Unreal Engine 的数据表
UE数据表的编辑
UE由于有自己实现一切的理念,所以其并没有使用Excel来作为数据表格编辑工具,而是自己实现了一套更加贴合其UObject系统的数据表系统,包括编辑器、运行时、导入导出工具。下图就是其编辑界面:
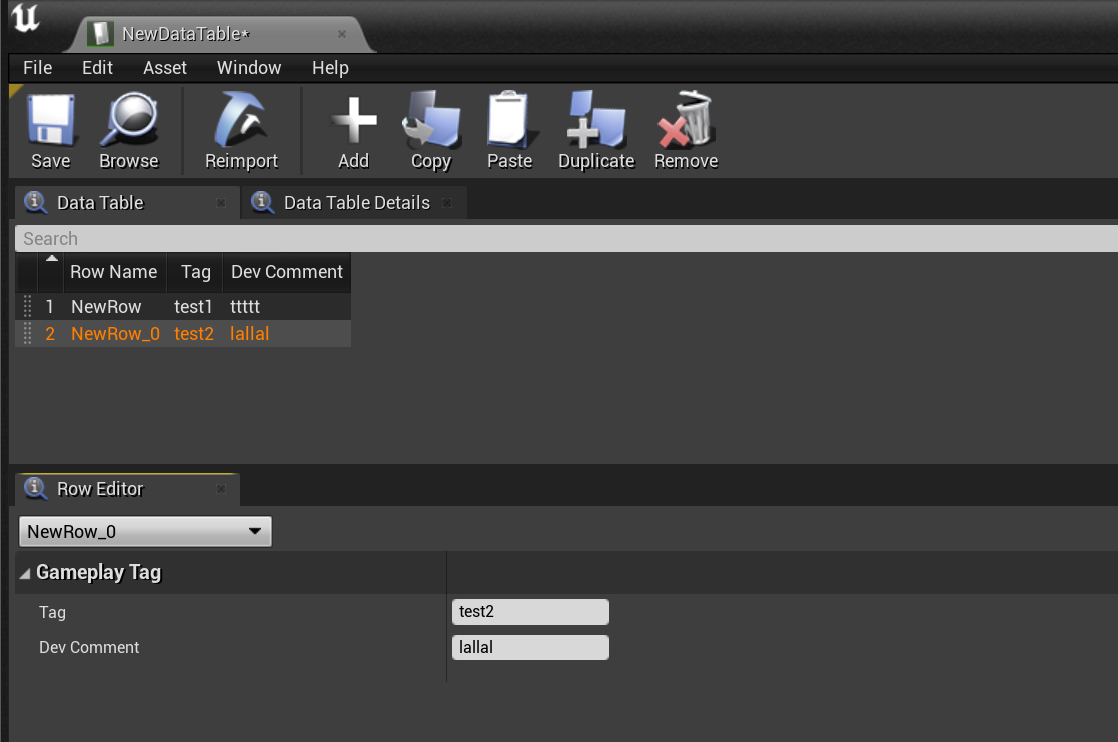
可以看出这里实现了非常基本的行数据编辑系统,提供了新建、复制、粘贴、删除等基本操作。每一个数据表都是UDataTable类型,为了明确其存储的内容以及方便强类型的数据读写,其创建时需要指定当前数据表所选用的行定义是什么:
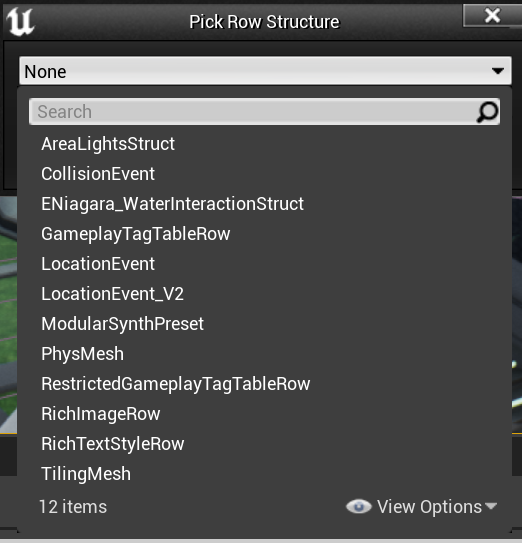
这些类型可以通过蓝图创建一个Struct,不过更推荐直接在cpp代码中创建数据行的定义,下面就是引擎中实际使用的FGameplayTagTableRow的定义:
/** Simple struct for a table row in the gameplay tag table and element in the ini list */
USTRUCT()
struct FGameplayTagTableRow : public FTableRowBase
{
GENERATED_USTRUCT_BODY()
/** Tag specified in the table */
UPROPERTY(EditAnywhere, BlueprintReadOnly, Category=GameplayTag)
FName Tag;
/** Developer comment clarifying the usage of a particular tag, not user facing */
UPROPERTY(EditAnywhere, BlueprintReadOnly, Category=GameplayTag)
FString DevComment;
};
每个数据行类型都需要继承自FTableRowBase,然后在结构体内部通过定义一系列的UPROPERTY来给出当前行中所需要的每一列的数据类型和访问所使用的名字。注意这里的行定义不需要指定作为行索引的key字段,因为UDataTable会自动的给每一行增加一个Name字段,也就是前面的编辑器图中的Row Name所展示的列。只有这个Row Name列的数据才会作为索引存在,使用者可以自由的编辑每一行的Row Name。
然后UE里除了支持整数、字符串、浮点数、布尔等基础类型之外,也支持了FVector,TArray等复合类型,这部分的功能基本对齐了常规的各种数据配置解决方案。为了与UObject联系更加紧密,他还支持了各种资产类型,例如动画、声音等,下面的类型定义中就提供了一个成就图标作为等级数据的其中一个字段:
/** Structure that defines a level up table entry */
USTRUCT(BlueprintType)
struct FLevelUpData : public FTableRowBase
{
GENERATED_USTRUCT_BODY()
public:
FLevelUpData()
: XPtoLvl(0)
, AdditionalHP(0)
{}
/** The 'Name' column is the same as the XP Level */
/** XP to get to the given level from the previous level */
UPROPERTY(EditAnywhere, BlueprintReadWrite, Category=LevelUp)
int32 XPtoLvl;
/** Extra HitPoints gained at this level */
UPROPERTY(EditAnywhere, BlueprintReadWrite, Category=LevelUp)
int32 AdditionalHP;
/** Icon to use for Achivement */
UPROPERTY(EditAnywhere, BlueprintReadWrite, Category=LevelUp)
TSoftObjectPtr<UTexture> AchievementIcon;
};
注意这里并没有直接使用UTexture*而是使用TSoftObjectPtr<UTexture>,因为直接使用UTexture*会导致加载这个数据表的时候递归的把内部直接引用的这些UTexture字段一并同步加载,这样会导致主线程卡顿。所以这里使用TSoftObjectPtr<UTexture>作为对应资源的软引用,运行时使用这行数据里的AchievementIcon时,只需要执行AchievementIcon->LoadSynchronous()即可按需的进行单一资源的加载,这样就避免了同步加载太多不需要的资源,优化了执行时间。
UE数据表的导入与导出
从前面的编辑器截图可以看出,这个编辑器相对于excel来说还是太简陋了,尤其是对大量数据进行编辑和条件化查询的时候。因此UE也妥协了一点,支持了数据表与csv/json这两种文本格式的互相转换:
/** Output entire contents of table as CSV */
ENGINE_API FString GetTableAsCSV(const EDataTableExportFlags InDTExportFlags = EDataTableExportFlags::None) const;
/** Output entire contents of table as JSON */
ENGINE_API FString GetTableAsJSON(const EDataTableExportFlags InDTExportFlags = EDataTableExportFlags::None) const;
/**
* Create table from CSV style comma-separated string.
* RowStruct must be defined before calling this function.
* @return Set of problems encountered while processing input
*/
ENGINE_API TArray<FString> CreateTableFromCSVString(const FString& InString);
/**
* Create table from JSON style string.
* RowStruct must be defined before calling this function.
* @return Set of problems encountered while processing input
*/
ENGINE_API TArray<FString> CreateTableFromJSONString(const FString& InString);
我们来对前面贴出的两行数据做转换,只需要在这个资产上右键,顶部就会出现导出菜单:
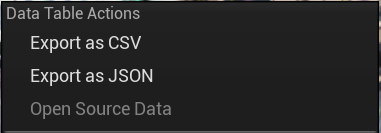
当转换为csv格式时,第一行作为列名,第一列作为索引列,样例内容如下:
---,Tag,DevComment
NewRow,"test1","ttttt"
NewRow_0,"test2","lallal"
当转换为json时,输出为一个数组,数组中以JsonObject的形式来存储一行数据,其中Name字段存储当前行索引,样例内容如下:
[
{
"Name": "NewRow",
"Tag": "test1",
"DevComment": "ttttt"
},
{
"Name": "NewRow_0",
"Tag": "test2",
"DevComment": "lallal"
}
]
对于基础类型和数组类型的字段可以很简单的映射到文本值或者Json值,如果是字段是资产或者资产的软引用的话,这里会转换为对应的资产引用路径。
打开一个指定的数据表资产之后,可以使用其中的导入按钮来从csv/json更新数据:
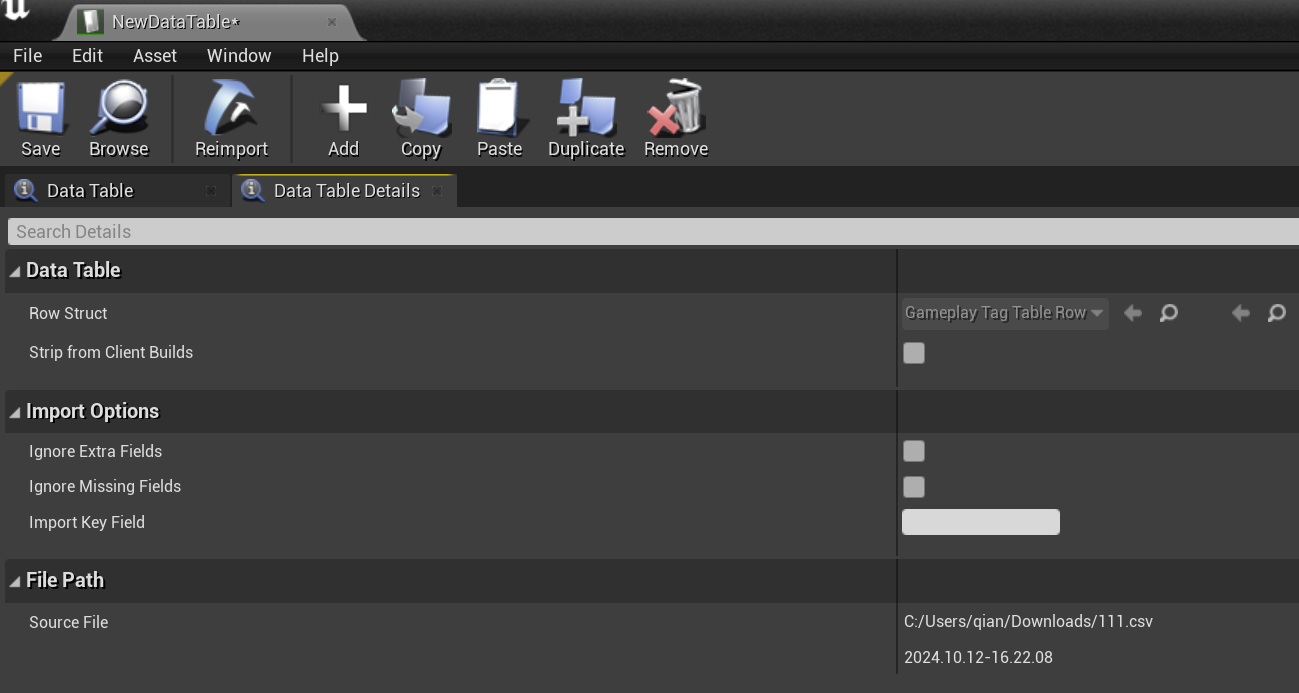
当导入成功之后,上面的Source File里会记录上次导入的源文件是什么,以方便快速的重新导入。
UE数据表的序列化与反序列化
UDataTable的结构其实很简单,其中的数据字段其实很少,一般情况下只需要考虑这几个数据成员即可:
class UDataTable
: public UObject
{
/** Structure to use for each row of the table, must inherit from FTableRowBase */
UPROPERTY(VisibleAnywhere, Category=DataTable, meta=(DisplayThumbnail="false"))
UScriptStruct* RowStruct;
/** Map of name of row to row data structure. */
TMap<FName, uint8*> RowMap;
/** Set to true to not cook this data table into client builds. Useful for sensitive tables that only servers should know about. */
UPROPERTY(EditAnywhere, Category=DataTable)
uint8 bStripFromClientBuilds : 1;
/** Set to true to ignore extra fields in the import data, if false it will warn about them */
UPROPERTY(EditAnywhere, Category=ImportOptions)
uint8 bIgnoreExtraFields : 1;
/** Set to true to ignore any fields that are expected but missing, if false it will warn about them */
UPROPERTY(EditAnywhere, Category = ImportOptions)
uint8 bIgnoreMissingFields : 1;
/** Explicit field in import data to use as key. If this is empty it uses Name for JSON and the first field found for CSV */
UPROPERTY(EditAnywhere, Category=ImportOptions)
FString ImportKeyField;
}
这里的RowStruct存储的是当前数据表的行结构体信息,后续的三个布尔值用来控制一些杂项,我们这里就先忽略,ImportKeyField存储的是与外部数据文件进行导入导出时每一行的索引值。真正存储数据的位置在RowMap中,但是这个字段并没有被UProperty标记,无法参与默认的UClass的序列化反序列化,所以UDataTable在序列化反序列化时,先使用UClass默认的序列化函数来处理这些被UProperty包裹的数据字段,然后再单独处理RowMap字段:
void UDataTable::Serialize(FStructuredArchiveRecord Record)
{
FArchive& BaseArchive = Record.GetUnderlyingArchive();
#if WITH_EDITORONLY_DATA
// Make sure and update RowStructName before calling the parent Serialize (which will save the properties)
if (BaseArchive.IsSaving() && RowStruct)
{
RowStructName = RowStruct->GetFName();
}
#endif // WITH_EDITORONLY_DATA
Super::Serialize(Record); // When loading, this should load our RowStruct!
if (RowStruct && RowStruct->HasAnyFlags(RF_NeedLoad))
{
auto RowStructLinker = RowStruct->GetLinker();
if (RowStructLinker)
{
RowStructLinker->Preload(RowStruct);
}
}
if(BaseArchive.IsLoading())
{
DATATABLE_CHANGE_SCOPE();
EmptyTable();
LoadStructData(Record.EnterField(SA_FIELD_NAME(TEXT("Data"))));
}
else if(BaseArchive.IsSaving())
{
SaveStructData(Record.EnterField(SA_FIELD_NAME(TEXT("Data"))));
}
}
由于LoadStructData与SaveStructData是一个互逆的关系,所以我们这里只看SaveStructData,按照正常逻辑大家应该可以猜到就是遍历每一行,然后遍历行结构体里的每个UProperty字段,进行写入,其代码也的确是这样写的:
void UDataTable::SaveStructData(FStructuredArchiveSlot Slot)
{
UScriptStruct* SaveUsingStruct = RowStruct;
if (!SaveUsingStruct)
{
if (!HasAnyFlags(RF_ClassDefaultObject) && GetOutermost() != GetTransientPackage())
{
UE_LOG(LogDataTable, Error, TEXT("Missing RowStruct while saving DataTable '%s'!"), *GetPathName());
}
SaveUsingStruct = FTableRowBase::StaticStruct();
}
int32 NumRows = RowMap.Num();
FStructuredArchiveArray Array = Slot.EnterArray(NumRows);
// Now iterate over rows in the map
for (auto RowIt = RowMap.CreateIterator(); RowIt; ++RowIt)
{
// Save out name
FName RowName = RowIt.Key();
FStructuredArchiveRecord Row = Array.EnterElement().EnterRecord();
Row << SA_VALUE(TEXT("Name"), RowName);
// Save out data
uint8* RowData = RowIt.Value();
SaveUsingStruct->SerializeItem(Row.EnterField(SA_FIELD_NAME(TEXT("Value"))), RowData, nullptr);
}
}
最后的SaveUsingStruct->SerializeItem就是遍历所有属性字段的流程,对于表格的行结构体来说,最终会执行下面的函数调用:
SerializeTaggedProperties(Slot, (uint8*)Value, this, (uint8*)Defaults);
// ==>
SerializeVersionedTaggedProperties(Slot, Data, DefaultsStruct, Defaults, BreakRecursionIfFullyLoad);
// ==>
最后的函数里会有一个循环来遍历所有的属性来进行写入,下面的就是负责写入一个Property的部分,重点看PropertySlot的相关操作:
uint8* DataPtr = Property->ContainerPtrToValuePtr <uint8>(Data, Idx);
uint8* DefaultValue = Property->ContainerPtrToValuePtrForDefaults<uint8>(DefaultsStruct, Defaults, Idx);
if (StaticArrayContainer.IsSet() || CustomPropertyNode || !UnderlyingArchive.DoDelta() || UnderlyingArchive.IsTransacting() || (!Defaults && !dynamic_cast<const UClass*>(this)) || !Property->Identical(DataPtr, DefaultValue, UnderlyingArchive.GetPortFlags()))
{
if (bUseAtomicSerialization)
{
DefaultValue = NULL;
}
TestCollector.RecordSavedProperty(Property);
FPropertyTag Tag( UnderlyingArchive, Property, Idx, DataPtr, DefaultValue );
// If available use the property guid from BlueprintGeneratedClasses, provided we aren't cooking data.
if (bArePropertyGuidsAvailable && !UnderlyingArchive.IsCooking())
{
const FGuid PropertyGuid = FindPropertyGuidFromName(Tag.Name);
Tag.SetPropertyGuid(PropertyGuid);
}
TStringBuilder<256> TagName;
Tag.Name.ToString(TagName);
FStructuredArchive::FSlot PropertySlot = StaticArrayContainer.IsSet() ? StaticArrayContainer->EnterElement() : PropertiesRecord.EnterField(SA_FIELD_NAME(TagName.ToString()));
PropertySlot << Tag;
// need to know how much data this call to SerializeTaggedProperty consumes, so mark where we are
int64 DataOffset = UnderlyingArchive.Tell();
// if using it, save the current custom property list and switch to its sub property list (in case of UStruct serialization)
const FCustomPropertyListNode* SavedCustomPropertyList = nullptr;
if (UnderlyingArchive.ArUseCustomPropertyList && CustomPropertyNode)
{
SavedCustomPropertyList = UnderlyingArchive.ArCustomPropertyList;
UnderlyingArchive.ArCustomPropertyList = CustomPropertyNode->SubPropertyList;
}
Tag.SerializeTaggedProperty(PropertySlot, Property, DataPtr, DefaultValue);
// 省略一下后续代码
}
最后的SerializeTaggedProperty会调用到Property->SerializeItem(Slot, Value, Defaults);,这里负责真正的单一属性对应的值写入到Archive中,在写入这个Archive之前会先执行PropertiesRecord.EnterField(SA_FIELD_NAME(TagName.ToString()))将这个属性的名字先写入。从这一小段流程代码可以看出整个行结构体的序列化其实在以JsonObject类似的形式递归的写入整个行。不过这里相对于JsonObject来说有一个非常低效的地方在于每个属性字段在序列化时都要执行PropertySlot << Tag,这个调用就是在写入当前属性的元信息:
void operator<<(FStructuredArchive::FSlot Slot, FPropertyTag& Tag)
{
FArchive& UnderlyingArchive = Slot.GetUnderlyingArchive();
bool bIsTextFormat = UnderlyingArchive.IsTextFormat();
int32 Version = UnderlyingArchive.UE4Ver();
check(!UnderlyingArchive.GetArchiveState().UseUnversionedPropertySerialization());
checkf(!UnderlyingArchive.IsSaving() || Tag.Prop, TEXT("FPropertyTag must be constructed with a valid property when used for saving data!"));
if (!bIsTextFormat)
{
// Name.
Slot << SA_ATTRIBUTE(TEXT("Name"), Tag.Name);
if (Tag.Name.IsNone())
{
return;
}
}
Slot << SA_ATTRIBUTE(TEXT("Type"), Tag.Type);
// 省略一些代码
if (!bIsTextFormat)
{
FArchive::FScopeSetDebugSerializationFlags S(UnderlyingArchive, DSF_IgnoreDiff);
Slot << SA_ATTRIBUTE(TEXT("Size"), Tag.Size);
Slot << SA_ATTRIBUTE(TEXT("ArrayIndex"), Tag.ArrayIndex);
}
FNameEntryId TagType = Tag.Type.GetComparisonIndex();
if (Tag.Type.GetNumber() == 0)
{
// only need to serialize this for structs
if (TagType == NAME_StructProperty)
{
Slot << SA_ATTRIBUTE(TEXT("StructName"), Tag.StructName);
if (Version >= VER_UE4_STRUCT_GUID_IN_PROPERTY_TAG)
{
if (bIsTextFormat)
{
Slot << SA_OPTIONAL_ATTRIBUTE(TEXT("StructGuid"), Tag.StructGuid, FGuid());
}
else
{
Slot << SA_ATTRIBUTE(TEXT("StructGuid"), Tag.StructGuid);
}
}
}
// only need to serialize this for bools
else if (TagType == NAME_BoolProperty && !UnderlyingArchive.IsTextFormat())
{
if (UnderlyingArchive.IsSaving())
{
FSerializedPropertyScope SerializedProperty(UnderlyingArchive, Tag.Prop);
Slot << SA_ATTRIBUTE(TEXT("BoolVal"), Tag.BoolVal);
}
else
{
Slot << SA_ATTRIBUTE(TEXT("BoolVal"), Tag.BoolVal);
}
}
// 省略其他的分支判断
}
}
可以看出,在这个调用中,属性的名字、类型、数组维度、默认值等信息都会写一遍,这样的序列化方法对于UDataTable来说是极大的浪费的,因为他每一行数据这些字段都是一样的。最优的方法应该是UDataTable开头只写一次,然后每行数据只写真正的数据,忽略属性元信息。
此外UDataTable这样的序列化规则在处理稀疏数据表的时候会把与默认值相等的属性也写入,因为其调用每一行的结构体序列化时最后一个代表默认值的参数传入的是nullptr:
SaveUsingStruct->SerializeItem(Row.EnterField(SA_FIELD_NAME(TEXT("Value"))), RowData, nullptr)
void UScriptStruct::SerializeItem(FStructuredArchive::FSlot Slot, void* Value, void const* Defaults);
如果传入的是一个默认构造的行结构体的话就可以避免这些默认值的写入。
UDataTable在从文件加载的时候,执行LoadStructData来遍历之前序列化出来的Array,Array中的每个元素都对应一行数据:
void UDataTable::LoadStructData(FStructuredArchiveSlot Slot)
{
UScriptStruct* LoadUsingStruct = RowStruct;
if (!LoadUsingStruct)
{
if (!HasAnyFlags(RF_ClassDefaultObject) && GetOutermost() != GetTransientPackage())
{
UE_LOG(LogDataTable, Error, TEXT("Missing RowStruct while loading DataTable '%s'!"), *GetPathName());
}
LoadUsingStruct = FTableRowBase::StaticStruct();
}
int32 NumRows;
FStructuredArchiveArray Array = Slot.EnterArray(NumRows);
DATATABLE_CHANGE_SCOPE();
RowMap.Reserve(NumRows);
for (int32 RowIdx = 0; RowIdx < NumRows; RowIdx++)
{
FStructuredArchiveRecord RowRecord = Array.EnterElement().EnterRecord();
// Load row name
FName RowName;
RowRecord << SA_VALUE(TEXT("Name"), RowName);
// Load row data
uint8* RowData = (uint8*)FMemory::Malloc(LoadUsingStruct->GetStructureSize());
// And be sure to call DestroyScriptStruct later
LoadUsingStruct->InitializeStruct(RowData);
LoadUsingStruct->SerializeItem(RowRecord.EnterField(SA_FIELD_NAME(TEXT("Value"))), RowData, nullptr);
// Add to map
RowMap.Add(RowName, RowData);
}
}
上面代码中的FMemory::Malloc就是动态内存分配的调用,加载一行时首先使用InitializeStruct来初始化为行结构体的默认值,然后再使用SerializeItem来遍历当前行结构体里的所有UProperty并执行反序列化,从而来填充当前行里的所有列。对于每一行数据都会触发一次动态内存分配的加载模式其实挺浪费资源的,对于数据量比较大的UDataTable来说很容易就出现加载时的性能瓶颈。对于最终打包好的游戏而言,UDataTable基本就是一个只读对象,所以可以尝试将这里的按行分配切换为提前分配一个包含所有行所需内存的大内存块来避免动态内存分配。
在这些因素的作用下,面对超过上万行的数据表,UDataTable的序列化反序列化会出现比较明显的性能瓶颈。如果想优化的话可以尝试从上面的分析结论入手。
UE数据表的查询
将每一行反序列化完成之后,所有行数据会存储在内部的一个TMap中,对外暴露的查询接口都是对这个TMap的一个封装:
TMap<FName, uint8*> RowMap;
template <class T>
void GetAllRows(const TCHAR* ContextString, OUT TArray<T*>& OutRowArray) const;
template <class T>
void GetAllRows(const FString& ContextString, OUT TArray<T*>& OutRowArray) const;
/** Function to find the row of a table given its name. */
template <class T>
T* FindRow(FName RowName, const TCHAR* ContextString, bool bWarnIfRowMissing = true) const;
/** Perform some operation for every row. */
template <class T>
void ForeachRow(const TCHAR* ContextString, TFunctionRef<void (const FName& Key, const T& Value)> Predicate) const;
这里的查询使用的Key类型是FName类型,并不是平常我们使用的FString类型。在UE官方文档介绍FName时,提到了FName在进行比较和查询时相对于FString有很大的优势。这里我们来深入的了解一下这样的优势来源,首先来查看一下这个FName的类型定义:
/** Index into the Names array (used to find String portion of the string/number pair used for comparison) */
FNameEntryId ComparisonIndex;
#if WITH_CASE_PRESERVING_NAME
/** Index into the Names array (used to find String portion of the string/number pair used for display) */
FNameEntryId DisplayIndex;
#endif // WITH_CASE_PRESERVING_NAME
/** Number portion of the string/number pair (stored internally as 1 more than actual, so zero'd memory will be the default, no-instance case) */
uint32 Number;
其实FName的数据成员只有这三个,其中的DisplayIndex还只有在开启了WITH_CASE_PRESERVING_NAME这个大小写敏感宏的时候才会启用,而FNameEntryId其实只是对一个只读的uint32的封装,所以默认情况下这个结构体只有8字节大小。那这两个字段是如何代表一个字符串的呢,这就需要查看这个类型的构造函数,其构造函数有很多不过都大同小易,我们来查看其从转换到FString的函数:
#define NAME_NO_NUMBER_INTERNAL 0
/** Conversion routines between external representations and internal */
#define NAME_INTERNAL_TO_EXTERNAL(x) (x - 1)
#define NAME_EXTERNAL_TO_INTERNAL(x) (x + 1)
void FName::ToString(FString& Out) const
{
// A version of ToString that saves at least one string copy
const FNameEntry* const NameEntry = GetDisplayNameEntry();
if (GetNumber() == NAME_NO_NUMBER_INTERNAL)
{
Out.Empty(NameEntry->GetNameLength());
NameEntry->AppendNameToString(Out);
}
else
{
Out.Empty(NameEntry->GetNameLength() + 6);
NameEntry->AppendNameToString(Out);
Out += TEXT('_');
Out.AppendInt(NAME_INTERNAL_TO_EXTERNAL(GetNumber()));
}
}
从这个函数的实现可以看出,FName主要针对的是AAA_BBB类型的字符串,其中BBB代表的是一个非负整数。而这种字符串格式又是UE默认的相似资产命名格式,这样的将末尾的数字拆出的设计相当于在UE的环境下的专属优化。注意上面代码中列出来的宏,表明如果代表的字符串并没有数字后缀,则其Number=0,否则Number=BBB+1,所以FName是可以用于无数字后缀的字符串的,ComparisonIndex就代表了除掉可能的数字后缀的字符串。
ComparisonIndex作为一个对uint32的封装,是无法通过自身来表示一个完整的字符串的,其作用是充当一个全局常量字符串池中的字符串索引。为了确保FName相等时对应的字符串也相等,不等时对应的字符串也不等,需要这个全局常量字符串池对于同一个字符串产生一个唯一的uint32:
static FName Make(FNameStringView View, EFindName FindType, int32 InternalNumber)
{
FNamePool& Pool = GetNamePool();
FNameEntryId DisplayId, ComparisonId;
if (FindType == FNAME_Add)
{
DisplayId = Pool.Store(View);
#if WITH_CASE_PRESERVING_NAME
ComparisonId = Pool.Resolve(DisplayId).ComparisonId;
#else
ComparisonId = DisplayId;
#endif
}
else if (FindType == FNAME_Find)
{
DisplayId = Pool.Find(View);
#if WITH_CASE_PRESERVING_NAME
ComparisonId = DisplayId ? Pool.Resolve(DisplayId).ComparisonId : DisplayId;
#else
ComparisonId = DisplayId;
#endif
}
else
{
check(FindType == FNAME_Replace_Not_Safe_For_Threading);
#if FNAME_WRITE_PROTECT_PAGES
checkf(false, TEXT("FNAME_Replace_Not_Safe_For_Threading can't be used together with page protection."));
#endif
DisplayId = Pool.Store(View);
#if WITH_CASE_PRESERVING_NAME
ComparisonId = Pool.Resolve(DisplayId).ComparisonId;
#else
ComparisonId = DisplayId;
#endif
ReplaceName(Pool.Resolve(ComparisonId), View);
}
return FName(ComparisonId, DisplayId, InternalNumber);
}
从上面的FName创建接口可以看出FNamePool& Pool = GetNamePool();这里的Pool就是设计中的全局常量字符串表,DisplayId = Pool.Store(View)返回的就是传入字符串对应的uint32索引:
FNameEntryId FNamePool::Store(FNameStringView Name)
{
#if WITH_CASE_PRESERVING_NAME
FNameDisplayValue DisplayValue(Name);
if (FNameEntryId Existing = DisplayShards[DisplayValue.Hash.ShardIndex].Find(DisplayValue))
{
return Existing;
}
#endif
bool bAdded = false;
// Insert comparison name first since display value must contain comparison name
FNameComparisonValue ComparisonValue(Name);
FNameEntryId ComparisonId = ComparisonShards[ComparisonValue.Hash.ShardIndex].Insert(ComparisonValue, bAdded);
#if WITH_CASE_PRESERVING_NAME
DisplayValue.ComparisonId = ComparisonId;
return StoreValue(DisplayValue, bAdded);
#else
return ComparisonId;
#endif
}
这里的FNameComparisonValue构造的时候会计算出当前传入字符串的Hash,以这个Hash的分片索引去选择ComparisonShards数组中其中一个来进行寻找和插入,并构造出一个FNameEntryId进行返回。这里的Hash计算有一个非常重要的特性,即其忽略了字符串的大小写,计算时会将大写字母全都转换为小写字母来然后调用Google发明的面向短字符串优化的CityHash64来计算hash:
template<class CharType>
static uint64 GenerateHash(const CharType* Str, int32 Len)
{
return CityHash64(reinterpret_cast<const char*>(Str), Len * sizeof(CharType));
}
template<class CharType>
FNameHash(const CharType* Str, int32 Len)
: FNameHash(Str, Len, GenerateHash(Str, Len))
{}
template<class CharType>
FORCENOINLINE FNameHash HashLowerCase(const CharType* Str, uint32 Len)
{
CharType LowerStr[NAME_SIZE];
for (uint32 I = 0; I < Len; ++I)
{
LowerStr[I] = TChar<CharType>::ToLower(Str[I]);
}
return FNameHash(LowerStr, Len);
}
template<>
FNameHash HashName<ENameCase::IgnoreCase>(FNameStringView Name)
{
return Name.IsAnsi() ? HashLowerCase(Name.Ansi, Name.Len) : HashLowerCase(Name.Wide, Name.Len);
}
template<ENameCase Sensitivity>
struct FNameValue
{
explicit FNameValue(FNameStringView InName)
: Name(InName)
, Hash(HashName<Sensitivity>(InName))
{}
FNameValue(FNameStringView InName, FNameHash InHash)
: Name(InName)
, Hash(InHash)
{}
FNameValue(FNameStringView InName, uint64 InHash)
: Name(InName)
, Hash(Name.bIsWide ? FNameHash(Name.Wide, Name.Len, InHash) : FNameHash(Name.Ansi, Name.Len, InHash))
{}
FNameStringView Name;
FNameHash Hash;
#if WITH_CASE_PRESERVING_NAME
FNameEntryId ComparisonId;
#endif
};
using FNameComparisonValue = FNameValue<ENameCase::IgnoreCase>;
由于这个Hash是忽略了大小写的,所以整个FName都是一个忽略了大小写的字符串索引,使用FName要特别注意其大小写不敏感的特点,极其容易引发各种bug。
同时由于FName是忽略大小写的,所以ComparisonShards.Insert接口来进行字符串相等判定时也是忽略大小写的:
FNamePoolShard<ENameCase::IgnoreCase> ComparisonShards[FNamePoolShards];
template<ENameCase Sensitivity>
class FNamePoolShard : public FNamePoolShardBase
{
public:
FNameEntryId Find(const FNameValue<Sensitivity>& Value) const
{
FRWScopeLock _(Lock, FRWScopeLockType::SLT_ReadOnly);
return Probe(Value).GetId();
}
template<class ScopeLock = FWriteScopeLock>
FORCEINLINE FNameEntryId Insert(const FNameValue<Sensitivity>& Value, bool& bCreatedNewEntry)
{
ScopeLock _(Lock);
FNameSlot& Slot = Probe(Value);
if (Slot.Used())
{
return Slot.GetId();
}
bCreatedNewEntry = true;
return CreateAndInsertEntry<ScopeLock>(Slot, Value);
}
/** Find slot containing value or the first free slot that should be used to store it */
FORCEINLINE FNameSlot& Probe(const FNameValue<Sensitivity>& Value) const
{
return Probe(Value.Hash.UnmaskedSlotIndex,
[&](FNameSlot Slot) { return Slot.GetProbeHash() == Value.Hash.SlotProbeHash &&
EntryEqualsValue<Sensitivity>(Entries->Resolve(Slot.GetId()), Value); });
}
/** Find slot that fulfills predicate or the first free slot */
template<class PredicateFn>
FORCEINLINE FNameSlot& Probe(uint32 UnmaskedSlotIndex, PredicateFn Predicate) const
{
const uint32 Mask = CapacityMask;
for (uint32 I = FNameHash::GetProbeStart(UnmaskedSlotIndex, Mask); true; I = (I + 1) & Mask)
{
FNameSlot& Slot = Slots[I];
if (!Slot.Used() || Predicate(Slot))
{
return Slot;
}
}
}
}
上面的代码逻辑就相当于把FNamePoolShard当作一个开放寻址的Hash表来使用,这里执行字符串相等判定的地方在EntryEqualsValue中:
template<ENameCase Sensitivity>
FORCEINLINE bool EqualsSameDimensions(FNameStringView A, FNameStringView B)
{
checkSlow(A.Len == B.Len && A.IsAnsi() == B.IsAnsi());
int32 Len = A.Len;
if (Sensitivity == ENameCase::CaseSensitive)
{
return B.IsAnsi() ? !FPlatformString::Strncmp(A.Ansi, B.Ansi, Len) : !FPlatformString::Strncmp(A.Wide, B.Wide, Len);
}
else
{
return B.IsAnsi() ? !FPlatformString::Strnicmp(A.Ansi, B.Ansi, Len) : !FPlatformString::Strnicmp(A.Wide, B.Wide, Len);
}
}
虽然在判定相等和计算Hash的时候都使用了大写向小写转换,期间并没有修改原始字符串,特别是在计算Hash时生成一个临时字符串来辅助计算。当最终插入字符串的时候,插入进去的仍然是最开始传入的字符串:
void FNameEntry::StoreName(const ANSICHAR* InName, uint32 Len)
{
FPlatformMemory::Memcpy(AnsiName, InName, sizeof(ANSICHAR) * Len);
Encode(AnsiName, Len);
}
void FNameEntry::StoreName(const WIDECHAR* InName, uint32 Len)
{
FPlatformMemory::Memcpy(WideName, InName, sizeof(WIDECHAR) * Len);
Encode(WideName, Len);
}
template<class ScopeLock>
FNameEntryHandle FNameEntryAllocator::Create(FNameStringView Name, TOptional<FNameEntryId> ComparisonId, FNameEntryHeader Header)
{
FPlatformMisc::Prefetch(Blocks[CurrentBlock]);
FNameEntryHandle Handle = Allocate<ScopeLock>(FNameEntry::GetDataOffset() + Name.BytesWithoutTerminator());
FNameEntry& Entry = Resolve(Handle);
#if WITH_CASE_PRESERVING_NAME
Entry.ComparisonId = ComparisonId.IsSet() ? ComparisonId.GetValue() : FNameEntryId(Handle);
#endif
Entry.Header = Header;
if (Name.bIsWide)
{
Entry.StoreName(Name.Wide, Name.Len);
}
else
{
Entry.StoreName(Name.Ansi, Name.Len);
}
return Handle;
}
所以将一个FName转换到字符串时,其输出的内容又保留了最开始第一次插入时的大小写,即如果先以字符串AAA构造好了一个FName之后, 字符串aaa构造的FName就会等于AAA对应的FName,但是这个FName输出的字符串又会变成AAA。
总体看下来这个FName对于TMap的查询加速主要由这几点机制贡献的:
FName的大小很小,在以值进行传递时不会引入复制损耗,如果用FString做值传递则会触发动态内存分配FName的创建里计算Hash使用了非常快的CityHash,然后比较相等的时候只需要比较id即可,不需要不需要执行FString的逐字节计算FName将前缀与数字后缀分离的设计更适合来做UE的路径唯一标识符
不过这些优势的前提是查询时传入的FString已经转化为了FName。如果将FString转换为FName的时间考虑进去的话,在没有数字后缀的字符串上可能没啥优势,因为创建FName的时候内部会有加锁。虽然使用了一个比较大的预分配ComparisonShards数组来避免使用一个唯一的全局锁,但是在没有冲突的情况下执行锁操作还是会有一定损耗的。知乎上的网友freestriker在FName的基础上做了一个简化版的全局字符串池,有兴趣的同志们可以去参考一下其简化实现InternedString
Unreal Engine 的 config 系统
前述的UDataTable主要是用来处理固定格式的批量数据,面对一些全局唯一配置的时候使用这个UDataTable系统就过于重度,且效率低下。面对这种全局唯一配置的需求,UE提供了配置文件来更方便的进行这些全局唯一数据的设定。
配置文件(Configuration Files或Config Files)提供 虚幻引擎(UE) 的初始设置。 在最基本的层面上,配置文件包含若干键/值对的列表,这些键/值对还组织为不同的分段。 这些文件用于为所有版本和平台设置在虚幻引擎启动时加载的对象和属性的默认值。 配置文件使用 .ini 文件扩展名, 其文件内语法结构如下:
[SECTION1]
<KEY1>=<VALUE1>
<KEY2>=<VALUE2>
[SECTION2]
<KEY3>=<VALUE3>
每个配置变量必须属于一个 [SECTION],并且必须包含 KEY 且后跟 = 符号。 例如,在 BaseEngine.ini 中:
[Core.Log]
LogTemp=warning
分段名称为字母字符串,可以将其设置为任何值。 无论项目代码中是否存在配置变量,配置系统都会加载配置文件中的所有声明。模块中包含的可配置对象的分段标题使用以下语法:
[/Script/ModuleName.ClassName]
其中:ModuleName代表包含可配置对象的模块的名称。ClassName代表ModuleName模块中包含可配置对象的类的名称。插件中的配置也是相同的,只不过需要将ModuleName替换为PluginName。
在配置文件中的Value可以有四种类型:字符串,数字,数组,结构体。这四种类型的表示方式可以参考官方文档。
然后配置文件是有优先级的,同一个配置项在不同优先级的文件中出现时,使用最高优先级的配置文件里设置的值。完整的优先级从低到高排列如下:
Engine/Config/Base.ini
Engine/Config/Base<CATEGORY>.ini
Engine/Config/<PLATFORM>/Base<PLATFORM><CATEGORY>.ini
Engine/Platforms/<PLATFORM>/Config/Base<PLATFORM><CATEGORY>.ini
<PROJECT_DIRECTORY>/Config/Default<CATEGORY>.ini
Engine/Config/<PLATFORM>/<PLATFORM><CATEGORY>.ini
Engine/Platforms/<PLATFORM>/Config/<PLATFORM><CATEGORY>.ini
<PROJECT_DIRECTORY>/Config/<PLATFORM>/<PLATFORM><CATEGORY>.ini
<PROJECT_DIRECTORY>/Platforms/<PLATFORM>/Config/<PLATFORM><CATEGORY>.ini
<LOCAL_APP_DATA>/Unreal Engine/Engine/Config/User<CATEGORY>.ini
<MY_DOCUMENTS>/Unreal Engine/Engine/Config/User<CATEGORY>.ini
<PROJECT_DIRECTORY>/Config/User<CATEGORY>.ini
同一个层级中,可以出现多个不同类别的配置分类,引擎自带的配置分类主要有:
- Compat(兼容性)
- DeviceProfiles(设备概述文件)
- Editor(编辑器)
- EditorGameAgnostic(编辑器游戏未知)
- EditorKeyBindings(编辑器按键绑定)
- EditorUserSettings(编辑器用户设置)
- Engine(引擎)
- Game(游戏)
- Input(输入)
- Lightmass(全局光照)
- Scalability(可扩展性)
配置文件加载完成之后,编程人员可以使用接口去手动的读取想要的配置项:
int MyConfigVariable;
GConfig->GetInt(TEXT("MyCategoryName"), TEXT("MyVariable"), MyConfigVariable, GGameIni);
除了GetInt外还有GetBool,GetString,GetDouble等多种接口。不过更好的方式是利用UObject系统自带的配置变量的支持来自动的将配置文件里的值填充到对应的UObject中。假设一个名为 MyGameModule 的模块有一个名为 AMyConfigActor 的类,并假设 AMyConfigActor 包含你希望能够在配置文件中更改的名为 MyConfigVariable 的成员变量,为了使用配置文件来自动设置初始值,我们需要做如下三步:
- 配置要在 UCLASS 声明中读取的配置文件类目。 此示例使用
Game类目:
UCLASS(config=Game)
class AMyConfigActor : public UObject
- 将类中要配置的任何成员变量标记为
Config:
UPROPERTY(Config)
int32 MyConfigVariable;
- 将上述变量设置在所选配置文件类目的层级中的任意位置。 例如,由于此示例使用
Game类目,因此可以在项目目录内的DefaultGame.ini中设置以下配置:
[/Script/MyGameModule.MyConfigActor]
MyConfigVariable=3
至于这里面如何自动映射与加载的原理这里就不再详细介绍了,因为这里面没有啥高深的技巧,也没有多少提升性能的空间,开发人员用就好了。