != 0;
if (twoSameExts && twoInts && intsSameArea && noZeros)
{
// 则当前轮廓点在边界上
isBorderVertex = true;
break;
}
}
return ch;
}
获取轮廓强制顶点
经过上面的轮廓点构造之后,每个区域都可以使用连续且闭合的轮廓点路径来描述。但是这个路径里的相邻轮廓点组成的边数量太多了,因为相邻的两个轮廓点要么是轴邻居要么是对角线邻居,最大距离只有3。
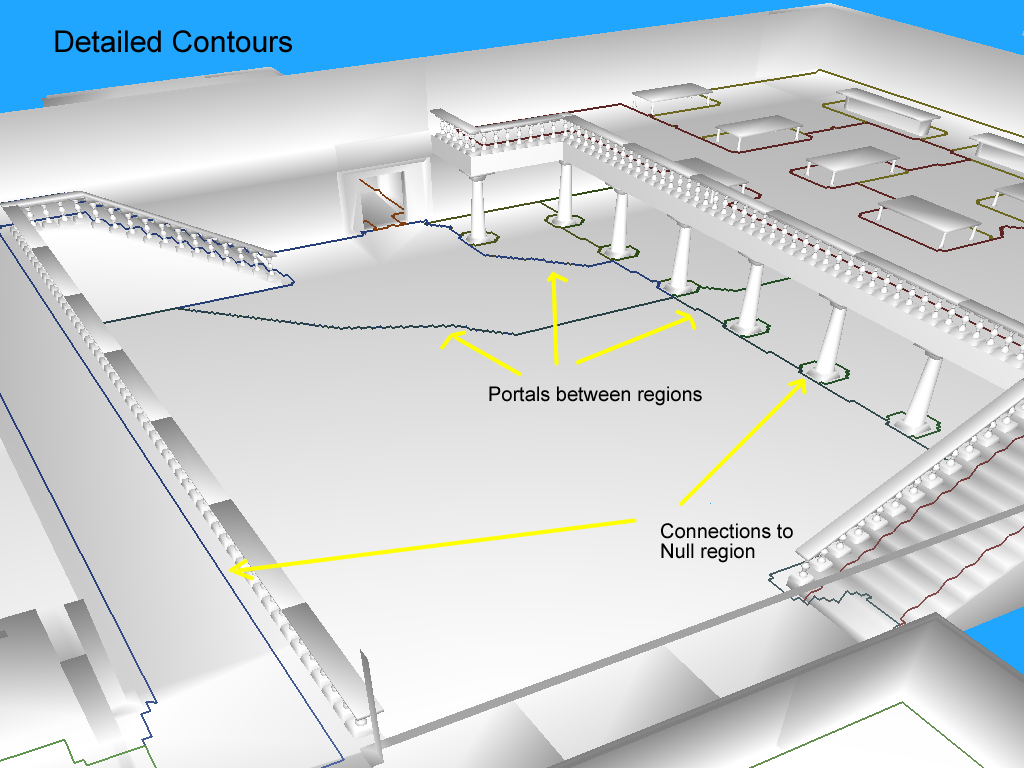
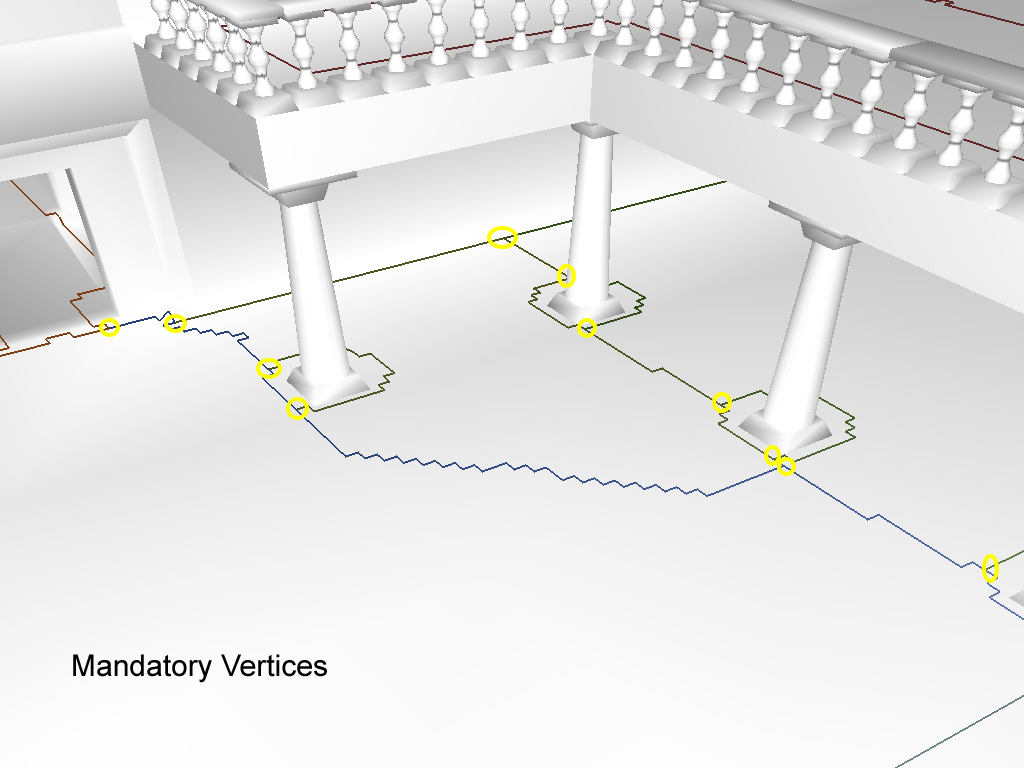
在平面中其实很多轮廓点是共线的,或者近似共线。如上图所示,连续轮廓点组成了很多的轴平行直线或者锯齿样折线。对于一条线段来说,只使用首尾两个端点的数据即可描述,然而其体素化的点数量则与线段长度正相关。所以接下来Recast将连续相邻的轮廓点闭合路径转简化形状相似的线段闭合路径,用这个线段闭合路径来描述区域,这个简化过程其实就是轮廓点的删除过程。为了确定哪些轮廓点可以删除哪些轮廓点必须保留,Recast引入了强制顶点(Mandatory Vertices)的概念:区域连接发生变化的顶点。这种强制顶点需要满足下面的两个条件之一:
-
两个可行走区域边界上的顶点
-
可行走区域与不可行走区域边界上的顶点
这个简化过程会将对应的函数为simplifyContour::
static void simplifyContour(rcIntArray& points, rcIntArray& simplified,
const float maxError, const int maxEdgeLen, const int buildFlags)
points参数里存储了一个区域的轮廓点数组, 每个轮廓点由四个整数组成(x,y,z,r),这里的r是通过前述的walkContour构造而来的,低16位代表区域标识符,如果为0则代表不可行走:
// walkcontour中的r相关代码片段
static const int RC_BORDER_VERTEX = 0x10000;
static const int RC_AREA_BORDER = 0x20000;
bool isBorderVertex = false;
bool isAreaBorder = false;
int py = getCornerHeight(x, y, i, dir, chf, isBorderVertex);
r = (int)chf.spans[ai].reg;
if (area != chf.areas[ai])
isAreaBorder = true;
if (isBorderVertex) // 如果当前轮廓点连通到不可行走区域 则设置此bit为true
r |= RC_BORDER_VERTEX;
if (isAreaBorder)
r |= RC_AREA_BORDER; // 如果当前轮廓点会连接不同的地表 则设置此bit为true
在simplifyContour中,开头先找到初始的简化点:
static const int RC_CONTOUR_REG_MASK = 0xffff;
// Add initial points.
bool hasConnections = false; // 这个代表是否连通到其他可行走区域
for (int i = 0; i < points.size(); i += 4) // 每个轮廓点用了四个int(x,y,z,r)
{
if ((points[i+3] & RC_CONTOUR_REG_MASK) != 0)
{
hasConnections = true;
break;
}
}
if (hasConnections)
{
// 找到轮廓点中邻居区域发生改变的点
for (int i = 0, ni = points.size()/4; i < ni; ++i)
{
int ii = (i+1) % ni;
// 相邻两个点的连通邻居不一样
const bool differentRegs = (points[i*4+3] & RC_CONTOUR_REG_MASK) != (points[ii*4+3] & RC_CONTOUR_REG_MASK);
// 出现了从可行走区域到不可行走区域的变化
const bool areaBorders = (points[i*4+3] & RC_AREA_BORDER) != (points[ii*4+3] & RC_AREA_BORDER);
if (differentRegs || areaBorders)
{
// 将(x, y, z, i) 这四元组存储到simplified中
simplified.push(points[i*4+0]);
simplified.push(points[i*4+1]);
simplified.push(points[i*4+2]);
simplified.push(i);
}
}
}
下图中使用黄色圆圈来标注一些符合上述要求的强制顶点:
如果当前区域没有符合要求的简化点,则会选择左下和右上的两个点作为简化点:
if (simplified.size() == 0)
{
// If there is no connections at all,
// create some initial points for the simplification process.
// Find lower-left and upper-right vertices of the contour.
int llx = points[0];
int lly = points[1];
int llz = points[2];
int lli = 0;
int urx = points[0];
int ury = points[1];
int urz = points[2];
int uri = 0;
for (int i = 0; i < points.size(); i += 4)
{
int x = points[i+0];
int y = points[i+1];
int z = points[i+2];
if (x < llx || (x == llx && z < llz))
{
llx = x;
lly = y;
llz = z;
lli = i/4;
}
if (x > urx || (x == urx && z > urz))
{
urx = x;
ury = y;
urz = z;
uri = i/4;
}
}
simplified.push(llx);
simplified.push(lly);
simplified.push(llz);
simplified.push(lli);
simplified.push(urx);
simplified.push(ury);
simplified.push(urz);
simplified.push(uri);
}
获取了强制顶点之后,将一个区域内按照顺时针存储的强制顶点首尾相连,就形成了当前区域的简化边界:
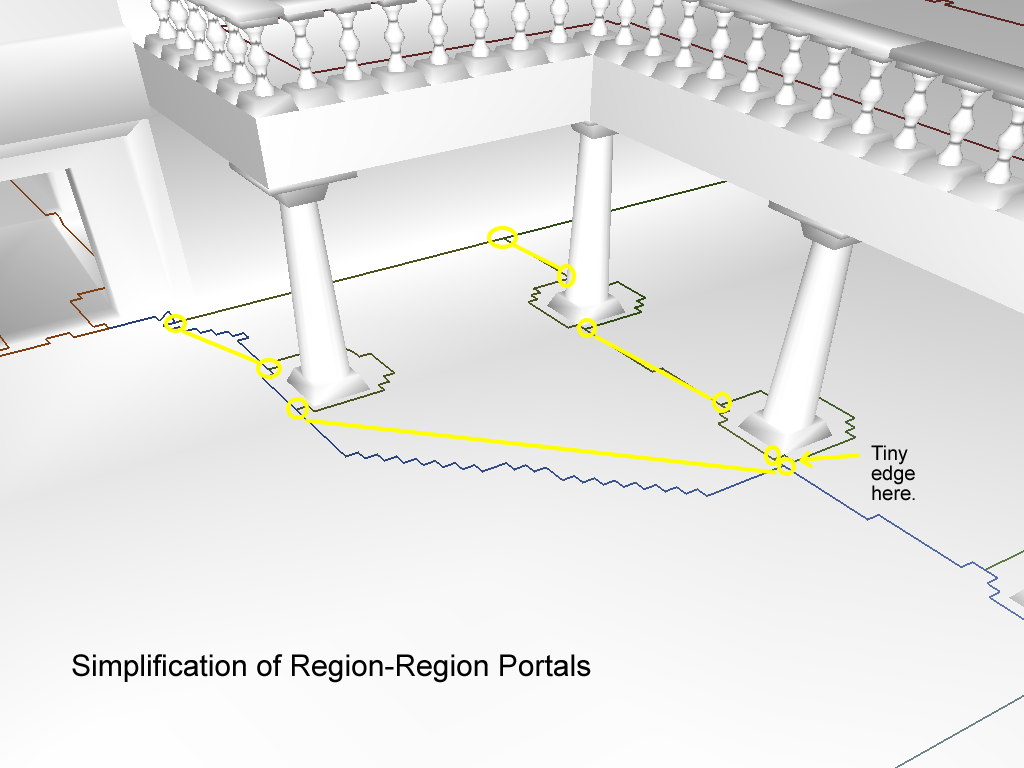
回收轮廓点来匹配区域边界
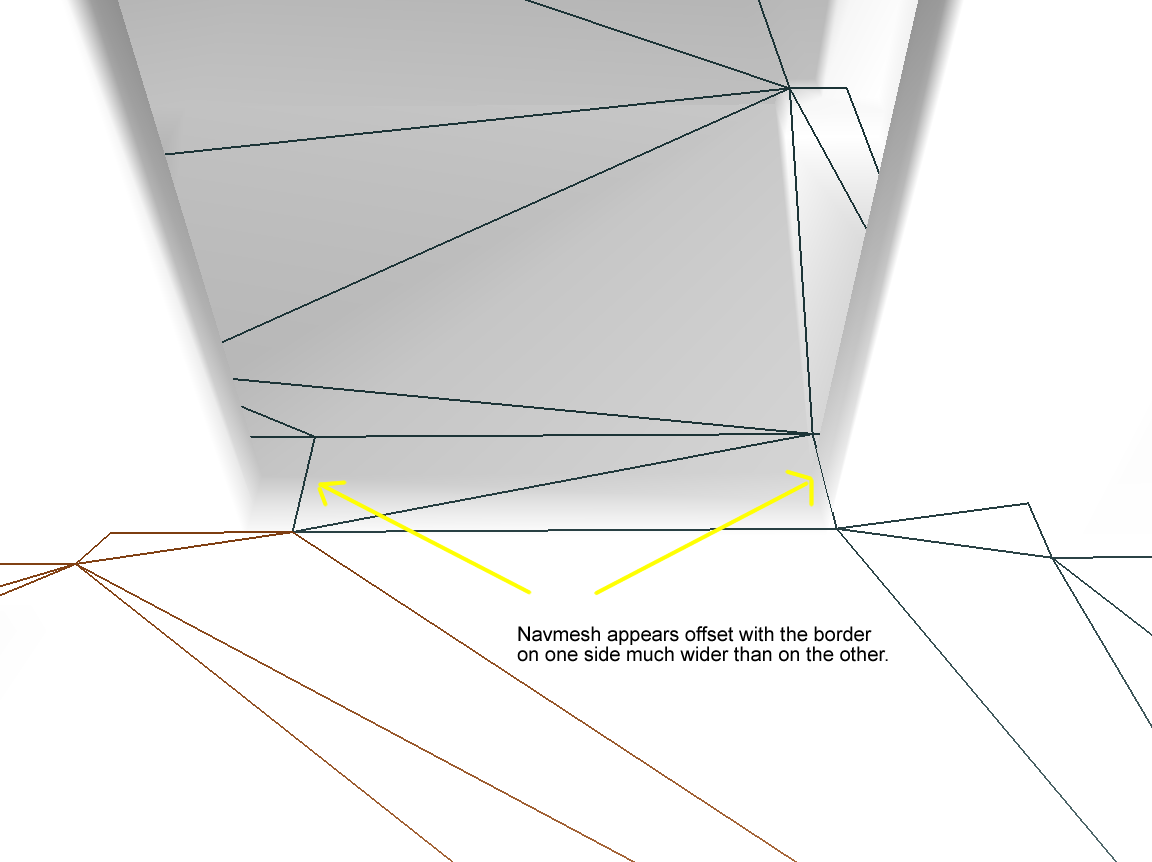
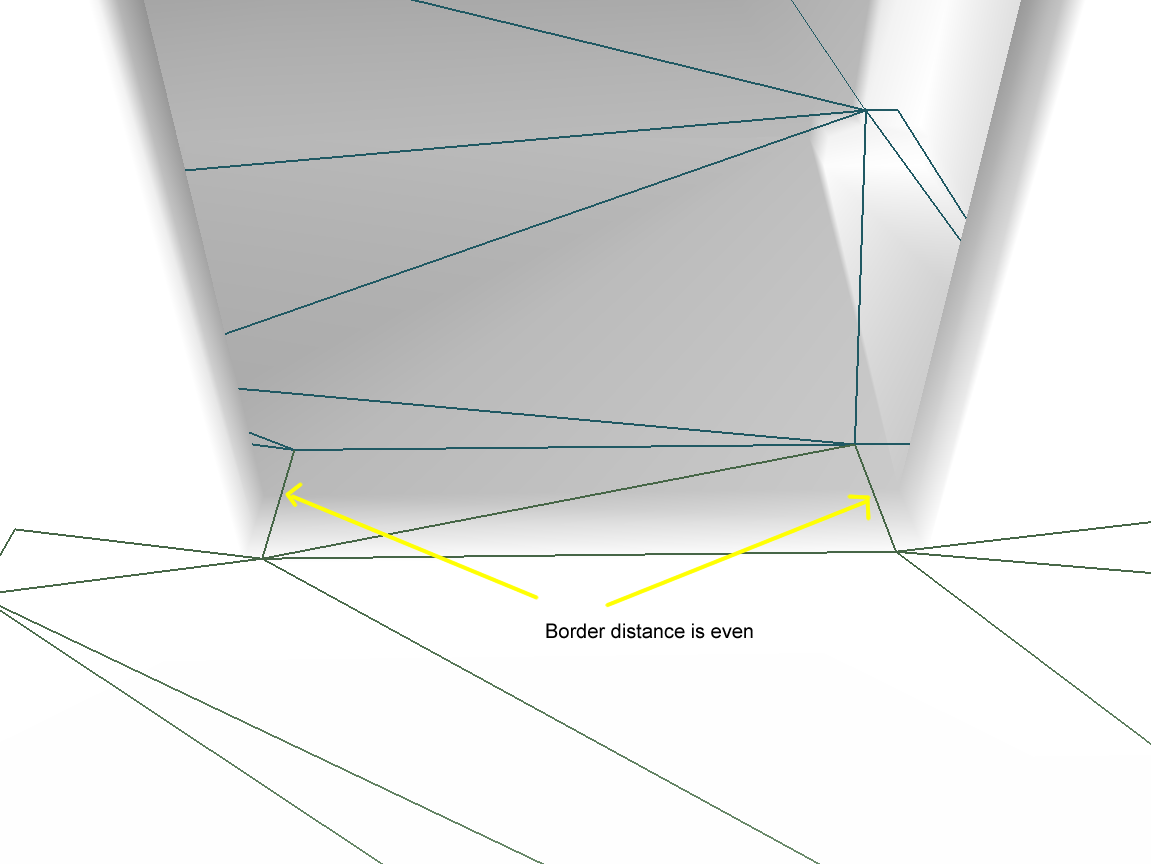
不过这样的简化边界可能过于简化了,会导致与原始区域不怎么匹配。此时需要找到原始的轮廓点里与对应的简化边界距离大于最大简化误差maxSimplificationError的点,重新插入到简化边界中,使得边界更匹配原始区域形状。这里的距离计算使用的是在XZ平面上点到直线的距离,因此执行轮廓点回收之后,多边形的XZ平面投影能够更加的拟合原始区域的XZ投影。
当完全不使用maxSimplificationError来添加节点的时候,会产生下面的偏移比较严重的边界:
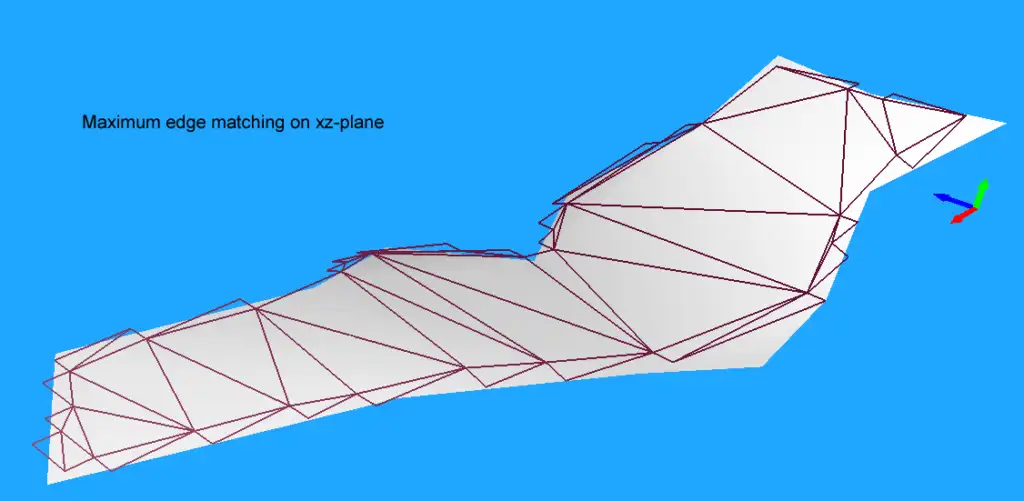
使用合适大小的最大简化误差来增加轮廓点之后,得到了一个比较完美的匹配:
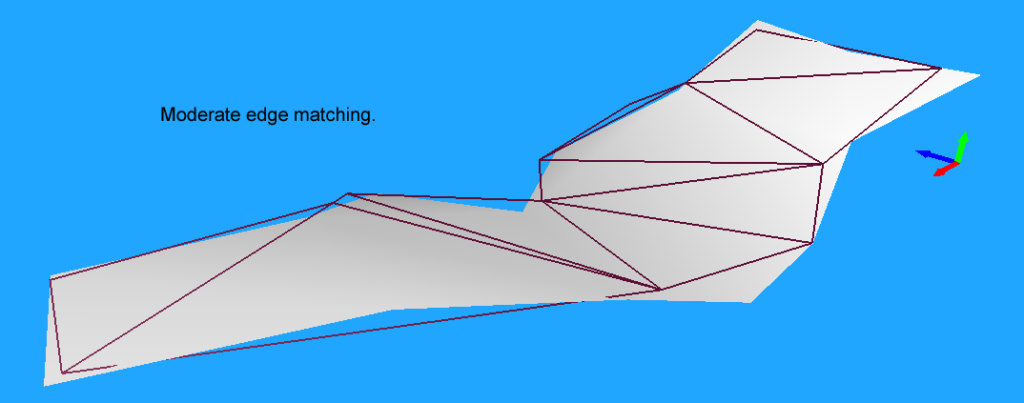
不过此参数如果设置的太小,会导致回收了太多的轮廓点从而生成了很多的小多边形,反而影响后续各种处理的效率:
这个过程其实是一个递归过程,每次处理存储在simplified两个相邻的简化点A,B,这两个简化点对应的points数组连续区间为[C, D],遍历[C, D]中所有的点计算到边(A, B)的距离最大值,如果这个最大值大于了maxSimplificationError,则将距离最大值对应的点E插入到simplified数组中,使得A,E,B是三个相邻的元素,然后再对A,E递归处理。
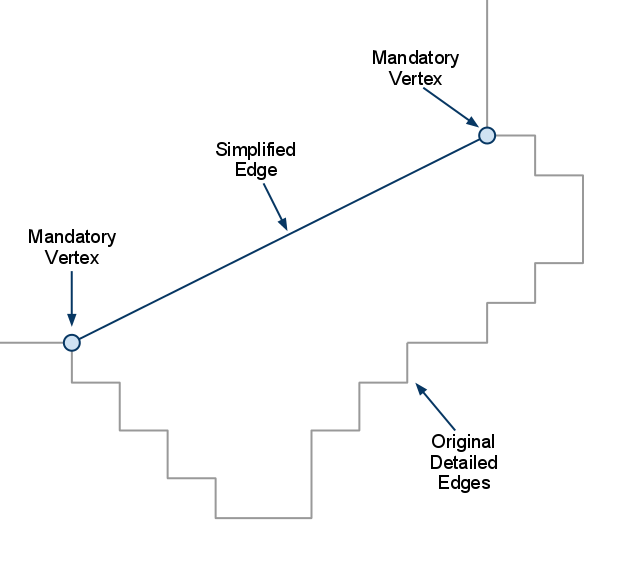
下面给出这个递归处理的图例来加深理解,初始时我们选择了两个点,构造了一条简化边:
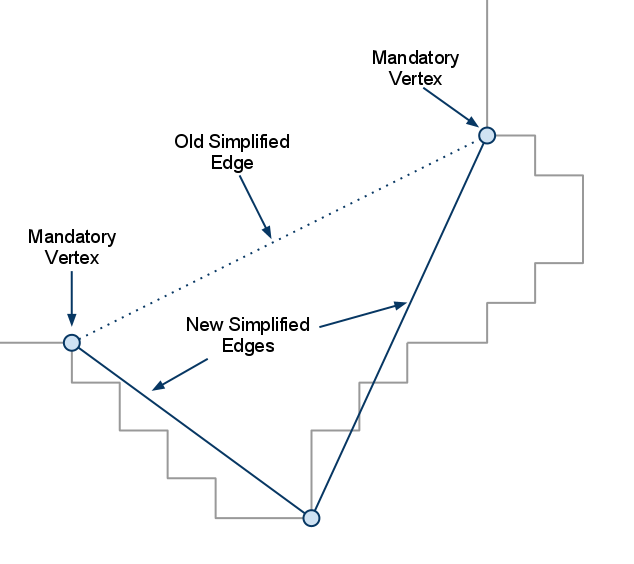
找到覆盖的原始轮廓点区间内与这条简化边偏移最大的,如果大于偏移误差则添加这个点到简化点中,同时构造了两个新的简化边:
然后再递归处理这两条新的边,直到没有新的简化点出现,代表最开始的简化边的轮廓点回收执行完成:
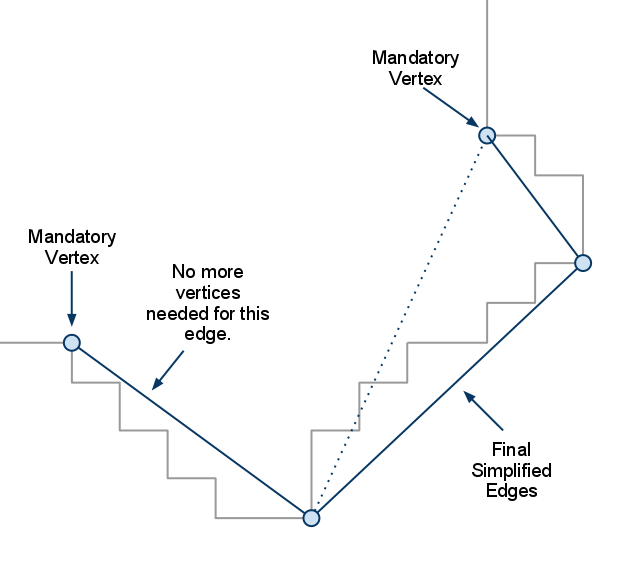
对应的代码如下:
// Add points until all raw points are within
// error tolerance to the simplified shape.
const int pn = points.size()/4;
for (int i = 0; i < simplified.size()/4; )
{
// 获取相邻的两个点 构造一条简化边
int ii = (i+1) % (simplified.size()/4);
int ax = simplified[i*4+0];
int az = simplified[i*4+2];
int ai = simplified[i*4+3];
int bx = simplified[ii*4+0];
int bz = simplified[ii*4+2];
int bi = simplified[ii*4+3];
// Find maximum deviation from the segment.
float maxd = 0;
int maxi = -1;
// 下面三个变量是用来控制节点便利时的方向
int ci, cinc, endi;
// 下面的操作来确保b点一定在a点右侧 这样方便后续的距离计算
if (bx > ax || (bx == ax && bz > az))
{
cinc = 1;
ci = (ai+cinc) % pn;
endi = bi;
}
else
{
// 不在右侧则swap
cinc = pn-1;
ci = (bi+cinc) % pn;
endi = ai;
rcSwap(ax, bx);
rcSwap(az, bz);
}
// 只处理与不可连通区域交界的边
if ((points[ci*4+3] & RC_CONTOUR_REG_MASK) == 0 ||
(points[ci*4+3] & RC_AREA_BORDER))
{
while (ci != endi)
{
float d = distancePtSeg(points[ci*4+0], points[ci*4+2], ax, az, bx, bz);
if (d > maxd)
{
maxd = d; // 获取简化边对应的节点区间内离简化边最远的点索引
maxi = ci;
}
ci = (ci+cinc) % pn;
}
}
if (maxi != -1 && maxd > (maxError*maxError))
{
// 添加这个最远点到simplified数组中
simplified.resize(simplified.size()+4);
const int n = simplified.size()/4;
for (int j = n-1; j > i; --j)
{
// 触发了所有后续节点的移动
simplified[j*4+0] = simplified[(j-1)*4+0];
simplified[j*4+1] = simplified[(j-1)*4+1];
simplified[j*4+2] = simplified[(j-1)*4+2];
simplified[j*4+3] = simplified[(j-1)*4+3];
}
simplified[(i+1)*4+0] = points[maxi*4+0];
simplified[(i+1)*4+1] = points[maxi*4+1];
simplified[(i+1)*4+2] = points[maxi*4+2];
simplified[(i+1)*4+3] = maxi;
}
else
{
// 没有需要添加的点 处理下一条简化边
++i;
}
}
回收了一些轮廓点之后,得到了下图中的简化轮廓:
拆分过长的边界线段
为了避免在后续的三角化分中出现过于长且细的三角形,接下来还有一步后处理,将太长的简化边进行切分,这里使用了外部传递过来的maxEdgeLen作为边长度的筛选参数。
在开启这个长边拆分之前,生成的三角形如下:

开启长边拆分后,生成的三角形如下:
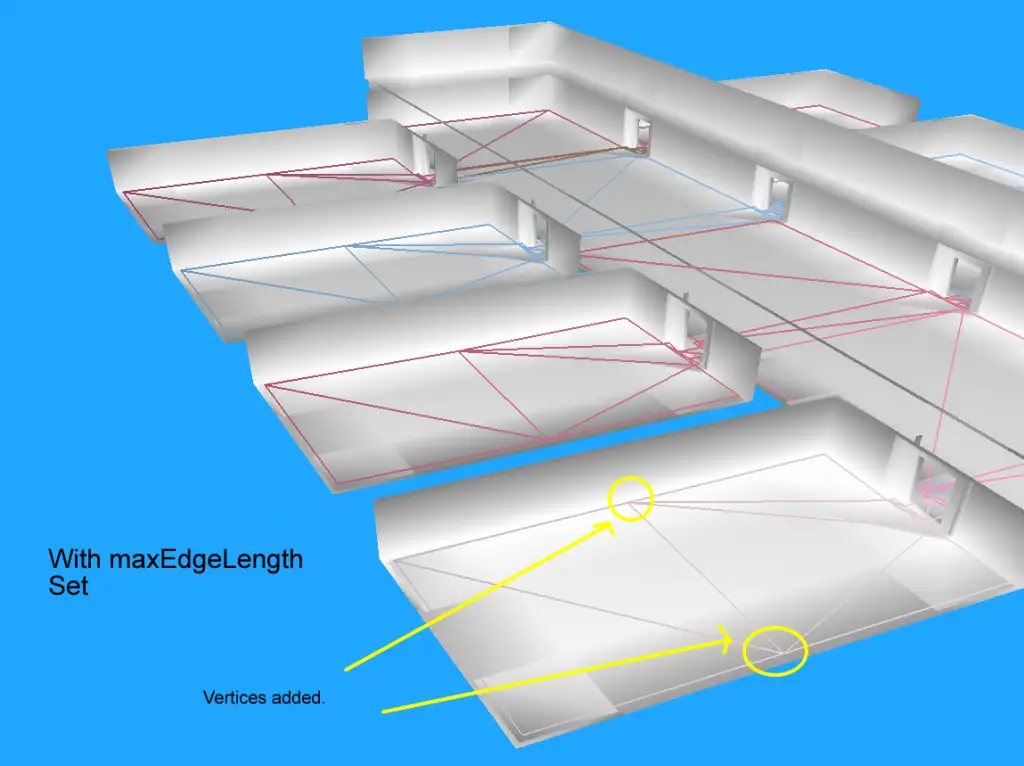
这个长边拆分执行过程与前面的回收轮廓点的流程基本差不多,也是一个递归过程:
// Split too long edges.
if (maxEdgeLen > 0 && (buildFlags & (RC_CONTOUR_TESS_WALL_EDGES|RC_CONTOUR_TESS_AREA_EDGES)) != 0)
{
for (int i = 0; i < simplified.size()/4; )
{
const int ii = (i+1) % (simplified.size()/4);
const int ax = simplified[i*4+0];
const int az = simplified[i*4+2];
const int ai = simplified[i*4+3];
const int bx = simplified[ii*4+0];
const int bz = simplified[ii*4+2];
const int bi = simplified[ii*4+3];
// Find maximum deviation from the segment.
int maxi = -1;
int ci = (ai+1) % pn;
bool tess = false;
// 靠近非连通区域的边
if ((buildFlags & RC_CONTOUR_TESS_WALL_EDGES) && (points[ci*4+3] & RC_CONTOUR_REG_MASK) == 0)
tess = true;
// 靠近不同地表的边
if ((buildFlags & RC_CONTOUR_TESS_AREA_EDGES) && (points[ci*4+3] & RC_AREA_BORDER))
tess = true;
if (tess)
{
int dx = bx - ax;
int dz = bz - az;
if (dx*dx + dz*dz > maxEdgeLen*maxEdgeLen)
{
// 如果当前边长度过长
const int n = bi < ai ? (bi+pn - ai) : (bi - ai);
if (n > 1) // 两点之间有其他轮廓点
{
// 则将边对应轮廓点区间的中间点加入
if (bx > ax || (bx == ax && bz > az))
maxi = (ai + n/2) % pn;
else
maxi = (ai + (n+1)/2) % pn;
}
}
}
// 将这个指定点添加到simplified数组 构造出两条新的边
if (maxi != -1)
{
// Add space for the new point.
// 这段代码与前一段代码块中对应内容一样 因此省略
}
else
{
++i;
}
}
}
创建基础轮廓信息
/// Represents a simple, non-overlapping contour in field space.
struct rcContour
{
int* verts; ///< Simplified contour vertex and connection data. [Size: 4 * #nverts]
int nverts; ///< The number of vertices in the simplified contour.
int* rverts; ///< Raw contour vertex and connection data. [Size: 4 * #nrverts]
int nrverts; ///< The number of vertices in the raw contour.
unsigned short reg; ///< The region id of the contour.
unsigned char area; ///< The area id of the contour.
};
rcContour* cont = &cset.conts[cset.nconts++];
cont->nverts = simplified.size()/4;
cont->verts = (int*)rcAlloc(sizeof(int)*cont->nverts*4, RC_ALLOC_PERM);
if (!cont->verts)
{
ctx->log(RC_LOG_ERROR, "rcBuildContours: Out of memory 'verts' (%d).", cont->nverts);
return false;
}
memcpy(cont->verts, &simplified[0], sizeof(int)*cont->nverts*4);
cont->nrverts = verts.size()/4;
cont->rverts = (int*)rcAlloc(sizeof(int)*cont->nrverts*4, RC_ALLOC_PERM);
if (!cont->rverts)
{
ctx->log(RC_LOG_ERROR, "rcBuildContours: Out of memory 'rverts' (%d).", cont->nrverts);
return false;
}
memcpy(cont->rverts, &verts[0], sizeof(int)*cont->nrverts*4);
cont->reg = reg;
cont->area = area;
消除空洞
在使用分水岭算法生成区域时,如果遇到一些无法寻路的小凸起,会形成一些不可寻路的小空洞。如果这个空洞的外围属于同一个区域的话,会导致区域的边界无法组成一个简单多边形,导致后续的三角形切分失败。所以区域轮廓生成的最后一部需要将这些空洞对应的多边形轮廓删除,合并到包围这个空洞的区域内。
由于我们之前计算出来的正常轮廓所存储的顶点都是顺时针的,而包围空洞的轮廓里对应的点则是逆时针的,所以判断一个轮廓是否是空洞只需要判断这个轮廓对应的多边形节点序列是否是逆时针存储的。对于一个三角形来说,其描述顶点的顺序可以通过计算相邻向量的叉积的正负来判断。在Recast采用的OpenGl坐标系中,对于(A,B,C)组成的三角形,如果(B-A)与(C-B)计算出来的叉积的Y值为正,则代表这个三角形是顺时针存储的,否则就是逆时针存储的。同时这个叉积的Y值的绝对值就是这个三角形投影在XZ平面的面积。利用叉积的这两个性质。多边形的顶点顺序则可以通过统计其内部所有三角形的叉积值的总和计算出来:
static int calcAreaOfPolygon2D(const int* verts, const int nverts)
{
int area = 0;
for (int i = 0, j = nverts-1; i < nverts; j=i++)
{
const int* vi = &verts[i*4];
const int* vj = &verts[j*4];
area += vi[0] * vj[2] - vj[0] * vi[2];
}
return (area+1) / 2;
}
下面就是一个空洞的示意图,所有B开头的点组成了一个空洞区域,而A开头的点组成了一个外围区域:
检测出空洞之后,Recast开始执行轮廓合并:
- 找到空洞的左下方顶点,在上图中为
B4 - 将外围轮廓中的每个点都与这个点连接,获取其中不与空洞相交的最短的线段对应的线段,即上图中的
A4B4, A5B4,A6B4 - 选择其中长度最短的,将空洞的节点序列拼接到原来的外围节点序列之中
所以上图经过合并处理之后,外围轮廓的节点序列为A5,A6,A1,A2,A3,A4,A5,B4,B1,B2,B3。 如果一个区域内有多个空洞的话,空洞按照其左下角顶点排序,依次合入到外围轮廓的顶点中。
讲解完空洞合并的基本原理之后,我们再来对照recast的源码来探究实现。首先遍历所有的轮廓,查看是否是逆时针存储的空洞
/ Calculate winding of all polygons.
rcScopedDelete<signed char> winding((signed char*)rcAlloc(sizeof(signed char)*cset.nconts, RC_ALLOC_TEMP));
if (!winding)
{
ctx->log(RC_LOG_ERROR, "rcBuildContours: Out of memory 'hole' (%d).", cset.nconts);
return false;
}
int nholes = 0; // 所有的空洞的数量
for (int i = 0; i < cset.nconts; ++i)
{
rcContour& cont = cset.conts[i];
// If the contour is wound backwards, it is a hole.
winding[i] = calcAreaOfPolygon2D(cont.verts, cont.nverts) < 0 ? -1 : 1;
if (winding[i] < 0)
nholes++;
}
然后记录每个外围轮廓里的空洞,这里使用了几个专门的数据结构来描述空洞信息:
struct rcContourHole// 空洞结构体
{
rcContour* contour; // 空洞对应的轮廓
int minx, minz, leftmost; // 左下角cell的 x z 以及是当前contour内的第几个节点
};
struct rcContourRegion //一个外围轮廓数据
{
rcContour* outline; // 对应的轮廓
rcContourHole* holes; // 对应的空洞数组
int nholes; // 空洞的数量
};
有了这些结构体之后,遍历之前创建的轮廓rcContour来归类:
// Collect outline contour and holes contours per region.
// We assume that there is one outline and multiple holes.
const int nregions = chf.maxRegions+1;
rcScopedDelete<rcContourRegion> regions((rcContourRegion*)rcAlloc(sizeof(rcContourRegion)*nregions, RC_ALLOC_TEMP));
if (!regions)
{
ctx->log(RC_LOG_ERROR, "rcBuildContours: Out of memory 'regions' (%d).", nregions);
return false;
}
memset(regions, 0, sizeof(rcContourRegion)*nregions);
rcScopedDelete<rcContourHole> holes((rcContourHole*)rcAlloc(sizeof(rcContourHole)*cset.nconts, RC_ALLOC_TEMP));
if (!holes)
{
ctx->log(RC_LOG_ERROR, "rcBuildContours: Out of memory 'holes' (%d).", cset.nconts);
return false;
}
memset(holes, 0, sizeof(rcContourHole)*cset.nconts);
for (int i = 0; i < cset.nconts; ++i)
{
rcContour& cont = cset.conts[i];
// 这里值为正数代表是外部轮廓 负值代表空洞
if (winding[i] > 0)
{
if (regions[cont.reg].outline)
ctx->log(RC_LOG_ERROR, "rcBuildContours: Multiple outlines for region %d.", cont.reg);
regions[cont.reg].outline = &cont;
}
else
{
regions[cont.reg].nholes++;// 当前region的空洞数量加1
}
}
int index = 0;
for (int i = 0; i < nregions; i++)
{
if (regions[i].nholes > 0) // 这里负责分配存储空间
{
regions[i].holes = &holes[index];
index += regions[i].nholes;
regions[i].nholes = 0;
}
}
for (int i = 0; i < cset.nconts; ++i)
{
rcContour& cont = cset.conts[i];
rcContourRegion& reg = regions[cont.reg];
if (winding[i] < 0)
reg.holes[reg.nholes++].contour = &cont; // 然后记录所有的空洞到对应的region上
}
其实用vector去存储每个region的空洞就可以避免最后执行两次遍历来收集空洞的情况,不过这里为了执行效率直接走预分配大数组的形式。构造每个区域对应的rcContourRegion之后,开始对每个rcContourRegion执行空洞合并的函数mergeRegionHoles:
static void mergeRegionHoles(rcContext* ctx, rcContourRegion& region)
{
// 这里设置好每个hole的左下角坐标信息
for (int i = 0; i < region.nholes; i++)
findLeftMostVertex(region.holes[i].contour, ®ion.holes[i].minx, ®ion.holes[i].minz, ®ion.holes[i].leftmost);
// 然后按照左下角坐标的递增序排序
qsort(region.holes, region.nholes, sizeof(rcContourHole), compareHoles);
int maxVerts = region.outline->nverts; // 当前region里所有的顶点数量
for (int i = 0; i < region.nholes; i++)
maxVerts += region.holes[i].contour->nverts;
// 这里存储最佳连接线信息
rcScopedDelete<rcPotentialDiagonal> diags((rcPotentialDiagonal*)rcAlloc(sizeof(rcPotentialDiagonal)*maxVerts, RC_ALLOC_TEMP));
if (!diags)
{
ctx->log(RC_LOG_WARNING, "mergeRegionHoles: Failed to allocated diags %d.", maxVerts);
return;
}
rcContour* outline = region.outline;
// Merge holes into the outline one by one.
for (int i = 0; i < region.nholes; i++)
{
rcContour* hole = region.holes[i].contour;
int index = -1;
int bestVertex = region.holes[i].leftmost;
for (int iter = 0; iter < hole->nverts; iter++) // 以最左下的节点开始遍历当前空洞里的所有点
{
// 最优连接点一定在 (j-1, j, j+1) 组成的夹角锥形内
// ..o j-1
// |
// | * best
// |
// j o-----o j+1
// :
int ndiags = 0;
const int* corner = &hole->verts[bestVertex*4];
for (int j = 0; j < outline->nverts; j++)
{
if (inCone(j, outline->nverts, outline->verts, corner))
{
// 记录所有可能的短接
int dx = outline->verts[j*4+0] - corner[0];
int dz = outline->verts[j*4+2] - corner[2];
diags[ndiags].vert = j;
diags[ndiags].dist = dx*dx + dz*dz;
ndiags++;
}
}
// 然后按照短接线段的距离来排序
qsort(diags, ndiags, sizeof(rcPotentialDiagonal), compareDiagDist);
// 寻找一个不与当前外部轮廓相交 也不与后续的空洞相交的连接
index = -1;
for (int j = 0; j < ndiags; j++)
{
const int* pt = &outline->verts[diags[j].vert*4];
bool intersect = intersectSegCountour(pt, corner, diags[i].vert, outline->nverts, outline->verts);
for (int k = i; k < region.nholes && !intersect; k++)
intersect |= intersectSegCountour(pt, corner, -1, region.holes[k].contour->nverts, region.holes[k].contour->verts);
if (!intersect)
{
index = diags[j].vert;
break;
}
}
// 如果找到了一个可行连接 则不再需要查找后续的节点
if (index != -1)
break;
// All the potential diagonals for the current vertex were intersecting, try next vertex.
bestVertex = (bestVertex + 1) % hole->nverts;
}
if (index == -1) //当前空洞合并失败 忽略
{
ctx->log(RC_LOG_WARNING, "mergeHoles: Failed to find merge points for %p and %p.", region.outline, hole);
continue;
}
if (!mergeContours(*region.outline, *hole, index, bestVertex)) // 将空洞里的点按照当前短接 插入到外部轮廓中
{
ctx->log(RC_LOG_WARNING, "mergeHoles: Failed to merge contours %p and %p.", region.outline, hole);
continue;
}
}
}
凸多边形生成
经过上个步骤,Recast生成了以连续顶点描述的多边形轮廓rcContour。但是这个多边形轮廓并不能高效的用来执行点的位置查询,而且由于可能的空洞的存在,同一个轮廓里的两个点甚至可能无法直接连通。这几个缺陷刚好被凸多边形完美解决,因为凸多边形有如下几个性质:
- 判断一个点是否在凸多边形内只需要多次向量叉积即可,次数不会大于凸多边形的顶点数量
- 根据凸的定义,凸多边形内的任意两点之间的连线一定不会与凸多边形的边界交叉,即可以保证内部任意两点都可以直接连通
- 查询一个点在哪一个凸多边形内可以使用
BVH等辅助结构来加速查询,效率很高
因此Recast会将上个步骤中生成的rcContour拆分为多个凸多边形的集合,以方便后续的寻路查询来使用。这个步骤对应的函数为rcBuildPolyMesh,其执行流程分为两步:
- 将
rcContour拆分为多个不重叠的三角形,这个过程在计算几何中称之为三角剖分Triangulation - 尽可能的合并多个相邻三角形为凸多边形
多边形轮廓的三角剖分
计算几何中最经典的三角剖分算法为Delaunay三角剖分,但是我们现在遇到的输入已经是多边形了,而不是原始的离散点的集合。针对已经构造好的多边形进行拆分主要使用耳切法Ear Clipping。
简单多边形的耳朵,是指由连续顶点V0,V1,V2组成的内部不包含其他任意顶点的三角形。在计算机几何术语中,v0与V2之间的连线 称之为多边形的对角线,点V1称之为耳尖。一个由四个顶点(或者更多)组成的多边形至少有两个不重叠的耳尖。这个特性提供了一个通过递归来解决三角化分割的方法。针对由N个定点组成的多边形,找到其耳尖,移除唯一耳尖上的顶点,此时剩余顶点组成了一个n-1个顶点的简单多边形。重复这个操作直到剩余三个顶点。这样的话会产生一个复杂度为O(N3)的算法。
由于一个多边形中的耳朵可能有很多个,Recast在每次迭代时选取其中新添加的内部边中最短的那个。具体实现上是每次将多边形轮廓中相邻的不共线的三个点连接起来组成一个三角形,检查这个三角形是否在多边形内,然后记录首尾两个端点组成的边长度。下图中的绿色虚线就是有效的新分割边,而红色虚线则是无效的分割边。

使用最短分割边的原因是,在概率上试图每次分出去一个尽可能小的三角形,以此增加最终分割的三角形的数量,进而增强分割后的信息量。
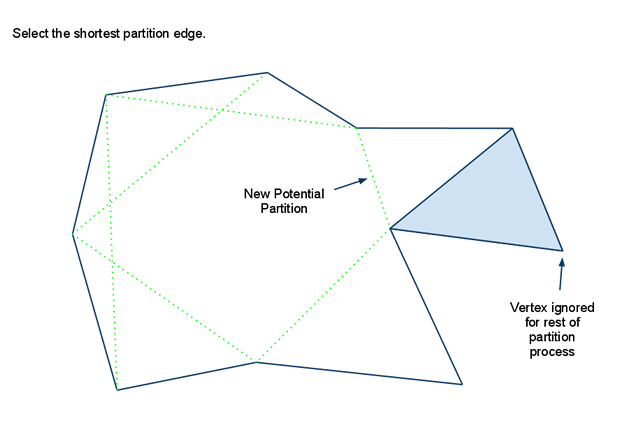
下图是迭代五次以后的结果,剩下的是一个凸多边形,不过算法流程还需要继续分割:
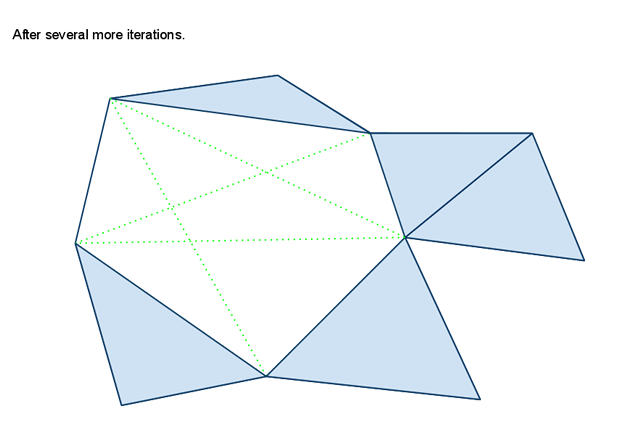
持续迭代之后,最终得到的三角剖分如下图:
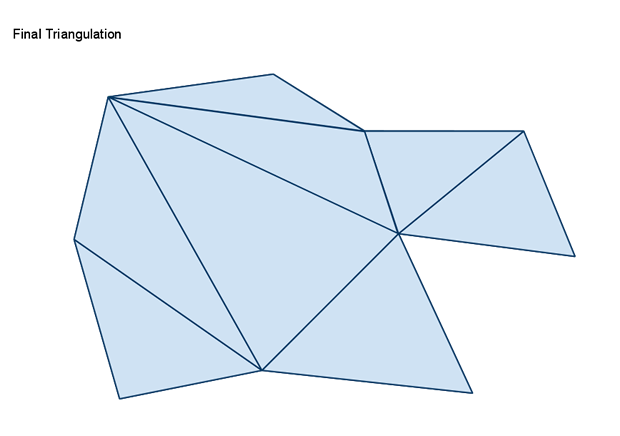
有效切分判定
上述切分过程实现上来说比较直白,唯一的难点在于如何判断一条切割边是否在多边形内,对应的函数为diagonal:
static bool diagonal(int i, int j, int n, const int* verts, int* indices)
{
return inCone(i, j, n, verts, indices) && diagonalie(i, j, n, verts, indices);
}
这个函数里的两个子函数执行的都是纯数学过程,只看代码不好理解,需要先用图形化的方法来展示其内部逻辑。
我们先来看inCone函数,这个函数负责检测(i,j)连接的线段是否完全在当前多边形的内部,这里使用的是内角算法(The Internal Angle Algorithm)来判定的。这里先需要给出内角的定义,对于多边形上的任意顶点A,获取其前序顶点B和后继顶点C,从AB旋转到AC对应的夹角为外角Exterior Angle,对应的从AC旋转到AB对应的角称之为内角Interior Angle。如下图所示红色文字所在区域为当前点的外角,绿色文字区域为当前点的内角:
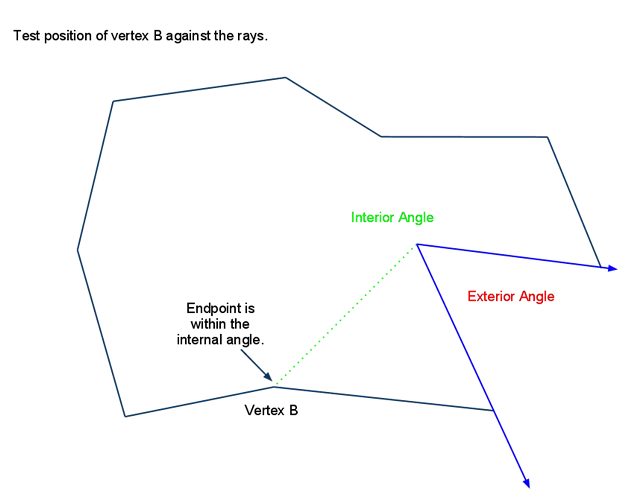
有了内角的定义之后,判断一条边是否在多边形内部只需要判断连接点B是否在连接点A的内角中。这里根据A点是否是一个凸点走两个不同的判断分支,假设C是A在多边形中的前序节点, 而D是A在多边形中的后继节点:
-
如果
A不是凸点,对应上图中的情况,此时判断C->A->B组成的三角形和B->A->D组成的三角形是否都是逆时针三角形,如果都是的话则B在内角外,此时连接线非法 -
如果
A是凸点,对应下图中的情况,此时要求判断C->A->B组成的三角形和B->A->D组成的三角形是否都是顺时针三角形,如果都是的话则B在内角内,此时连接线合法
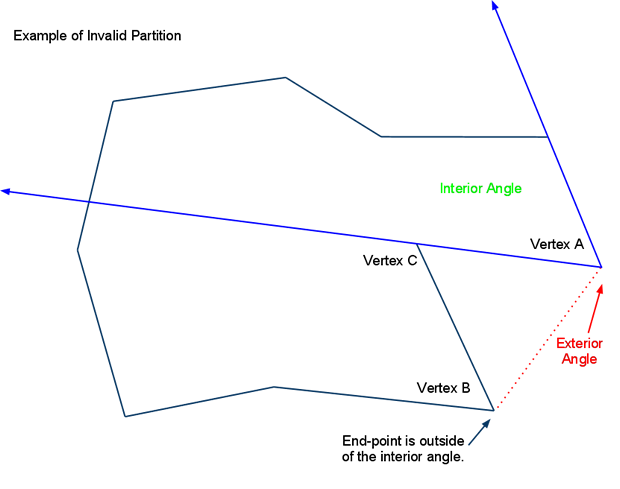
则判断是否在内角内的函数inCone的实现如下:
// 判断c点是否在a->b直线的左边 即 a b c以顺时针的方式组成一个三角形
inline bool left(const int* a, const int* b, const int* c)
{
return area2(a, b, c) < 0;
}
// 判断c点是否在a->b直线的左边或者共线
inline bool leftOn(const int* a, const int* b, const int* c)
{
return area2(a, b, c) <= 0;
}
// 判断(i,j)对角线段是否在当前多边形内
static bool inCone(int i, int j, int n, const int* verts, int* indices)
{
const int* pi = &verts[(indices[i] & 0x0fffffff) * 4]; // i点对应坐标
const int* pj = &verts[(indices[j] & 0x0fffffff) * 4]; // j点对应坐标
const int* pi1 = &verts[(indices[next(i, n)] & 0x0fffffff) * 4]; // i的后继点对应坐标
const int* pin1 = &verts[(indices[prev(i, n)] & 0x0fffffff) * 4]; // i的前序点对应坐标
// 如果i点是当前多边形的一个凸点,三个连续点组成了一个顺时针三角形
if (leftOn(pin1, pi, pi1))
// 要求 这两个三角形都是顺时针的
return left(pi, pj, pin1) && left(pj, pi, pi1);
// 要求这两个三角形不能都是顺时针的
return !(leftOn(pi, pj, pi1) && leftOn(pj, pi, pin1));
}
通过了内角判断之后,还需要调用diagonalie排除掉这条边会与当前多边形穿插的情况。此函数执行的是边相交算法(The Edge Intersection Algorithm),这个算法比较简单,判断这条分割边是否与当前多边形内的任意一条边有交叉,如果有交叉则认为不是一条有效的连接边:
// Returns T iff (v_i, v_j) is a proper internal *or* external
// diagonal of P, *ignoring edges incident to v_i and v_j*.
static bool diagonalie(int i, int j, int n, const int* verts, int* indices)
{
const int* d0 = &verts[(indices[i] & 0x0fffffff) * 4];
const int* d1 = &verts[(indices[j] & 0x0fffffff) * 4];
// For each edge (k,k+1) of P
for (int k = 0; k < n; k++)
{
int k1 = next(k, n);
// Skip edges incident to i or j
if (!((k == i) || (k1 == i) || (k == j) || (k1 == j)))
{
const int* p0 = &verts[(indices[k] & 0x0fffffff) * 4];
const int* p1 = &verts[(indices[k1] & 0x0fffffff) * 4];
if (vequal(d0, p0) || vequal(d1, p0) || vequal(d0, p1) || vequal(d1, p1))
continue;
// 线段相交判断
if (intersect(d0, d1, p0, p1))
return false;
}
}
return true;
}
在了解了有效连接边的判定之后,耳切法的执行流程如下:
static int triangulate(int n, const int* verts, int* indices, int* tris)
{
int ntris = 0;
int* dst = tris;
for (int i = 0; i < n; i++)
{
int i1 = next(i, n);
int i2 = next(i1, n);
// 如果i->i2的连接线是有效的 则标记i1是一个耳尖
if (diagonal(i, i2, n, verts, indices))
indices[i1] |= 0x80000000;
}
while (n > 3)
{
// 每一轮循环寻找剩下的最短有效连接线
int minLen = -1;
int mini = -1;
for (int i = 0; i < n; i++)
{
int i1 = next(i, n);
if (indices[i1] & 0x80000000)
{
const int* p0 = &verts[(indices[i] & 0x0fffffff) * 4];
const int* p2 = &verts[(indices[next(i1, n)] & 0x0fffffff) * 4];
int dx = p2[0] - p0[0];
int dy = p2[2] - p0[2];
int len = dx*dx + dy*dy;
if (minLen < 0 || len < minLen)
{
minLen = len;
mini = i;
}
}
}
if (mini == -1)
{
// 找不到可能的耳尖,可能是因为线段重叠了 放松不共线的需求再寻找一次
// We might get here because the contour has overlapping segments, like this:
//
// A o-o=====o---o B
// / |C D| \.
// o o o o
// : : : :
// We'll try to recover by loosing up the inCone test a bit so that a diagonal
// like A-B or C-D can be found and we can continue.
minLen = -1;
mini = -1;
for (int i = 0; i < n; i++)
{
int i1 = next(i, n);
int i2 = next(i1, n);
if (diagonalLoose(i, i2, n, verts, indices))
{
const int* p0 = &verts[(indices[i] & 0x0fffffff) * 4];
const int* p2 = &verts[(indices[next(i2, n)] & 0x0fffffff) * 4];
int dx = p2[0] - p0[0];
int dy = p2[2] - p0[2];
int len = dx*dx + dy*dy;
if (minLen < 0 || len < minLen)
{
minLen = len;
mini = i;
}
}
}
if (mini == -1)
{
// The contour is messed up. This sometimes happens
// if the contour simplification is too aggressive.
return -ntris;
}
}
// 找到了一个可以分割的三角形
int i = mini;
int i1 = next(i, n);
int i2 = next(i1, n);
*dst++ = indices[i] & 0x0fffffff;
*dst++ = indices[i1] & 0x0fffffff;
*dst++ = indices[i2] & 0x0fffffff;
ntris++;
// Removes P[i1] by copying P[i+1]...P[n-1] left one index.
n--;
for (int k = i1; k < n; k++)
indices[k] = indices[k+1];
if (i1 >= n) i1 = 0;
i = prev(i1,n);
// 更新连接线的两个点是否是耳尖
if (diagonal(prev(i, n), i1, n, verts, indices))
indices[i] |= 0x80000000;
else
indices[i] &= 0x0fffffff;
if (diagonal(i, next(i1, n), n, verts, indices))
indices[i1] |= 0x80000000;
else
indices[i1] &= 0x0fffffff;
}
// Append the remaining triangle.
*dst++ = indices[0] & 0x0fffffff;
*dst++ = indices[1] & 0x0fffffff;
*dst++ = indices[2] & 0x0fffffff;
ntris++;
return ntris;
}
三角形合并
上一个步骤执行之后,我们就得到了一个完全用三角形进行描述的场景可行走表面,这份数据已经可以用来高效的执行寻路操作。n个三角形需要3*n个节点索引来描述,而合并为一个大的凸多边形之后只需要n+2个节点索引即可,内存降低到了原来的1/3。所以为了进一步优化内存占用,Recast会尝试将同一个区域内的多个三角形合并为一个凸多边形。
由于三角形合并之后会形成凸多边形,而凸多边形还可以进一步与其他凸多边形进行合并,所以Recast实际执行的是凸多边形的合并(三角形是最简单的凸多边形)。其合并流程可以简化描述为下面的四个步骤:
- 将当前区域内的所有三角形转换为待合并的多边形集合
S
// Build initial polygons.
int npolys = 0;
memset(polys, 0xff, maxVertsPerCont*nvp*sizeof(unsigned short));
for (int j = 0; j < ntris; ++j)
{
int* t = &tris[j*3];
if (t[0] != t[1] && t[0] != t[2] && t[1] != t[2])
{
polys[npolys*nvp+0] = (unsigned short)indices[t[0]];
polys[npolys*nvp+1] = (unsigned short)indices[t[1]];
polys[npolys*nvp+2] = (unsigned short)indices[t[2]];
npolys++;
}
}
- 遍历
S中的两个可以合并的多边形元素对(A,B),选取其中共享边最长的进行合并,形成新的凸多边形C - 从
S中删除A, B两个凸多边形,加入凸多边形C - 重复步骤
2直到没有可选合并
for(;;)
{
// Find best polygons to merge.
int bestMergeVal = 0;
int bestPa = 0, bestPb = 0, bestEa = 0, bestEb = 0;
// 遍历所有的多边形元素对
for (int j = 0; j < npolys-1; ++j)
{
unsigned short* pj = &polys[j*nvp];
for (int k = j+1; k < npolys; ++k)
{
unsigned short* pk = &polys[k*nvp];
int ea, eb;
int v = getPolyMergeValue(pj, pk, mesh.verts, ea, eb, nvp); // 计算共享边长度 如果合并后不是凸多边形 返回负值
if (v > bestMergeVal)
{
bestMergeVal = v;
bestPa = j;
bestPb = k;
bestEa = ea;
bestEb = eb;
}
}
}
if (bestMergeVal > 0)
{
// 找到 一个可合并边 还是合并
unsigned short* pa = &polys[bestPa*nvp];
unsigned short* pb = &polys[bestPb*nvp];
mergePolyVerts(pa, pb, bestEa, bestEb, tmpPoly, nvp);
unsigned short* lastPoly = &polys[(npolys-1)*nvp];
if (pb != lastPoly)
memcpy(pb, lastPoly, sizeof(unsigned short)*nvp);
npolys--;
}
else
{
// Could not merge any polygons, stop.
break;
}
}
上面过程中的核心逻辑在于函数getPolyMergeValue,此函数判定A,B两个凸多边形是否可以合并,其判断规则如下:
-
A,B两者共享一条边 -
A,B合并之后形成的C需要是凸多边形
是否共享一条边的检测非常容易,两个凸多边形做一下边集合的交集即可。但是判定两个凸多边形合并成为的新多边形是否还是凸多边形就比较麻烦了,这里我们继续使用前面介绍的内角算法,判定共享边上的两个顶点对应的内角是否是小于等于180度的,等价于判断:对于共享边的任意顶点A,获取其在新多边形的前序顶点B和后续顶点C,判断B->C是一条有效的连接边。这部分的判定可以直接复用我们在前面一节中介绍的有效连接边判定,所以这里就不再做介绍。
然后Recast为了控制凸多边形的形状,还额外添加了一条限制:合并后的凸多边形的节点数量不得超过传入的参数maxVertsPerPoly,也就是上面代码中的nvp变量。因为凸多边形的绝大部分操作时间复杂度与节点数量成正相关,这样就避免后续使用中出现奇怪的巨型多边形引发的过多时间消耗。最终getPolyMergeValue的定义如下:
static int getPolyMergeValue(unsigned short* pa, unsigned short* pb,
const unsigned short* verts, int& ea, int& eb,
const int nvp)
{
const int na = countPolyVerts(pa, nvp);
const int nb = countPolyVerts(pb, nvp);
// 如果合并后的多边形节点数量大于最大节点数量限制nvp 则禁止合并
if (na+nb-2 > nvp)
return -1;
// Check if the polygons share an edge.
ea = -1;
eb = -1;
// 计算出共享边
for (int i = 0; i < na; ++i)
{
unsigned short va0 = pa[i];
unsigned short va1 = pa[(i+1) % na];
if (va0 > va1)
rcSwap(va0, va1);
for (int j = 0; j < nb; ++j)
{
unsigned short vb0 = pb[j];
unsigned short vb1 = pb[(j+1) % nb];
if (vb0 > vb1)
rcSwap(vb0, vb1);
if (va0 == vb0 && va1 == vb1)
{
ea = i;
eb = j;
break;
}
}
}
// 没有共享边 返回负值
if (ea == -1 || eb == -1)
return -1;
// 判断共享边两个顶点作为中间节点的顺时针连续三个节点构成的三角形是否是顺时针三角形
// 任何一个不是顺时针三角形都代表非凸 返回负值
unsigned short va, vb, vc;
va = pa[(ea+na-1) % na];
vb = pa[ea];
vc = pb[(eb+2) % nb];
if (!uleft(&verts[va*3], &verts[vb*3], &verts[vc*3]))
return -1;
va = pb[(eb+nb-1) % nb];
vb = pb[eb];
vc = pa[(ea+2) % na];
if (!uleft(&verts[va*3], &verts[vb*3], &verts[vc*3]))
return -1;
va = pa[ea];
vb = pa[(ea+1)%na];
int dx = (int)verts[va*3+0] - (int)verts[vb*3+0];
int dy = (int)verts[va*3+2] - (int)verts[vb*3+2];
// 通过判断 返回边长度
return dx*dx + dy*dy;
}
Recast使用RcPolyMesh的结构体来存储当前场景里的所有多边形:
struct rcPolyMesh
{
rcPolyMesh();
~rcPolyMesh();
unsigned short* verts; ///< The mesh vertices. [Form: (x, y, z) * #nverts]
unsigned short* polys; ///< Polygon and neighbor data. [Length: #maxpolys * 2 * #nvp]
unsigned short* regs; ///< The region id assigned to each polygon. [Length: #maxpolys]
unsigned short* flags; ///< The user defined flags for each polygon. [Length: #maxpolys]
unsigned char* areas; ///< The area id assigned to each polygon. [Length: #maxpolys]
int nverts; ///< The number of vertices.
int npolys; ///< The number of polygons.
int maxpolys; ///< The number of allocated polygons.
int nvp; ///< The maximum number of vertices per polygon.
float bmin[3]; ///< The minimum bounds in world space. [(x, y, z)]
float bmax[3]; ///< The maximum bounds in world space. [(x, y, z)]
float cs; ///< The size of each cell. (On the xz-plane.)
float ch; ///< The height of each cell. (The minimum increment along the y-axis.)
int borderSize; ///< The AABB border size used to generate the source data from which the mesh was derived.
float maxEdgeError; ///< The max error of the polygon edges in the mesh.
};
所以在上一节对每个区域进行凸多边形合并之后,需要将此区域内的所有凸多边形数据存储到这个全局的rcPolyMesh内:
// Store polygons.
for (int j = 0; j < npolys; ++j)
{
unsigned short* p = &mesh.polys[mesh.npolys*nvp*2];
unsigned short* q = &polys[j*nvp];
for (int k = 0; k < nvp; ++k)
p[k] = q[k];
mesh.regs[mesh.npolys] = cont.reg;
mesh.areas[mesh.npolys] = cont.area;
mesh.npolys++;
if (mesh.npolys > maxTris)
{
ctx->log(RC_LOG_ERROR, "rcBuildPolyMesh: Too many polygons %d (max:%d).", mesh.npolys, maxTris);
return false;
}
}
凸多边形邻居信息存储
构造完成凸多边形之后,为了方便使用凸多边形寻路时快速的获取当前凸多边形的邻居,Recast在生成rcPolyMesh时也会顺带的将多边形的邻居数据计算好,存储在polys字段中。每个poly会在这个数组中使用short[2*maxVertsPerPoly]这么大的存储区域来描述,[0, maxVertsPerPoly)中存储的是当前凸多边形的顶点索引,而[maxVertsPerPoly, 2*maxVertsPerPoly)区域存储的是其邻居多边形的id列表。这个计算邻接多边形的函数为buildMeshAdjacency。其实这个函数执行流程很简单,其内部包含了两个大循环:
- 第一个循环遍历每个
Poly的每条边,构造下面的结构体
struct rcEdge
{
unsigned short vert[2]; // 边的两个点的索引
unsigned short polyEdge[2]; // 邻接的两个多边形的边的索引
unsigned short poly[2]; // 邻接的两个多边形的索引
};
// 遍历每个poly的每个点
for (int i = 0; i < npolys; ++i)
{
unsigned short* t = &polys[i*vertsPerPoly*2];
for (int j = 0; j < vertsPerPoly; ++j)
{
if (t[j] == RC_MESH_NULL_IDX) break;
unsigned short v0 = t[j];
// 获取v0开始的顺时针边的另外一个顶点
unsigned short v1 = (j+1 >= vertsPerPoly || t[j+1] == RC_MESH_NULL_IDX) ? t[0] : t[j+1];
if (v0 < v1)
{
rcEdge& edge = edges[edgeCount];
edge.vert[0] = v0;
edge.vert[1] = v1;
edge.poly[0] = (unsigned short)i;
edge.polyEdge[0] = (unsigned short)j;
edge.poly[1] = (unsigned short)i;
edge.polyEdge[1] = 0;
// 这里的firstEdge和nextEdge 为每个顶点都构造出来了一个边索引的list
nextEdge[edgeCount] = firstEdge[v0];
firstEdge[v0] = (unsigned short)edgeCount;
edgeCount++;
}
}
}
这里rcEdge里只填充了一半信息,剩余信息等待下面的大循环来填充。
- 第二次遍历所有
poly的所有边,过滤出vert[0]>vert[1]的,然后查询之前以vert[0],vert[1]构造好一半信息的rcEdge,填充当前多边形的id和当前边的索引:
for (int i = 0; i < npolys; ++i)
{
unsigned short* t = &polys[i*vertsPerPoly*2];
for (int j = 0; j < vertsPerPoly; ++j)
{
if (t[j] == RC_MESH_NULL_IDX) break;
unsigned short v0 = t[j];
unsigned short v1 = (j+1 >= vertsPerPoly || t[j+1] == RC_MESH_NULL_IDX) ? t[0] : t[j+1];
if (v0 > v1)
{
// 遍历v1对应的链表 找到当前edge 填充剩余信息
for (unsigned short e = firstEdge[v1]; e != RC_MESH_NULL_IDX; e = nextEdge[e])
{
rcEdge& edge = edges[e];
if (edge.vert[1] == v0 && edge.poly[0] == edge.poly[1])
{
edge.poly[1] = (unsigned short)i;
edge.polyEdge[1] = (unsigned short)j;
break;
}
}
}
}
}
- 查询信息填充完整的
rcEdge,以这个作为共享边记录下当前的邻接多边形到指定的边索引里:
// Store adjacency
for (int i = 0; i < edgeCount; ++i)
{
const rcEdge& e = edges[i];
if (e.poly[0] != e.poly[1])
{
unsigned short* p0 = &polys[e.poly[0]*vertsPerPoly*2];
unsigned short* p1 = &polys[e.poly[1]*vertsPerPoly*2];
p0[vertsPerPoly + e.polyEdge[0]] = e.poly[1];
p1[vertsPerPoly + e.polyEdge[1]] = e.poly[0];
}
}
至此整个rcPolyMesh创建完成。
创建细节网格
在前面的很多步骤中,我们基本只使用了点在XZ平面上的投影坐标,例如在平滑轮廓的时候只是为了匹配在XZ平面上的轮廓。这些忽略Y轴坐标的计算会导致最后的rcPolyMesh中的多边形形状与原始场景的地表形状在Y轴上出现很大差异,影响后续的在三维空间中查询给定点对应的表面凸多边形计算。下图中的楼梯部分就是典型的可行走区域Y轴高度不匹配:
这种Y轴高度不匹配会引发寻路时模型与地表出现严重的穿插状况,所以Recast还会对生成的rcPolyMesh做一次高度拟合操作,生成一个更加贴合地表的rcDetailMesh:

为了添加高度细节,我们需要能够确定一个多边形的表面是否它的开放高度场的span距离太远,高度补丁rcHeightPatch即用于此目的:
struct rcHeightPatch
{
inline rcHeightPatch() : data(0), xmin(0), ymin(0), width(0), height(0) {}
inline ~rcHeightPatch() { rcFree(data); }
unsigned short* data;
int xmin, ymin, width, height;
};
结构体中的data字段是一个数组,存储了与当前多边形相交的每个开放高度场网格位置的以cellHeight计算的预期高度。xmin, ymin, width, height则存储了当前多边形的AABB包围盒形状:
执行细节网格添加的函数为rcBuildPolyMeshDetail, 其核心逻辑为:
for (int i = 0; i < mesh.npolys; ++i)
{
const unsigned short* p = &mesh.polys[i*nvp*2];
// 将存储与当前多边形里的所有顶点 复制一份到poly数组中
int npoly = 0;
for (int j = 0; j < nvp; ++j)
{
if(p[j] == RC_MESH_NULL_IDX) break;
const unsigned short* v = &mesh.verts[p[j]*3];
poly[j*3+0] = v[0]*cs;
poly[j*3+1] = v[1]*ch;
poly[j*3+2] = v[2]*cs;
npoly++;
}
// 计算当前poly的aabb
hp.xmin = bounds[i*4+0];
hp.ymin = bounds[i*4+2];
hp.width = bounds[i*4+1]-bounds[i*4+0];
hp.height = bounds[i*4+3]-bounds[i*4+2];
// 利用原来存储的高度场数据来更新hp.data 即当前多边形AABB内所有cell与当前多边形相交点的高度
getHeightData(ctx, chf, p, npoly, mesh.verts, borderSize, hp, arr, mesh.regs[i]);
// 然后开始进行采样 补充节点
int nverts = 0;
if (!buildPolyDetail(ctx, poly, npoly,
sampleDist, sampleMaxError,
heightSearchRadius, chf, hp,
verts, nverts, tris,
edges, samples))
{
return false;
}
}
记录多边形AABB的高度数据
这里的getHeightData里用三层循环来计算AABB内所有cell对应的体素高度:
for (int hy = 0; hy < hp.height; hy++)
{
int y = hp.ymin + hy + bs;
for (int hx = 0; hx < hp.width; hx++)
{
int x = hp.xmin + hx + bs;
const rcCompactCell& c = chf.cells[x + y*chf.width];
for (int i = (int)c.index, ni = (int)(c.index + c.count); i < ni; ++i)
{
const rcCompactSpan& s = chf.spans[i];
if (s.reg == region)
{
// Store height
hp.data[hx + hy*hp.width] = s.y;
empty = false;
// 检查当前span是否在边界上
bool border = false;
for (int dir = 0; dir < 4; ++dir)
{
if (rcGetCon(s, dir) != RC_NOT_CONNECTED)
{
const int ax = x + rcGetDirOffsetX(dir);
const int ay = y + rcGetDirOffsetY(dir);
const int ai = (int)chf.cells[ax + ay*chf.width].index + rcGetCon(s, dir);
const rcCompactSpan& as = chf.spans[ai];
if (as.reg != region)
{
border = true;
break;
}
}
}
if (border)
push3(queue, x, y, i);
break;
}
}
}
}
前面两层循环负责获取对应的cell,最后一层循环从低到高遍历当前cell的所有span,遇到第一个属于当前区域的则取这个span的高度作为cell与当前多边形的交叉点高度。如果当前cell找不到与当前poly同region的span,则需要从这个cell的spans中找到离当前region最近的一个span作为相交点的高度。这里实现上采用了近似的手法,将每个当前已经计算好高度的span依次洪范传播,某个未设置高度的cell被第一次洪范到时,选取当前洪范过来的span作为相交span。而洪范时采用的初始队列则为原始区域中所有在边界上的span,也就是上面计算border的代码,如果发现当前span在边界上,则把当前span加入到queue中等待后续的洪范处理。
static const int RETRACT_SIZE = 256;
int head = 0;
while (head*3 < queue.size())
{
int cx = queue[head*3+0];
int cy = queue[head*3+1];
int ci = queue[head*3+2];
head++;
if (head >= RETRACT_SIZE) // 对std::queue拙劣的模仿
{
head = 0;
if (queue.size() > RETRACT_SIZE*3)
memmove(&queue[0], &queue[RETRACT_SIZE*3], sizeof(int)*(queue.size()-RETRACT_SIZE*3));
queue.resize(queue.size()-RETRACT_SIZE*3);
}
const rcCompactSpan& cs = chf.spans[ci]; //当前要洪范的span
for (int dir = 0; dir < 4; ++dir) // 四个方向以此洪范
{
if (rcGetCon(cs, dir) == RC_NOT_CONNECTED) continue;
const int ax = cx + rcGetDirOffsetX(dir);
const int ay = cy + rcGetDirOffsetY(dir);
const int hx = ax - hp.xmin - bs;
const int hy = ay - hp.ymin - bs;
if ((unsigned int)hx >= (unsigned int)hp.width || (unsigned int)hy >= (unsigned int)hp.height)
continue;
if (hp.data[hx + hy*hp.width] != RC_UNSET_HEIGHT) //如果此方向邻居的高度已经设置过了 则忽略
continue;
const int ai = (int)chf.cells[ax + ay*chf.width].index + rcGetCon(cs, dir);
const rcCompactSpan& as = chf.spans[ai];
hp.data[hx + hy*hp.width] = as.y; // 设置当前cell对应高度为当前span的高度
push3(queue, ax, ay, ai); // 放入队列 等待后续洪范
}
}
对多边形的边添加采样点
有了高度补丁数据之后,开始对原来的多边形的边按照detailSampleDist进行分段:
每段的终点都执行一次高度查询,计算当前点的高度与采样出来的高度之间的差值:
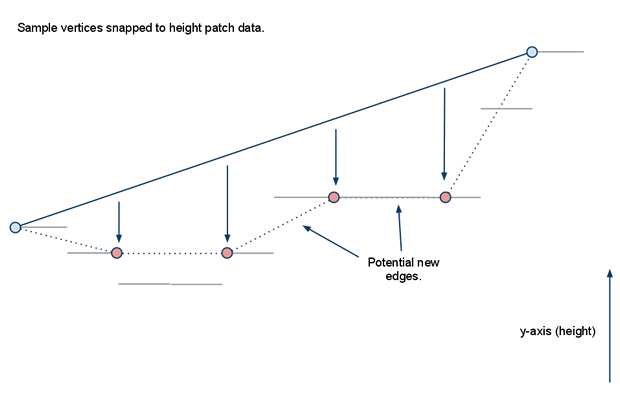
选取其中差值最大的点,如果这个点的插值大于最大偏差detailSampleMaxError,则考虑在这个高度上增加一个新的节点:
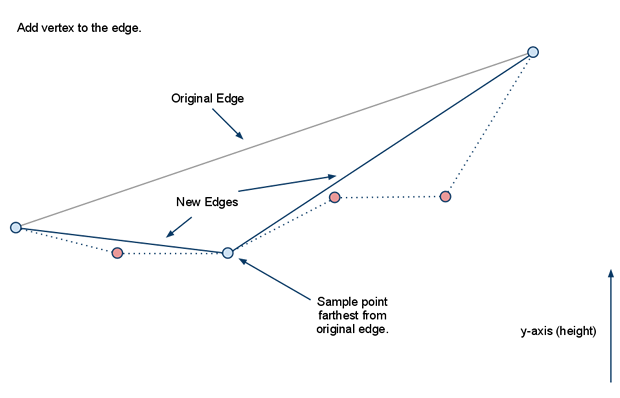
如果还有其他点的高度差值大于detailSampleMaxError,则继续执行新点的增加过程:
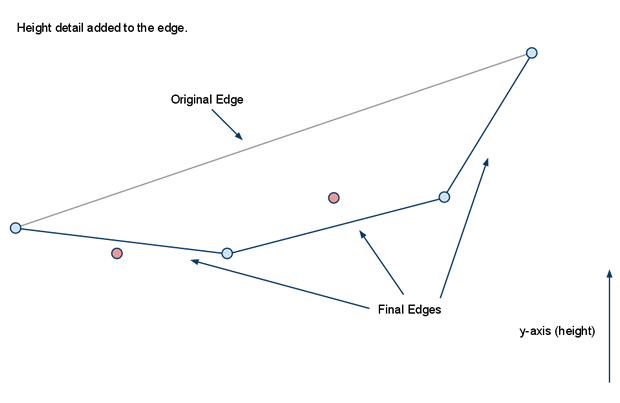
最后生成的细节网格与真正的地表高度贴合度与detailSampleMaxError成反比,下面的三张图分别代表detailSampleMaxError从大到小时的细节网格形状,表面是越来越贴合,但是三角形数量也是越来越多:
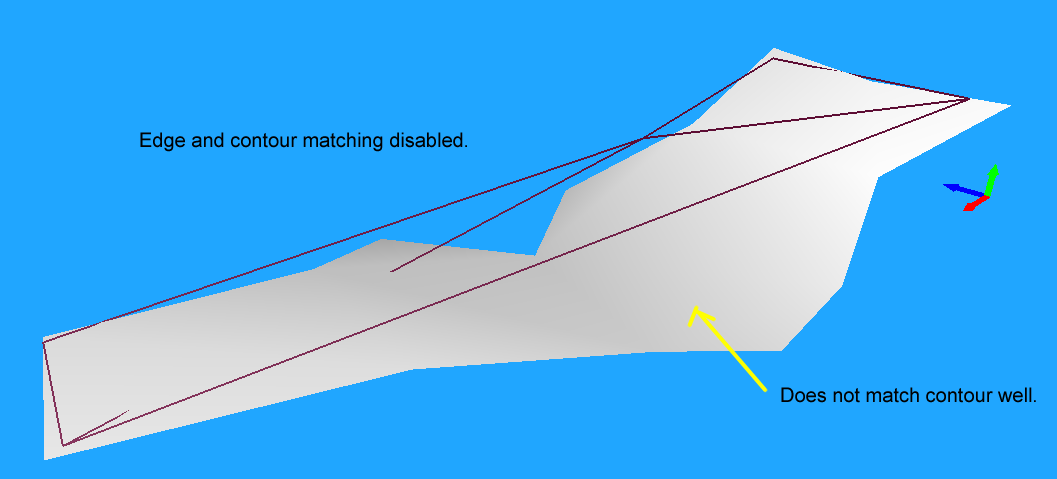
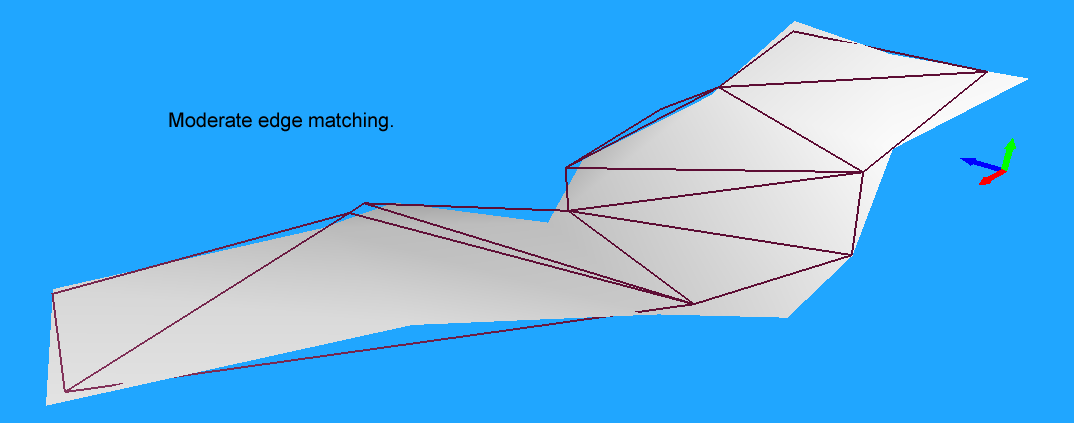
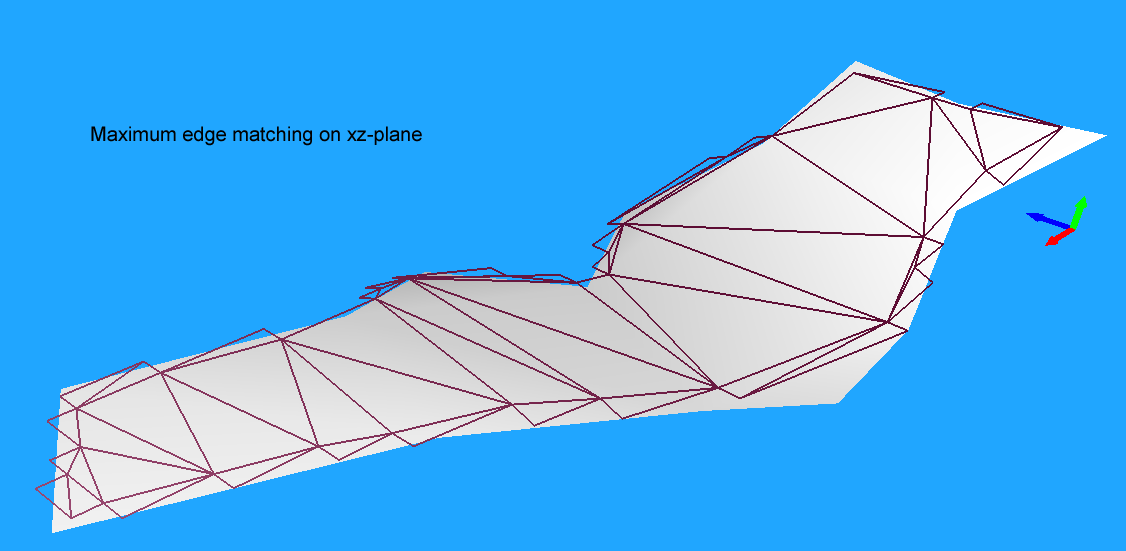
这部分对应的代码在:
// float in[nin*3] 代表原始多边形的节点数组
if (sampleDist > 0)
{
for (int i = 0, j = nin-1; i < nin; j=i++)
{
const float* vj = &in[j*3];
const float* vi = &in[i*3];
bool swapped = false;
// 这里让相邻的两个点按照std::pair(x, z)的顺序来重排序
if (std::abs(vj[0]-vi[0]) < 1e-6f)
{
if (vj[2] > vi[2])
{
rcSwap(vj,vi);
swapped = true;
}
}
else
{
if (vj[0] > vi[0])
{
rcSwap(vj,vi);
swapped = true;
}
}
// Create samples along the edge.
float dx = vi[0] - vj[0];
float dy = vi[1] - vj[1];
float dz = vi[2] - vj[2];
float d = std::sqrt(dx*dx + dz*dz);
int nn = 1 + (int)std::floor(d/sampleDist); // 采样个数
if (nn >= MAX_VERTS_PER_EDGE) nn = MAX_VERTS_PER_EDGE-1;
if (nverts+nn >= MAX_VERTS)
nn = MAX_VERTS-1-nverts;
// 记录每个采样点的高度
for (int k = 0; k <= nn; ++k)
{
float u = (float)k/(float)nn;
float* pos = &edge[k*3];
pos[0] = vj[0] + dx*u;
pos[1] = vj[1] + dy*u;
pos[2] = vj[2] + dz*u;
pos[1] = getHeight(pos[0],pos[1],pos[2], cs, ics, chf.ch, heightSearchRadius, hp)*chf.ch;
}
// idx 相邻两个点代表搜索区间
int idx[MAX_VERTS_PER_EDGE] = {0,nn};
int nidx = 2;
for (int k = 0; k < nidx-1; )
{
const int a = idx[k];
const int b = idx[k+1];
const float* va = &edge[a*3];
const float* vb = &edge[b*3];
// 找到偏移值最大的采样点
float maxd = 0;
int maxi = -1;
for (int m = a+1; m < b; ++m)
{
float dev = distancePtSeg(&edge[m*3],va,vb);
if (dev > maxd)
{
maxd = dev;
maxi = m;
}
}
// 如果最大的偏移值大于sampleMaxError
if (maxi != -1 && maxd > rcSqr(sampleMaxError))
{
// 则插入这个采样点到节点列表中 这样会构造出两个新的搜索区间
for (int m = nidx; m > k; --m)
idx[m] = idx[m-1];
idx[k+1] = maxi;
nidx++;
// 当前的区间变小了,下一次继续检查当前区间
}
else//当前区间内没有需要添加的点 继续到下一个区间
{
++k;
}
}
hull[nhull++] = j;//这个数组存储当前多边形最终的点
// 根据是否换向 插入当前边的所有采样后的点
if (swapped)
{
for (int k = nidx-2; k > 0; --k)
{
rcVcopy(&verts[nverts*3], &edge[idx[k]*3]);
hull[nhull++] = nverts;
nverts++;
}
}
else
{
for (int k = 1; k < nidx-1; ++k)
{
rcVcopy(&verts[nverts*3], &edge[idx[k]*3]);
hull[nhull++] = nverts;
nverts++;
}
}
}
}
重新三角化
在执行完上面这部分添加采样点的操作之后,hull中存储的节点数量可能会超过原来规定的上限,所以需要对这个凸多边形进行三角剖分,但是不会再合并为多个凸多边形。这里可以复用之前介绍过的耳切法流程拆分为小三角形,但是由于目前我们已经保证了当前的输入已经是一个凸多边形了,不需要再做那么多连接边是否在多边形内的判断了。所以这里直接使用一个贪心的方法对凸多边形进行三角剖分:
- 选取分割后周长最短的三角形作为第一个分割三角形
- 对于每个被切分出去的三角形,获取这个三角形连接边上的两个点,计算这两个点对应的新的切分三角形的周长,选择其中周长最短的三角形做切分
- 重复上面的过程2,直到无法再切分
执行上述流程的函数为triangulateHull,对应的代码很简短,理解起来也没啥难度:
static void triangulateHull(const int /*nverts*/, const float* verts, const int nhull, const int* hull, const int nin, rcIntArray& tris)
{
int start = 0, left = 1, right = nhull-1;
// 本次循环先找到分割后周长对端的三角形
float dmin = RC_REAL_MAX;
for (int i = 0; i < nhull; i++)
{
if (hull[i] >= nin) continue; // Ears are triangles with original vertices as middle vertex while others are actually line segments on edges
int pi = prev(i, nhull);
int ni = next(i, nhull);
const float* pv = &verts[hull[pi]*3];
const float* cv = &verts[hull[i]*3];
const float* nv = &verts[hull[ni]*3];
const float d = vdist2(pv,cv) + vdist2(cv,nv) + vdist2(nv,pv);
if (d < dmin)
{
start = i;
left = ni;
right = pi;
dmin = d;
}
}
// 添加这个三角形到结果中
tris.push(hull[start]);
tris.push(hull[left]);
tris.push(hull[right]);
tris.push(0);
// 只要剩下的点大于3个 就持续切分
while (next(left, nhull) != right)
{
// 计算连接边两个顶点对应的三角形哪个周长更短
int nleft = next(left, nhull);
int nright = prev(right, nhull);
const float* cvleft = &verts[hull[left]*3];
const float* nvleft = &verts[hull[nleft]*3];
const float* cvright = &verts[hull[right]*3];
const float* nvright = &verts[hull[nright]*3];
const float dleft = vdist2(cvleft, nvleft) + vdist2(nvleft, cvright);
const float dright = vdist2(cvright, nvright) + vdist2(cvleft, nvright);
// 选取周长更短的作为结果三角形
if (dleft < dright)
{
tris.push(hull[left]);
tris.push(hull[nleft]);
tris.push(hull[right]);
tris.push(0);
left = nleft;
}
else
{
tris.push(hull[left]);
tris.push(hull[nright]);
tris.push(hull[right]);
tris.push(0);
right = nright;
}
}
}
添加细节顶点以匹配高度
上述操作之后,Recast保证了细节网格上的三角形任意一个点都不会与真实高度相差大于sampleMaxError,但是对于三角形内部的任意一点其与真实地表高度的差值是没有保证的。为了进一步贴合地表,Recast还对这个多边形的XZ投影进行了以detailSampleDist为粒度的网格采样,如果采样点的真实高度与通过所在三角形计算出来的高度差值较大,则添加这个采样点,同时将所在三角形切分为三个新的小三角形。
整个网格采样并添加点的流程可以用图形来表示,下图就是初始的网格采样点:
然后丢弃不在当前多边形内的采样点:
上述两个部分的代码如下:
// Create sample locations in a grid.
float bmin[3], bmax[3];
rcVcopy(bmin, in);
rcVcopy(bmax, in);
for (int i = 1; i < nin; ++i)
{
rcVmin(bmin, &in[i*3]);
rcVmax(bmax, &in[i*3]);
}
int x0 = (int)std::floor(bmin[0]/sampleDist);
int x1 = (int)std::ceil(bmax[0]/sampleDist);
int z0 = (int)std::floor(bmin[2]/sampleDist);
int z1 = (int)std::ceil(bmax[2]/sampleDist);
samples.clear();
for (int z = z0; z < z1; ++z)
{
for (int x = x0; x < x1; ++x)
{
float pt[3];
pt[0] = x*sampleDist;
pt[1] = (bmax[1]+bmin[1])*0.5f;
pt[2] = z*sampleDist;
// 丢弃不在多边形内的点
if (distToPoly(nin,in,pt) > -sampleDist/2) continue;
samples.push(x);
samples.push(getHeight(pt[0], pt[1], pt[2], cs, ics, chf.ch, heightSearchRadius, hp));//获取当前点的高度
samples.push(z);
samples.push(0); // Not added
}
}
然后选取剩下的点中高度差最大的点,如果这个的高度差大于了detailSampleMaxError,则往多边形节点集合中添加这个点:
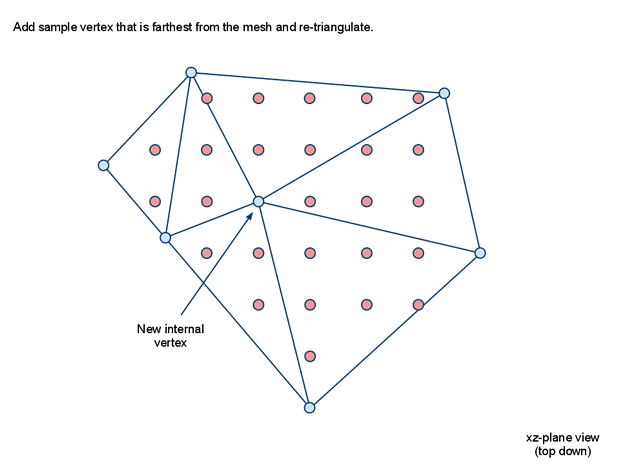
并重新执行三角剖分,不过这里使用的是最知名的delaunay三角剖分:

const int nsamples = samples.size()/4;
for (int iter = 0; iter < nsamples; ++iter)
{
if (nverts >= MAX_VERTS)
break;
// Find sample with most error.
float bestpt[3] = {0,0,0};
float bestd = 0;
int besti = -1;
// 获取剩余采样点中高度差值最大的
for (int i = 0; i < nsamples; ++i)
{
const int* s = &samples[i*4];
if (s[3]) continue; // 第四个分量代表已经添加过了
float pt[3];
// The sample location is jittered to get rid of some bad triangulations
// which are cause by symmetrical data from the grid structure.
pt[0] = s[0]*sampleDist + getJitterX(i)*cs*0.1f;
pt[1] = s[1]*chf.ch;
pt[2] = s[2]*sampleDist + getJitterY(i)*cs*0.1f;
float d = distToTriMesh(pt, verts, nverts, &tris[0], tris.size()/4);
if (d < 0) continue; // did not hit the mesh.
if (d > bestd)
{
bestd = d;
besti = i;
rcVcopy(bestpt,pt);
}
}
// 没有需要继续切分的 停止搜索
if (bestd <= sampleMaxError || besti == -1)
break;
// Mark sample as added.
samples[besti*4+3] = 1;
// Add the new sample point.
rcVcopy(&verts[nverts*3],bestpt);
nverts++;
// 有新的节点之后 使用delaunay方法对新的节点集合进行三角剖分
edges.clear();
tris.clear();
delaunayHull(ctx, nverts, verts, nhull, hull, tris, edges);
}
细节网格与寻路
其实这部分rcDetailMesh的数据其实是可选的,因为如果只是计算Poly的连通路径的话,当前的rcPolyMesh已经带有了足够的信息,事实上执行寻路的Detour返回的多边形列表就是rcPolyMesh里的多边形,即使rcDetailMesh数据存在。只有使用DetourCrowd来驱动寻路entity的每帧位置更新时,才可能需要rcDetailMesh这样更精确的地表数据,来对输出的entity新位置做高度修正。
navmesh数据序列化到文件
上述流程完整的介绍了如何从场景数据生成NavMesh中的PolyMesh和DetailMesh, 对于一个1km*1km的常规场景来说,这个完整流程大概耗时1min左右。这种分钟级别的耗时导致了不可能进行实时的NavMesh生成,只能在场景编辑完成之后做离线生成,然后序列化对应的数据到文件,以供游戏加载对应场景时加载此NavMesh文件来支持寻路功能。Recast支持将数据以下面的三种格式进行序列化:
SoloMesh格式,最简单的文件格式,对全场景执行上述的NavMesh生成之后,通过dtCreateNavMeshData将计算好的PolyMesh和DetailMesh存储到文件TileMesh格式,按照一定大小的矩形对全场景的XZ平面进行分割,分割后的区块称之为Tile,然后对每个Tile执行NavMesh的生成流程,生成完成之后再调用dtCreateNavMeshData对每个Tile对应的NavMesh数据拼接到同一个文件之中TileCache格式,这个格式并不存储最终的NavMesh数据,存储的是以Tile进行划分的压缩高度场数据,寻路系统运行时在加载完TileCache数据之后需要执行后续的区域生成、多边形生成、细节网格生成等缺失步骤来构造完整的NavMesh数据才能支持寻路查询
事实上SoloMesh与TileMesh的格式是一样的,其结构体都是dtNavMesh, 存储的都是Tile对应NavMesh数据的数组,只不过SoloMesh里的数组大小为1。而TileCache这种运行时重新生成NavMesh会消耗大量的CPU资源,所以只有在需要动态的对场景进行改变时才有使用的需求。所以实际项目中使用最多的是TileMesh格式,因为划分Tile之后可以开启多线程来支持多个Tile之间的并发生成NavMesh,这样就极大的减少了全流程的等待时间,从而加速了迭代效率。虽然这个格式相对于SoleMesh格式来说会浪费一些空间来存储每个Tile数据的描述信息字段,但是这种浪费的空间相对于完整的NavMesh大小来说基本可以忽略。因此下面我们只详解一下TileMesh的序列化流程。
生成TileMesh首先需要以指定的Tile大小对原始的场景进行切分,然后对每个Tile执行NavMesh的生成流程:
void Sample_TileMesh::buildAllTiles()
{
if (!m_geom) return;
if (!m_navMesh) return;
const float* bmin = m_geom->getNavMeshBoundsMin();
const float* bmax = m_geom->getNavMeshBoundsMax();
int gw = 0, gh = 0;
rcCalcGridSize(bmin, bmax, m_cellSize, &gw, &gh);
const int ts = (int)m_tileSize;
const int tw = (gw + ts-1) / ts;
const int th = (gh + ts-1) / ts;
const float tcs = m_tileSize*m_cellSize;
// Start the build process.
m_ctx->startTimer(RC_TIMER_TEMP);
for (int y = 0; y < th; ++y)
{
for (int x = 0; x < tw; ++x)
{
m_lastBuiltTileBmin[0] = bmin[0] + x*tcs;
m_lastBuiltTileBmin[1] = bmin[1];
m_lastBuiltTileBmin[2] = bmin[2] + y*tcs;
m_lastBuiltTileBmax[0] = bmin[0] + (x+1)*tcs;
m_lastBuiltTileBmax[1] = bmax[1];
m_lastBuiltTileBmax[2] = bmin[2] + (y+1)*tcs;
int dataSize = 0;
unsigned char* data = buildTileMesh(x, y, m_lastBuiltTileBmin, m_lastBuiltTileBmax, dataSize);
if (data)
{
// Remove any previous data (navmesh owns and deletes the data).
m_navMesh->removeTile(m_navMesh->getTileRefAt(x,y,0),0,0);
// Let the navmesh own the data.
dtStatus status = m_navMesh->addTile(data,dataSize,DT_TILE_FREE_DATA,0,0);
if (dtStatusFailed(status))
dtFree(data);
}
}
}
// Start the build process.
m_ctx->stopTimer(RC_TIMER_TEMP);
m_totalBuildTimeMs = m_ctx->getAccumulatedTime(RC_TIMER_TEMP)/1000.0f;
}
在RecastDemo中使用了正方形的Tile,其边长为传入的参数m_tileSize。划分好每个Tile之后执行buildTileMesh来执行这个Tile对应的NavMesh数据生成,内部调用了dtCreateNavMeshData序列化为了一个字节数组,生成之后调用addTile函数加入到dtNavMesh中。
在Tile生成初始的体素数据时,并不是以当前Tile计算出来的包围盒来过滤的,而是将这个包围盒向外扩张一定的大小BorderSize * CellSize,:
//
// :''''''''':
// : +-----+ :
// : | | :
// : | |<--- tile to build
// : | | :
// : +-----+ :<-- geometry needed
// :.........:
//
m_cfg.borderSize = m_cfg.walkableRadius + 3; // Reserve enough padding.
m_cfg.width = m_cfg.tileSize + m_cfg.borderSize*2;
m_cfg.height = m_cfg.tileSize + m_cfg.borderSize*2;
rcVcopy(m_cfg.bmin, bmin);
rcVcopy(m_cfg.bmax, bmax);
m_cfg.bmin[0] -= m_cfg.borderSize*m_cfg.cs;
m_cfg.bmin[2] -= m_cfg.borderSize*m_cfg.cs;
m_cfg.bmax[0] += m_cfg.borderSize*m_cfg.cs;
m_cfg.bmax[2] += m_cfg.borderSize*m_cfg.cs;
这里的BorderSize使用了边缘半径加上3,这样做的目的是能够正确的处理边界上的障碍物,同时能够与周围的八个Tile的边界有交集。
在最后的DetailMesh生成完成之后,调用dtCreateNavMeshData来创建这个Tile对应的二进制数据:
rcPolyMesh* m_pmesh; // 生成的多边形网格数据
rcPolyMeshDetail* m_dmesh; // 生成的细节网格数据
dtNavMeshCreateParams params;
memset(¶ms, 0, sizeof(params));
params.verts = m_pmesh->verts;
params.vertCount = m_pmesh->nverts;
params.polys = m_pmesh->polys;
params.polyAreas = m_pmesh->areas;
params.polyFlags = m_pmesh->flags;
params.polyCount = m_pmesh->npolys;
params.nvp = m_pmesh->nvp;
params.detailMeshes = m_dmesh->meshes;
params.detailVerts = m_dmesh->verts;
params.detailVertsCount = m_dmesh->nverts;
params.detailTris = m_dmesh->tris;
params.detailTriCount = m_dmesh->ntris;
params.offMeshConVerts = m_geom->getOffMeshConnectionVerts();
params.offMeshConRad = m_geom->getOffMeshConnectionRads();
params.offMeshConDir = m_geom->getOffMeshConnectionDirs();
params.offMeshConAreas = m_geom->getOffMeshConnectionAreas();
params.offMeshConFlags = m_geom->getOffMeshConnectionFlags();
params.offMeshConUserID = m_geom->getOffMeshConnectionId();
params.offMeshConCount = m_geom->getOffMeshConnectionCount();
params.walkableHeight = m_agentHeight;
params.walkableRadius = m_agentRadius;
params.walkableClimb = m_agentMaxClimb;
params.tileX = tx; // 当前tile在XZ平面以TileSize计算的X坐标
params.tileY = ty; // 当前tile在XZ平面以TileSize计算的Y坐标
params.tileLayer = 0;
rcVcopy(params.bmin, m_pmesh->bmin);
rcVcopy(params.bmax, m_pmesh->bmax);
params.cs = m_cfg.cs;
params.ch = m_cfg.ch;
params.buildBvTree = true;
if (!dtCreateNavMeshData(¶ms, &navData, &navDataSize))
{
m_ctx->log(RC_LOG_ERROR, "Could not build Detour navmesh.");
return 0;
}
这里的OffMeshCon相关的字段代表一些在场景内手动添加的两点之间特殊连通数据,这些数据主要是用来处理跳跃、攀爬等一些不使用表面寻路的特殊寻路类型。在生成Tile对应NavMesh数据时,会获取在当前Tile范围内的OffMeshCon的点的数量:
unsigned char* offMeshConClass = 0;
int storedOffMeshConCount = 0; //起点在当前tile内的offmeshlink数量
int offMeshConLinkCount = 0; // 在当前tile内的offmeshlink节点的数量
offMeshConClass = (unsigned char*)dtAlloc(sizeof(unsigned char)*params->offMeshConCount*2, DT_ALLOC_TEMP);
float hmin = DT_REAL_MAX; // 计算当前tile的具体高度上下限
float hmax = -DT_REAL_MAX;
if (params->detailVerts && params->detailVertsCount)
{
for (int i = 0; i < params->detailVertsCount; ++i)
{
const float h = params->detailVerts[i*3+1];
hmin = dtMin(hmin,h);
hmax = dtMax(hmax,h);
}
}
else
{
for (int i = 0; i < params->vertCount; ++i)
{
const unsigned short* iv = ¶ms->verts[i*3];
const float h = params->bmin[1] + iv[1] * params->ch;
hmin = dtMin(hmin,h);
hmax = dtMax(hmax,h);
}
}
hmin -= params->walkableClimb;
hmax += params->walkableClimb;
float bmin[3], bmax[3]; // 计算出当前tile的AABB包围盒
dtVcopy(bmin, params->bmin);
dtVcopy(bmax, params->bmax);
bmin[1] = hmin;
bmax[1] = hmax;
for (int i = 0; i < params->offMeshConCount; ++i)
{
// 计算非mesh连接的两个点是否在当前poly的XZ范围内 如果在则对应的值为0xff
const float* p0 = ¶ms->offMeshConVerts[(i*2+0)*3];
const float* p1 = ¶ms->offMeshConVerts[(i*2+1)*3];
offMeshConClass[i*2+0] = classifyOffMeshPoint(p0, bmin, bmax);
offMeshConClass[i*2+1] = classifyOffMeshPoint(p1, bmin, bmax);
// 这里对起点做额外判断 如果高度不在范围内 则认为这个连接与当前tile不相关
if (offMeshConClass[i*2+0] == 0xff)
{
if (p0[1] < bmin[1] || p0[1] > bmax[1])
offMeshConClass[i*2+0] = 0;
}
// 当前tile可能会有多少条offmeshlink
if (offMeshConClass[i*2+0] == 0xff)
offMeshConLinkCount++;
if (offMeshConClass[i*2+1] == 0xff)
offMeshConLinkCount++;
if (offMeshConClass[i*2+0] == 0xff) // 存储起点在当前tile的offmeshlink数量
storedOffMeshConCount++;
}
计算好了OffMeshLink的数量之后,整体NavMesh的大小也就可以确定了:
// Calculate data size
const int headerSize = dtAlign4(sizeof(dtMeshHeader)); // 每个tile都会有的dtMeshHeader 代表一些元数据信息
const int vertsSize = dtAlign4(sizeof(float)*3*totVertCount); // 当前tile的节点数据 每个节点有3个float存储
const int polysSize = dtAlign4(sizeof(dtPoly)*totPolyCount); // 当前tile的网格数据,每个网格用dtPoly来存储
const int linksSize = dtAlign4(sizeof(dtLink)*maxLinkCount); // 当前tile内所有可能的多边形之间的link数据 每个link使用dtLink来存储
// 下面三个字段是细节网格的数据
const int detailMeshesSize = dtAlign4(sizeof(dtPolyDetail)*params->polyCount);
const int detailVertsSize = dtAlign4(sizeof(float)*3*uniqueDetailVertCount);
const int detailTrisSize = dtAlign4(sizeof(unsigned char)*4*detailTriCount);
// 下面这个是使用数组存储的BVH数据,这里的BVH叶子节点只包含一个Poly,所以这里最大节点数量不会超过polyCount*2
const int bvTreeSize = params->buildBvTree ? dtAlign4(sizeof(dtBVNode)*params->polyCount*2) : 0;
// 每个起点在当前tile内的offmeshcon数据
const int offMeshConsSize = dtAlign4(sizeof(dtOffMeshConnection)*storedOffMeshConCount);
const int dataSize = headerSize + vertsSize + polysSize + linksSize +
detailMeshesSize + detailVertsSize + detailTrisSize +
bvTreeSize + offMeshConsSize;
unsigned char* data = (unsigned char*)dtAlloc(sizeof(unsigned char)*dataSize, DT_ALLOC_PERM);
if (!data)
{
dtFree(offMeshConClass);
return false;
}
memset(data, 0, dataSize);
unsigned char* d = data;
// 每个存储部分的开始地址
dtMeshHeader* header = dtGetThenAdvanceBufferPointer<dtMeshHeader>(d, headerSize);
float* navVerts = dtGetThenAdvanceBufferPointer<float>(d, vertsSize);
dtPoly* navPolys = dtGetThenAdvanceBufferPointer<dtPoly>(d, polysSize);
d += linksSize; // 这里其实并没有存储Poly之间的连接数据 而是留了一段空白 这段空白区域会在navmesh加载所有tile之后重新计算
dtPolyDetail* navDMeshes = dtGetThenAdvanceBufferPointer<dtPolyDetail>(d, detailMeshesSize);
float* navDVerts = dtGetThenAdvanceBufferPointer<float>(d, detailVertsSize);
unsigned char* navDTris = dtGetThenAdvanceBufferPointer<unsigned char>(d, detailTrisSize);
dtBVNode* navBvtree = dtGetThenAdvanceBufferPointer<dtBVNode>(d, bvTreeSize);
dtOffMeshConnection* offMeshCons = dtGetThenAdvanceBufferPointer<dtOffMeshConnection>(d, offMeshConsSize);
在存储多边形数据时,会受到OffmeshLink的影响,因为针对每个起点在当前Tile内的OffMeshLink,都会生成一个包含两个节点的假多边形:
const int offMeshVertsBase = params->vertCount; // 节点数据先存储正常多边形的数据 然后再存储offmeshcon的数据
const int offMeshPolyBase = params->polyCount; // 多边形索引数据先存储正常多边形 然后存储offmeshlink生成的假多边形
// 存储节点数据
int n = 0;
for (int i = 0; i < params->offMeshConCount; ++i)
{
// 只存储起点在当前tile内的offmeshlink的节点数据
if (offMeshConClass[i*2+0] == 0xff)
{
// 复制当前link的两个端点
const float* linkv = ¶ms->offMeshConVerts[i*2*3];
float* v = &navVerts[(offMeshVertsBase + n*2)*3];
dtVcopy(&v[0], &linkv[0]);
dtVcopy(&v[3], &linkv[3]);
n++;
}
}
// 存储多边形的节点索引
n = 0;
for (int i = 0; i < params->offMeshConCount; ++i)
{
// 只存储起点在当前tile内的offmeshlink
if (offMeshConClass[i*2+0] == 0xff)
{
// 构造一个假的多边形 包含两个offmeshlink点的索引
dtPoly* p = &navPolys[offMeshPolyBase+n];
p->vertCount = 2;
p->verts[0] = (unsigned short)(offMeshVertsBase + n*2+0);
p->verts[1] = (unsigned short)(offMeshVertsBase + n*2+1);
p->flags = params->offMeshConFlags[i];
p->setArea(params->offMeshConAreas[i]);
p->setType(DT_POLYTYPE_OFFMESH_CONNECTION);
n++;
}
}
除了OffMeshLink对应的假多边形节点之外,还需要存储这条OffMeshLink的详细信息:
// Store Off-Mesh connections.
n = 0;
for (int i = 0; i < params->offMeshConCount; ++i)
{
// 只存储起点在当前tile内的offmeshlink
if (offMeshConClass[i*2+0] == 0xff)
{
dtOffMeshConnection* con = &offMeshCons[n];
con->poly = (unsigned short)(offMeshPolyBase + n);
// 这里又复制了一份两个端点的数据
const float* endPts = ¶ms->offMeshConVerts[i*2*3];
dtVcopy(&con->pos[0], &endPts[0]);
dtVcopy(&con->pos[3], &endPts[3]);
con->rad = params->offMeshConRad[i];
con->flags = params->offMeshConDir[i] ? DT_OFFMESH_CON_BIDIR : 0;
con->side = offMeshConClass[i*2+1]; //终点所在的tile相对于当前tile的方向
if (params->offMeshConUserID)
con->userId = params->offMeshConUserID[i];
n++;
}
}
序列化完成一个Tile的数据之后,执行addTile流程,这里除了会把data复制过去之外,还会执行一些连接边的计算,以填充之前留白的dtLink数组。这部分数据只有在真正执行寻路的时候才有用,当前我们只考虑序列化流程,所以不对这部分进行讨论。最终生成的dtNavMesh写入到文件的代码就比较简单了,先写dtNavMesh的头部元数据,然后遍历每个单独的Tile进行数据追加:
void Sample::saveAll(const char* path, const dtNavMesh* mesh)
{
if (!mesh) return;
FILE* fp = fopen(path, "wb");
if (!fp)
return;
// 写入dtNavmesh的头部元数据
NavMeshSetHeader header;
header.magic = NAVMESHSET_MAGIC;
header.version = NAVMESHSET_VERSION;
header.numTiles = 0;
for (int i = 0; i < mesh->getMaxTiles(); ++i)
{
const dtMeshTile* tile = mesh->getTile(i);
if (!tile || !tile->header || !tile->dataSize) continue;
header.numTiles++;
}
memcpy(&header.params, mesh->getParams(), sizeof(dtNavMeshParams));
fwrite(&header, sizeof(NavMeshSetHeader), 1, fp);
// 追加每个tile的数据
for (int i = 0; i < mesh->getMaxTiles(); ++i)
{
const dtMeshTile* tile = mesh->getTile(i);
if (!tile || !tile->header || !tile->dataSize) continue;
NavMeshTileHeader tileHeader;
tileHeader.tileRef = mesh->getTileRef(tile);
tileHeader.dataSize = tile->dataSize;
fwrite(&tileHeader, sizeof(tileHeader), 1, fp);
fwrite(tile->data, tile->dataSize, 1, fp);
}
fclose(fp);
}
一个1km*1km的场景生成的dtNavMesh数据序列化到文件之后,其数据文件大小一般不会超过1MB,而加载之后的内存大小基本等于数据文件大小,可以看出NavMesh在内存上的优势。如果想要极限的减少数据存储则可以将dtLink相关的数据不写入文件,这样做的话文件大小能够减少1/3左右,只有当场景变得超级大时才会有明显的内存优化效果。