游戏服务端架构介绍
游戏服务端架构演进
其实关于游戏服务端架构演进的内容,已经有很多前辈总结过了。本人从业没多少年,经历过的项目也是屈指可数,所以本章的存在只是为了全书的完整性,简单的介绍一下。对于更多细节感兴趣的读者可以去阅读skywind3000前辈写的游戏服务端架构发展史。
单进程架构
单进程架构是游戏服务端最简单也最久远的架构,起源于1978年诞生的游戏服务器Multi-User Dungeon,简称为MUD1。此时游戏服务器只有一个进程,玩家的客户端可以通过telnet协议连接到游戏服务器,然后就可以通过文本输入来控制自己的角色来进行游戏。
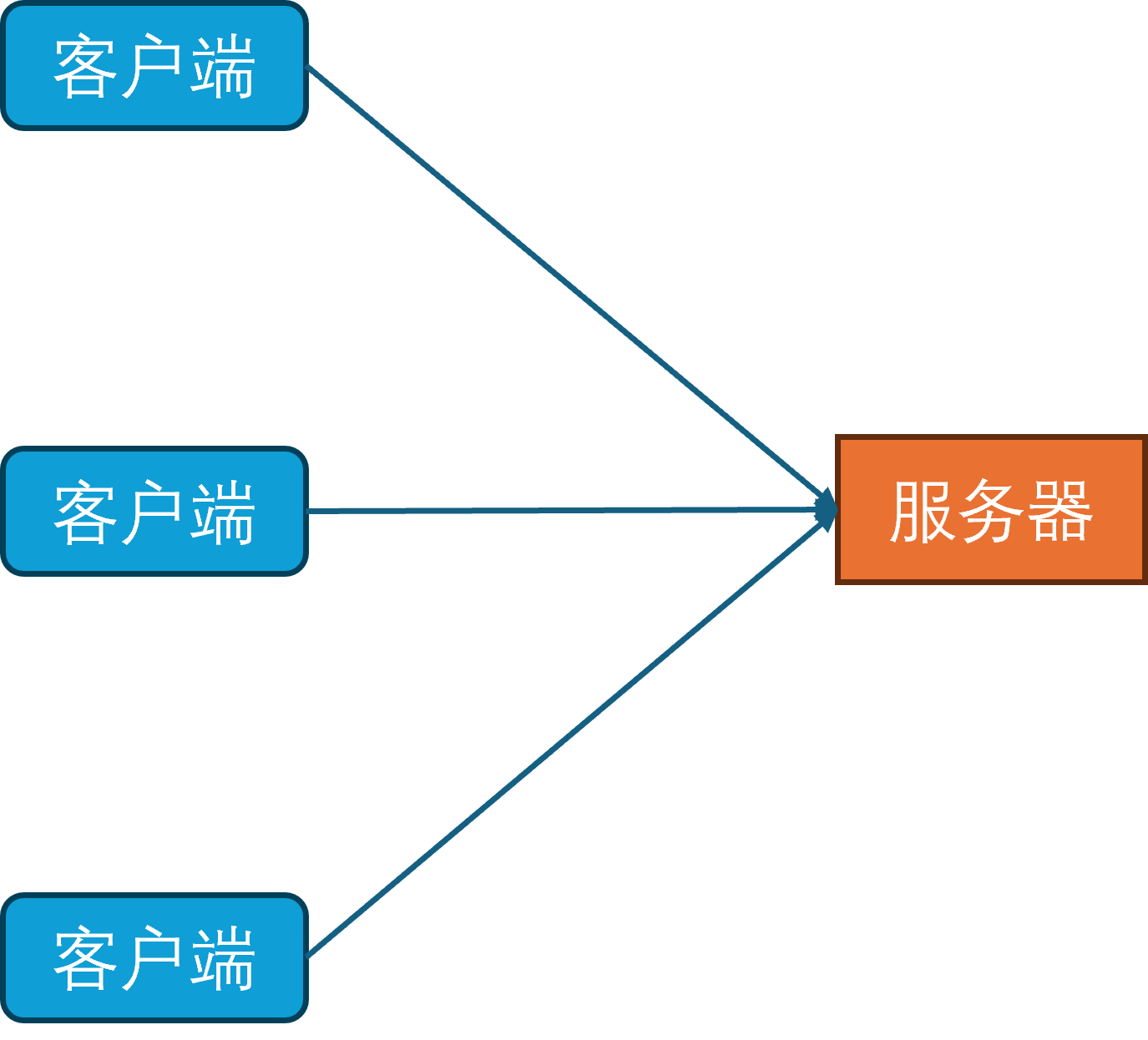
在MUD1中,服务器进程只有一个线程,网络收发使用非阻塞的网络IO模型,同时线程里会每隔1秒钟更新一次所有对象(网络收发,更新对象状态机,处理超时,刷新地图,刷新NPC)。同时玩家数据的持久化使用的是本地文件系统,每个玩家的数据都存储在一个单独的文件中。
数据库进程
随着互联网和硬件的发展,游戏内容也从纯文字进化为了图形化。由于图形化界面相对于纯文本界面能携带更多的信息,就使得单个玩家的游戏数据量急速膨胀。同时由于网络的逐渐普及,游戏服务器要服务器的玩家数量也逐渐增多。在这两个因素的影响下,基于小文件的持久化系统已经力不从心,因此开始引入数据库作为新的持久化手段。
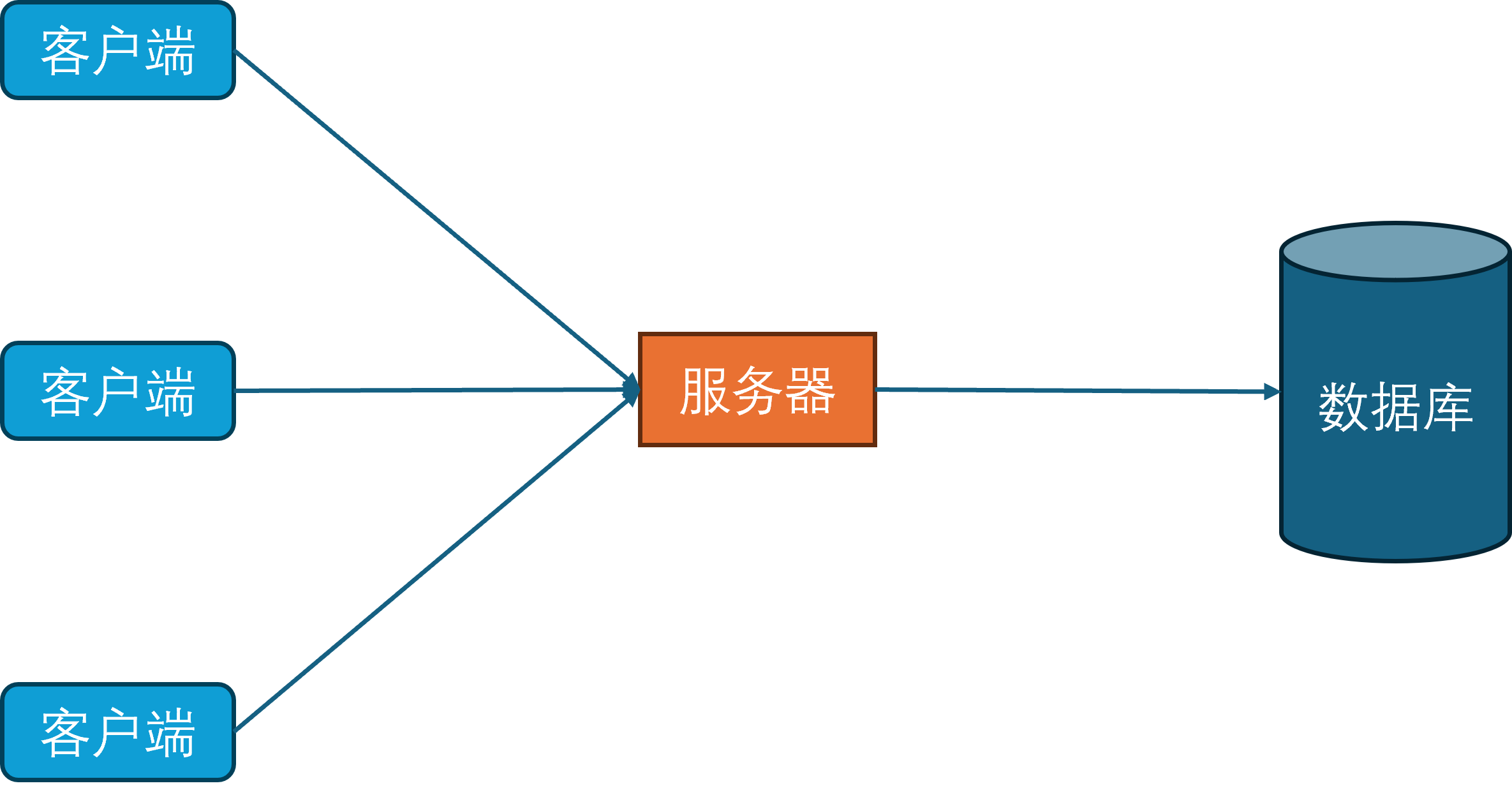
同时为了规范化游戏内对数据库的访问,开始引入数据库访问层。数据库访问层负责处理所有对数据库的访问请求,包括玩家数据的读取和写入。
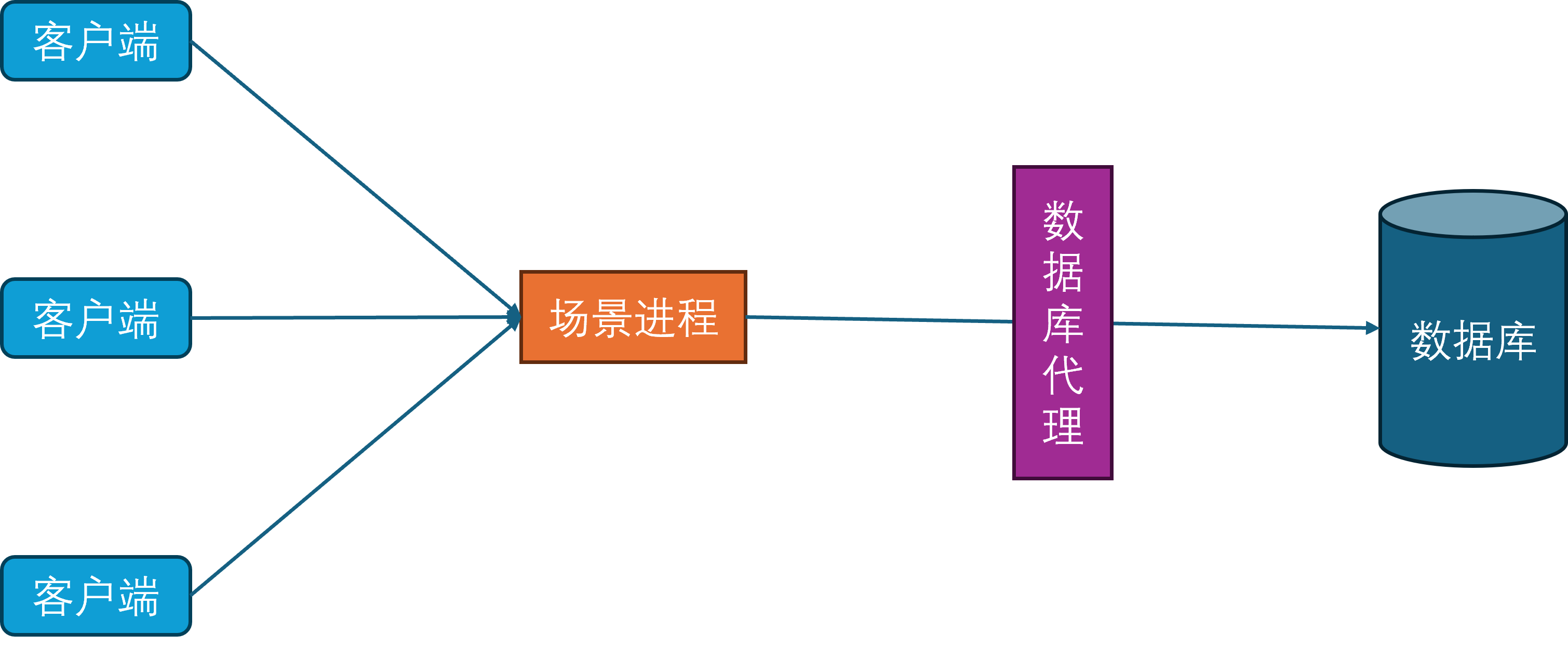
场景进程
当玩家在线数量持续增多时,当前的单场景进程的CPU就成为了瓶颈。为了提高游戏服务器的同时在线人数,开始对游戏场景进行水平划分,每个场景进程负责若干个独立的场景,每个场景负责管理一部分玩家。这种结构也就是常说的分区分服。
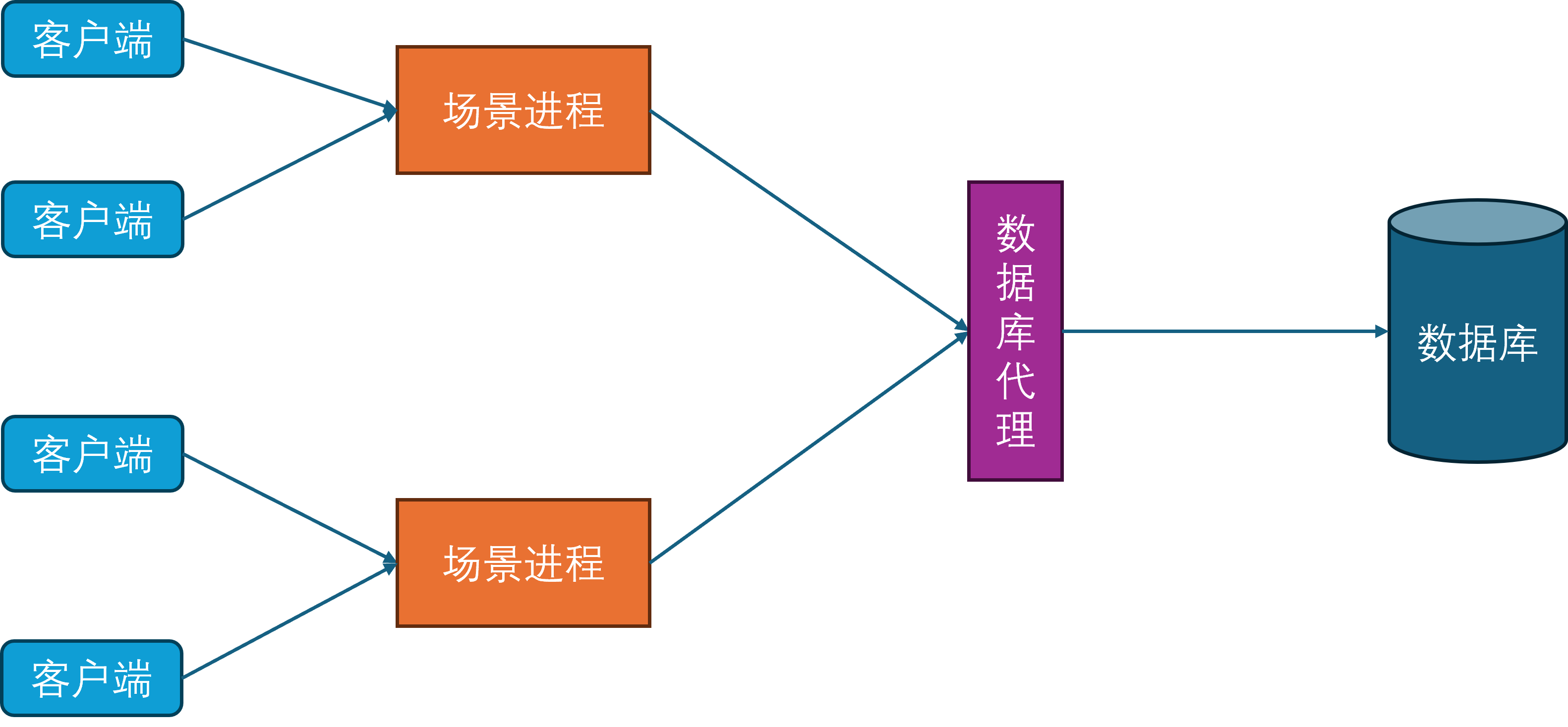
在这样的设计下,只要有无限的场景进程实例,就可以无限的扩展游戏服务器的同时在线人数。
由于玩家不会一直呆在同一个场景里,但是不同的场景被不同的场景进程负责。此时最简单的方法就是从原有的场景进程中下线并断开连接,然后往新的场景进程发起登录请求,这个下线再上线的过程会涉及到非常多的状态修改和数据交互。为了避免这些操作对游戏的影响,不同的场景进程之间开始出现互连,这样玩家数据就可以从一个场景进程传递到另外一个场景进程,避免了存库再从数据库中进行拉取的操作,这个过程就叫做玩家的迁移(Migration)。此时客户端只需要在迁移完成之后根据角色所在的最新场景进程通信地址发起一个新连接,同时断开对老的场景进程的连接,即可恢复游玩。这样就避免了繁重的上下线流程,减少了切换场景进程的延迟。
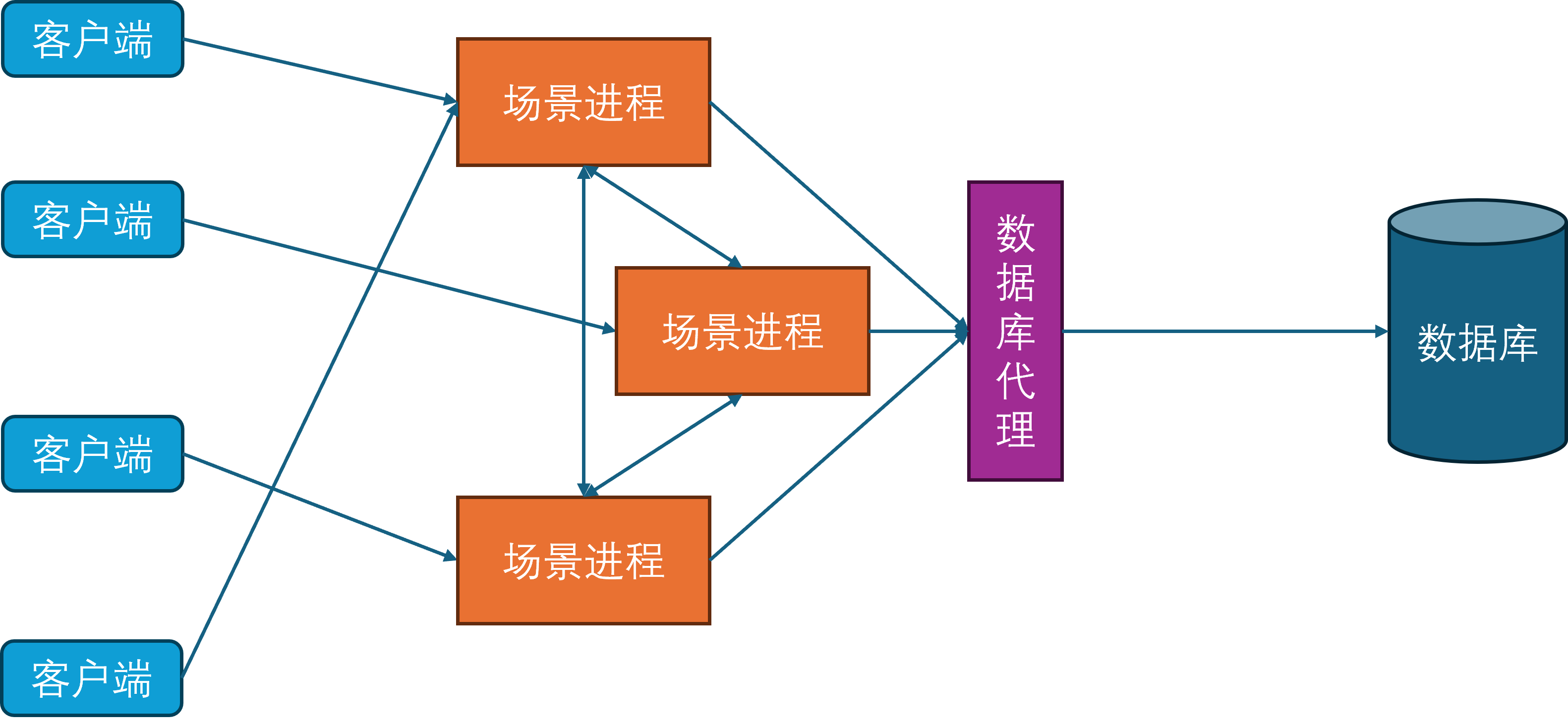
网关进程
由于常见的网络协议都建立在TCP之上,而TCP连接的握手和关闭过程都比较冗长,这就给玩家切换场景进程带来了不少的延迟。为了进一步减少这种迁移延迟,开始引入网关进程。网关进程承担的角色与Nginx类似,作为反向代理中转场景进程与客户端之间的通信,因此网关进程会与所有的场景进程建立连接。
此时客户端不再连接场景进程,只连接网关进程。这样做的好处是当一个玩家切换场景服务器的时候,客户端连接是不会断的,只需要在网关进程上更新一下这个客户端对应的场景进程关联。同时由于网关进程的功能比较简单,基本只负责通信转发,所以其单进程承载量可以达到上万。网关进程的引入还有一个好处就是可以隐藏后面的场景进程,提供一个统一的接入点的同时,避免了内部服务器暴露在公网,从而减少了服务器被DDOS和入侵的风险。
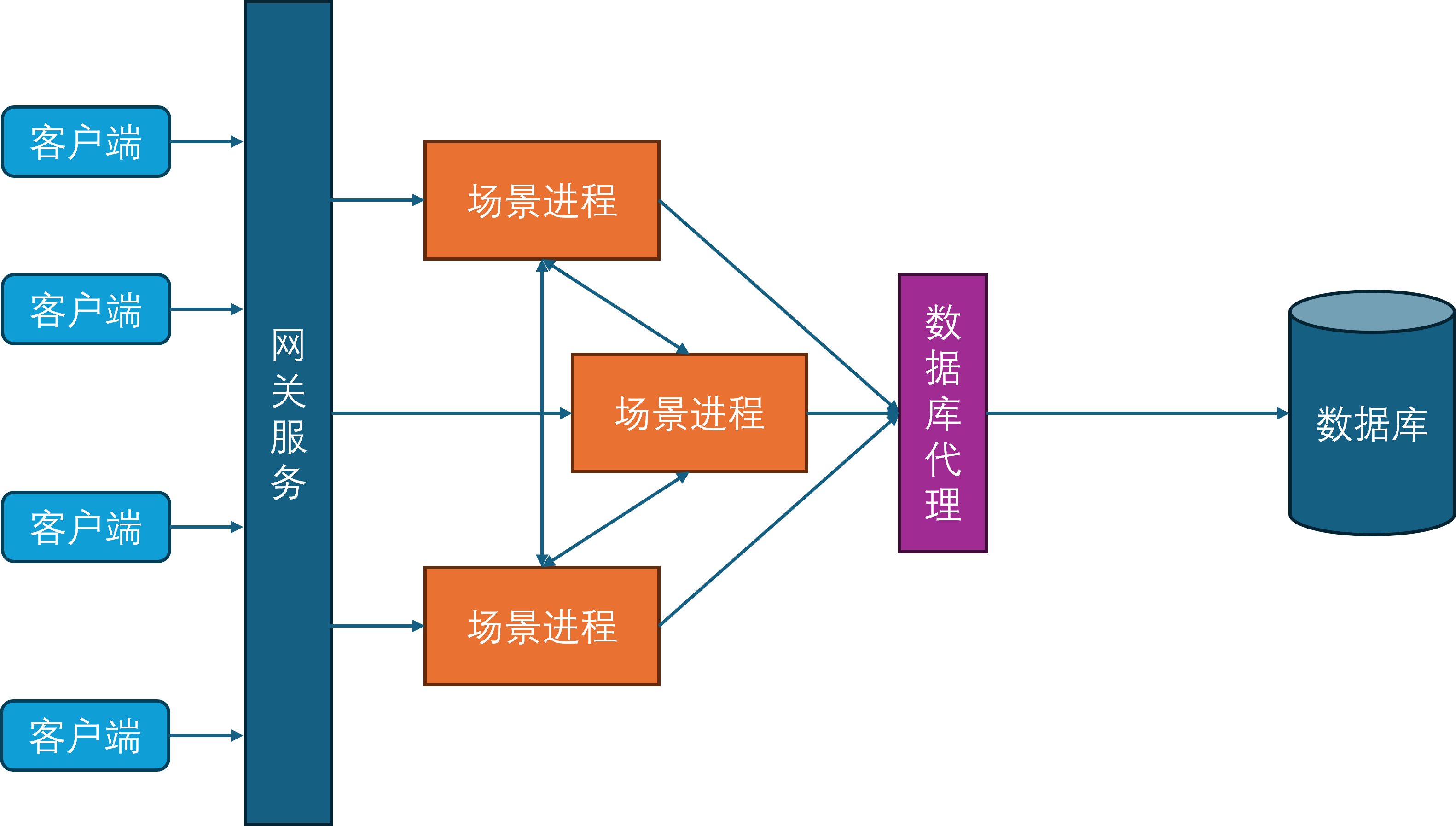
服务进程
随着游戏社交性的增强,游戏内玩家的交互对象不再仅限于同场景的其他玩家,还可以与其他场景的玩家进行交互,典型例子就是在副本内与其他不在当前副本里的好友聊天。为了支持这样的与场景无关的玩法需求,开始引入服务进程。服务进程负责处理所有与场景无关的游戏逻辑,比如登录服务、场景管理服务、玩家之间好友、组队、聊天等。
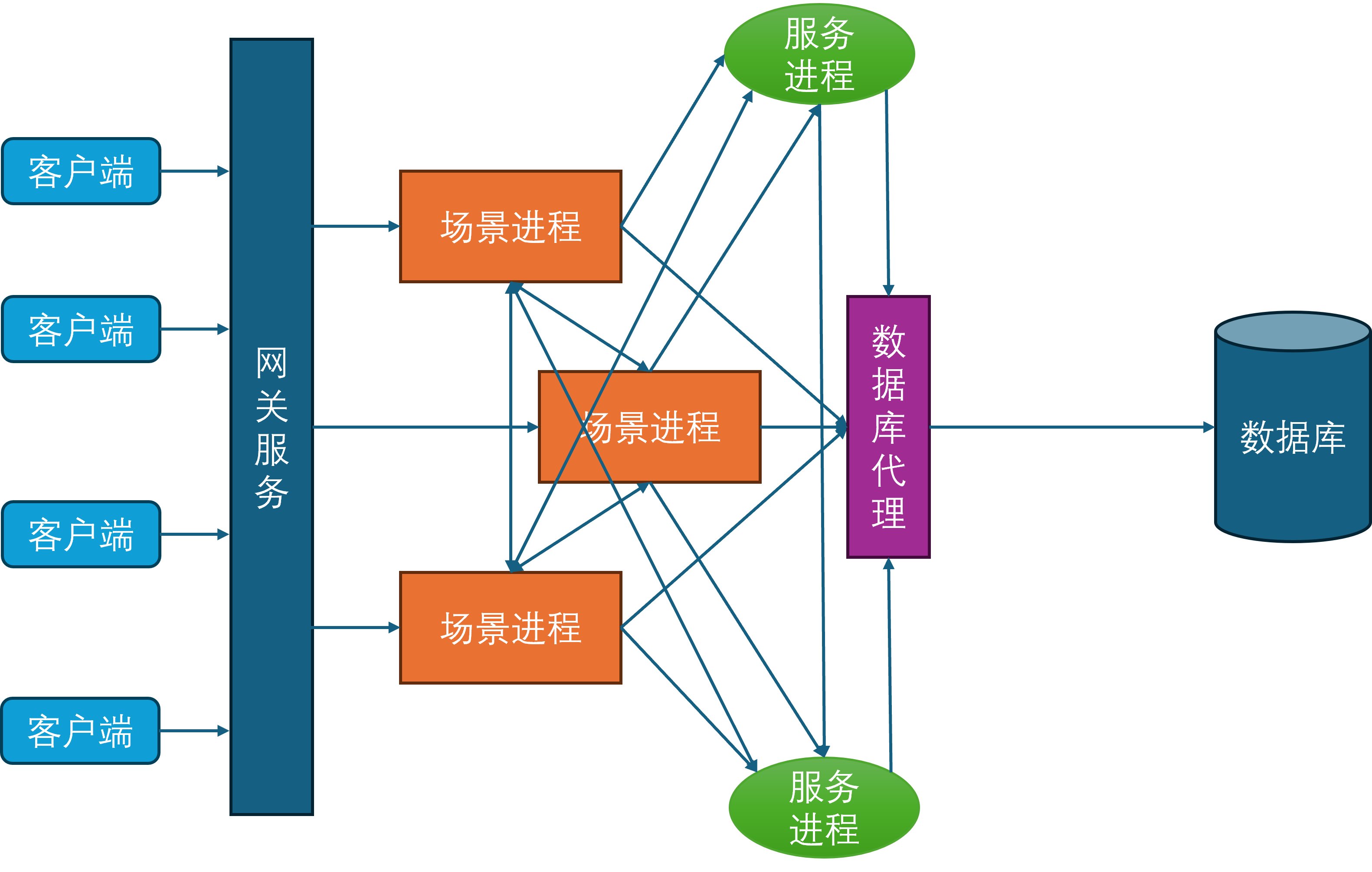
此时所有的场景进程都与服务进程建立连接,服务进程也会与其他的所有服务进程发起连接,因为服务之间可能出现相互调用,例如给好友发消息会先通过好友服务验证两者之间的好友关系是否存在,然后再通过聊天服务将聊天记录存库,最后再通过在线通知服务来提醒对方进行消息接收。
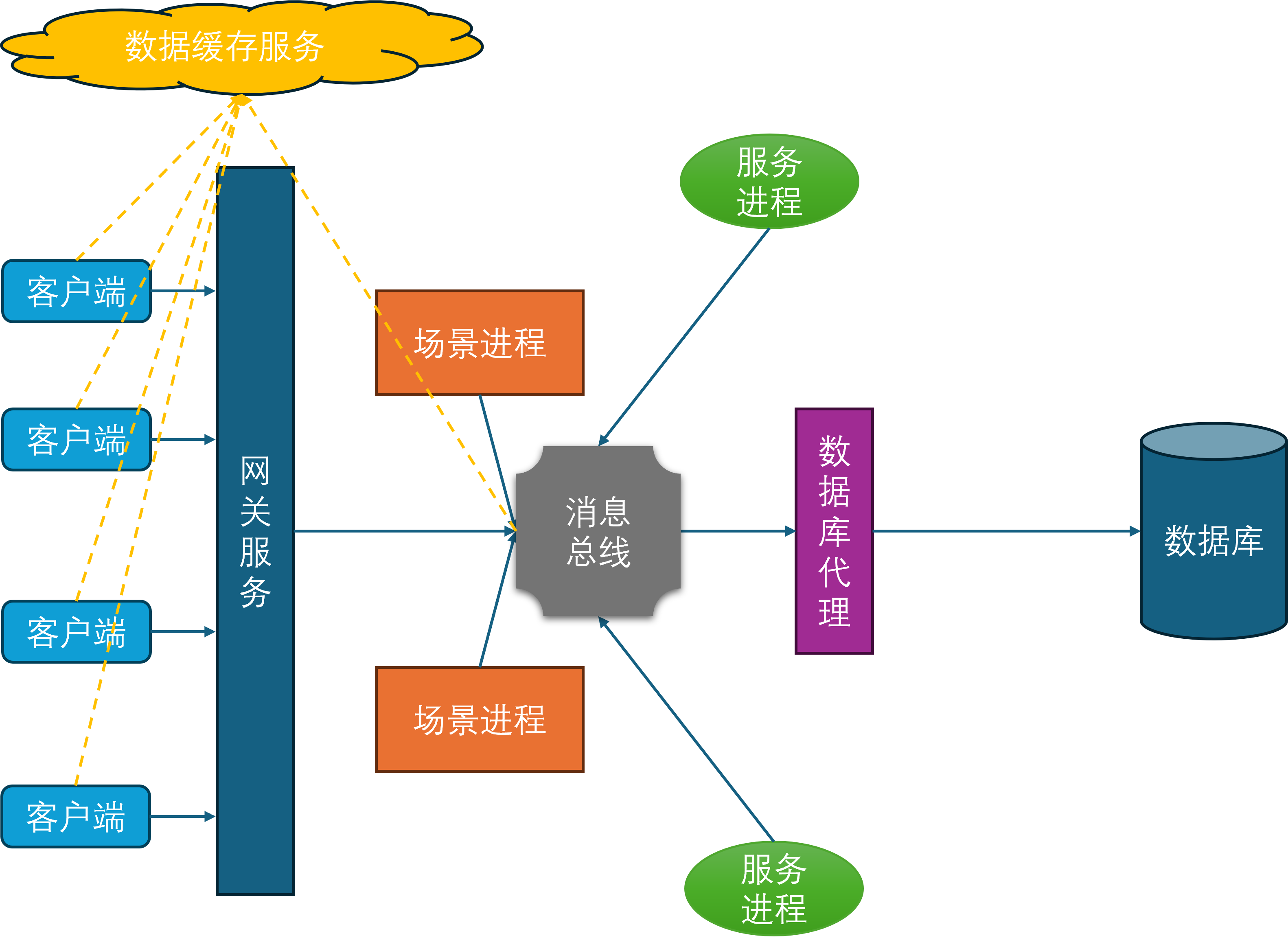
消息总线
在上面的服务器架构图中可以发现,场景进程与服务进程在某种程度上来说是等价的,对于包含所有场景进程的集合A和包含所有服务进程的集合B而言,A中的任意进程都需要维持到A+B这个集合中任意进程的连接,同时B中的任意进程也需要维持到A+B这个集合中任意进程的连接。所以A+B集合内的连接数量是的,是集合总大小的平方复杂度。虽然服务进程是有限的,但是场景进程基本上可以水平的无限扩充,同时场景进程还可以动态的扩缩容。在这种情况下,随着场景进程的数量逐渐增多,连接管理也会越来越复杂。为了减少连接管理的复杂度,隐藏进程间通信的细节,开始引入消息总线进程。
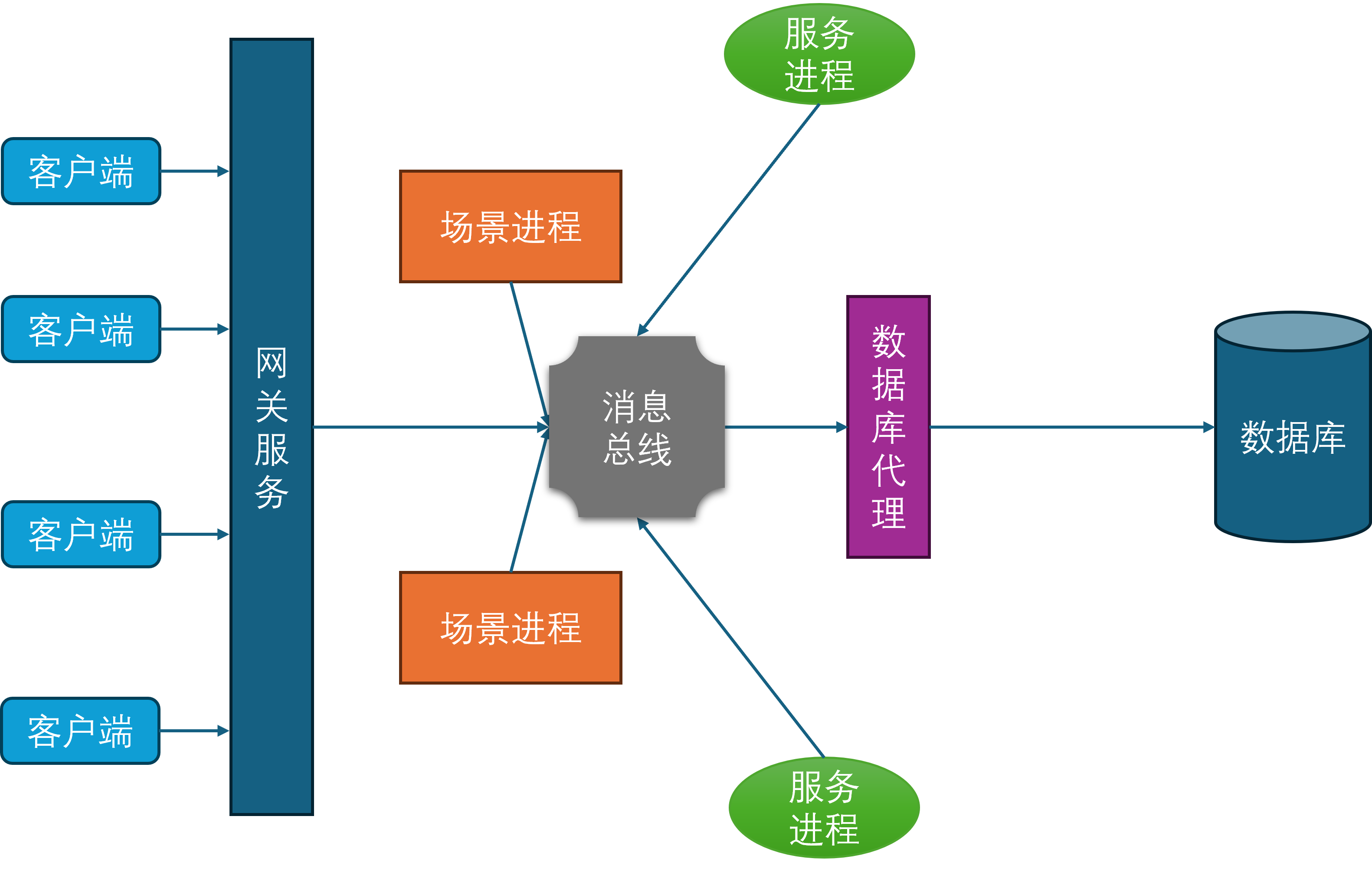
所有的场景进程、服务进程、网关进程、数据库代理进程都与消息总线建立连接,并通过消息总线来进行通信。这样就避免了每个进程都需要维护到其他所有进程的连接,同时也隐藏了进程间通信的细节,简化了开发和运维的复杂度。
一般来说,消息总线相关的进程会在每台物理机器上部署一个,这台物理机上的所有其他进程都会发起到本机消息总线进程的连接。然后每台机器上的消息总线进程又会统一的连接到一个全局的消息总线分发器,这个分发器会负责将消息路由到对应机器的消息总线进程上,并由目标机器的消息总线进程进一步分发到业务进程中。这样设计相对于所有业务进程都直接连接到全局的消息总线分发器来说,能够有效的减少消息总线分发器的网络连接数量。虽然消息转发相对于直接通过消息总线分发器来转发多了两次通信,但是这两次通信都是本机通信,速度很快,因此不会带来显著的延迟。如果消息的目标在本机的话,则不需要经过消息总线分发器,直接可以通过本机的消息总线进程来直接投递。
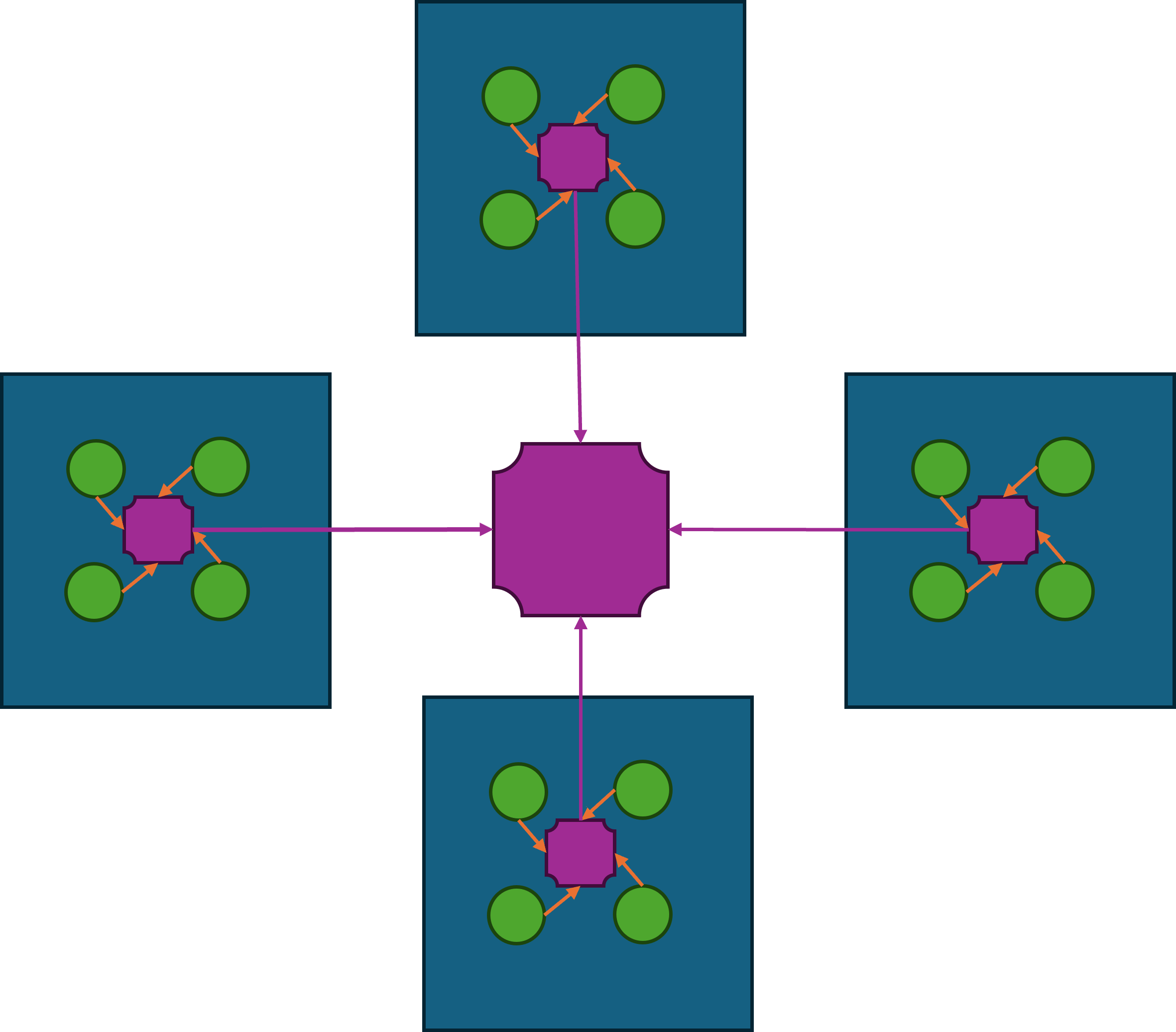
缓存服务
在当前设计下,客户端对于游戏数据的读取都需要经过网关->场景进程这两层中转,如果数据在服务进程上则会多加一层。对于一些变化频率不高但是拉取次数很多的数据,例如玩家的头像基本信息、定期结算的排行榜等,这些数据可以考虑放到游戏服务器之外去存储。这样客户端对这些数据的查询就可以完全不走前述的网关->场景进程这两层中转,同时有效的降低游戏服务器的CPU负载和流量压力。典型的数据缓存服务就是Redis集群,这个集群通过http的方式来暴露数据的查询与修改接口,这样客户端与服务端都可以很方便的与这个集群执行互操作。同时由于Redis集群的性能与吞吐量都很高,整体的机器收益是正的。而且这个Redis集群一般非常稳定,不需要跟随游戏服务器去更新部署,不会给服务端带来额外的维护负担。综合上述几个优点,基于Redis的数据缓存服务在游戏服务端非常流行。
分布式场景
在上述架构中,一个场景只会存留在一个场景进程中,所以这个场景内的玩家数量就会受到单个进程的计算能力限制。为了提升单场景的玩家数量上限,场景进程开始引入多线程,将一些计算密集型的阻塞任务放到多线程中执行,例如寻路线程、物理线程、网络线程、AOI线程等。这样做的好处是可以充分利用多核处理器的性能,降低主线程的一些负载,从而可以提升主线程单场景的玩家数量。但是由于游戏内的绝大部分的业务逻辑都是线性的,不方便拆分为异步任务投递到其他线程中,所以主线程单场景的玩家数量提升终归有限。
为了绕过这种由于主线程的性能瓶颈导致的单场景玩家数量上限问题,开始引入分布式场景。分布式场景的设计思想是将一个场景拆分成多个子场景,每个子场景都运行在一个独立的场景进程中。这样做的好处是可以将场景内的玩家数量分散到多个进程中,从而可以极大提升单逻辑场景的玩家数量上限。

这个场景划分并不是预先指定好的,而是随着场景内玩家数量的变化而动态调整的。例如当场景内玩家数量超过了某个阈值时,就会将场景拆分成多个子场景。当场景内玩家数量减少到某个阈值时,就会将多个子场景合并成一个场景。这个动态调整子场景布局的概念就叫做动态分区(Dynamic Partitioning)。为了方便计算边界以及合并、拆分,这些子场景的形状一般都是矩形。
由于玩家能够自由的在不同的子场景之间移动,一旦玩家从一个子场景移动到另一个子场景,就需要将玩家从原场景进程中移除,并将玩家添加到目标场景进程中,也就是需要执行一次玩家的迁移(migration)流程。由于常规的状态同步设计里一个玩家只能看到单进程内的其他玩家,这种越过边界导致的进程切换就会让客户端出现非常明显的同步状态变化。即属于上一个场景的实体都会被销毁,同时会突然同步当前场景里可见的一些实体。这种突然且剧烈的状态变化会给游戏体验带来非常严重的割裂感,解决这种由于迁移导致的客户端同步状态剧烈变化的技术就是无缝迁移(Seamless Migration)。
游戏服务端架构样例
在本书中,我将详细的介绍Bigworld、Unreal Engine、mosaic_game这三个游戏引擎在服务端的一些业务上的具体实现。为了方面读者理解后面章节中对那些充满了源代码的内容,在这里就先大致的介绍一些这三个引擎的基础设计以及一些核心概念。
BigWorld 服务端介绍
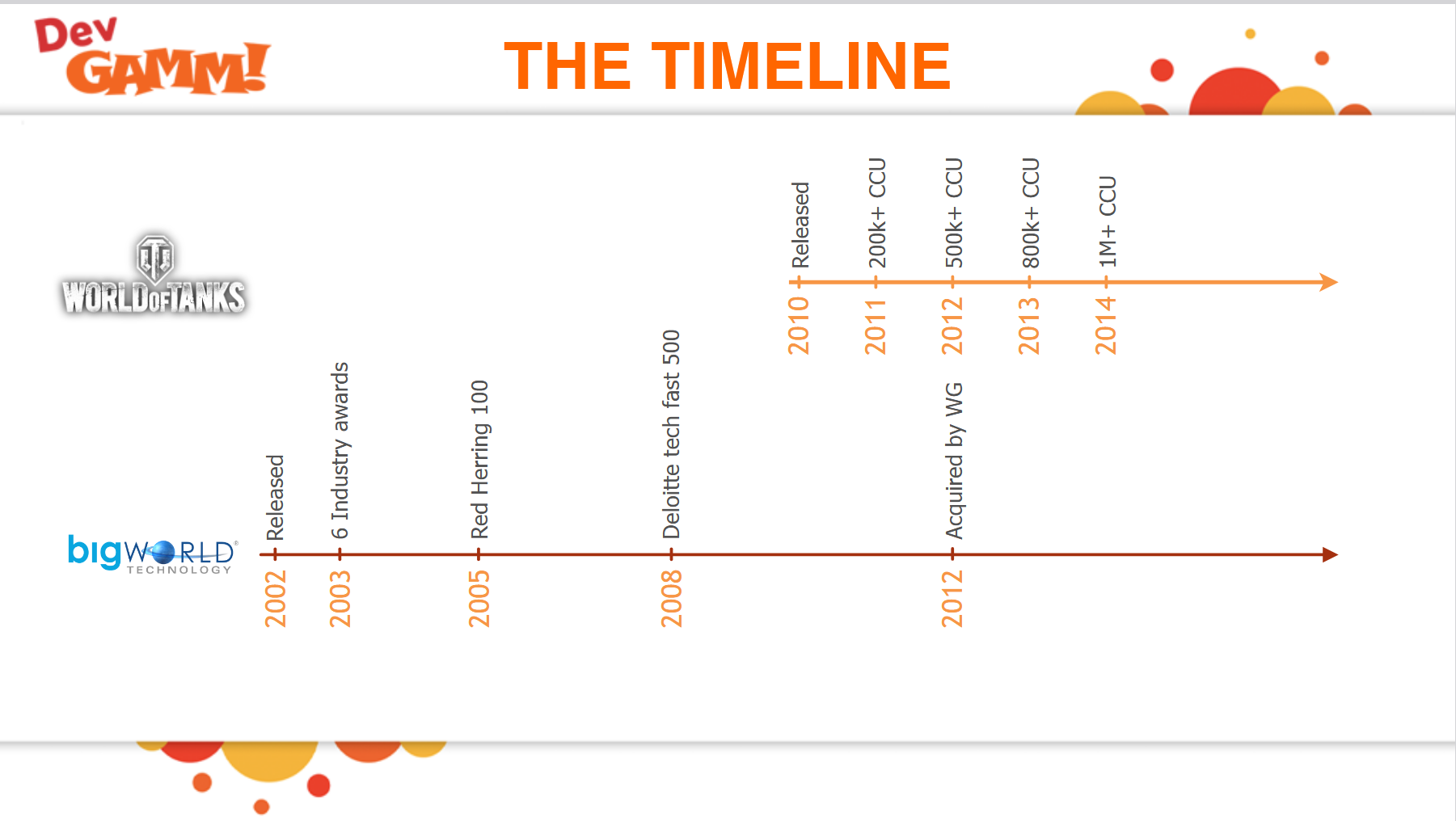
目前可以参考的服务端无缝大世界的资料只有BigWorld游戏引擎,使用这个引擎的游戏少之又少,其中最为知名的是坦克世界WorldOfTanks。根据其官方ppt6-years-of-bigworld-engine-evolution-caused-by-the-success-of-world-of-tanks,上面清楚的写着WorldOfTanks使用BigWorld引擎达到了一百万的ConCurrent User:
虽然使用这个引擎的游戏不多,幸运的是目前在Github上有这个引擎的开源代码,三年前公开在https://github.com/v2v3v4/BigWorld-Engine-14.4.1,我们可以通过这个公开源代码的版本来探究整体的服务端架构设计以及实现细节。下图就是bigworld服务端的整体架构:
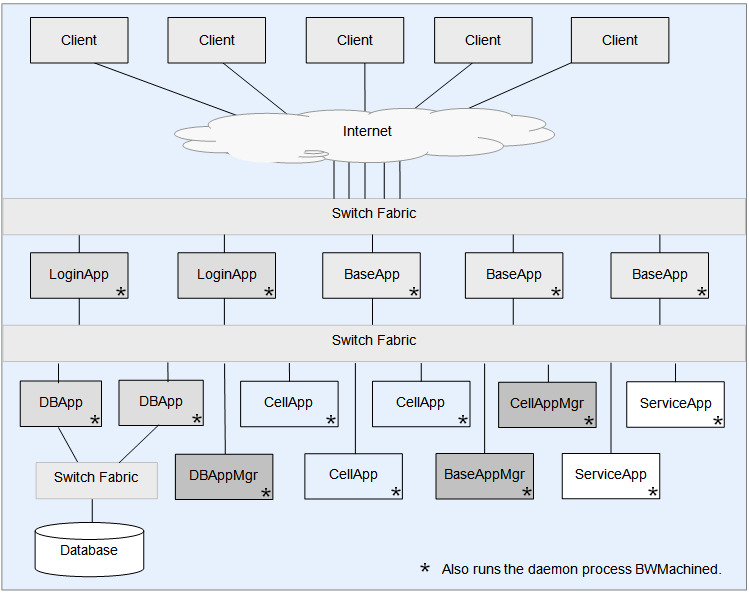
在这个架构图里,我们可以看到bigworld服务端主要由以下几种进程角色组成:
CellApp:场景服务器进程,每个进程负责管理一个或多个Cell。这里的每个Cell都对应一个分布式场景的矩形子区域。CellAppMgr:全局唯一的CellApp管理进程,负责维护所有CellApp的状态以及Cell的创建、销毁、迁移等操作。BaseApp: 实体服务进程,所有的可迁移实体都首先在BaseApp上建立,然后再根据其场景与位置信息往对应的CellApp上创建一个副本。同时对于玩家这种实体,BaseApp还会负责中转CellApp上的实体与对应客户端之间的消息交互。BaseAppMgr:全局唯一的BaseApp管理进程,负责维护所有BaseApp的状态以及BaseApp的创建、销毁、迁移等操作。LoginApp:登录服务器进程,负责处理玩家的登录、注册、验证等操作。DBMgr:全局唯一的数据库服务进程,负责代理所有对数据库的请求,。目前bigworld中使用的数据库是MySQL,但是DBMgr的设计是可以扩展到其他数据库的。
此外还有两个非常重要的进程角色没有在图中体现:一个叫做BWMachined进程,这个进程每个物理机上运行一个,其作用相当于消息总线和运维管理工具;另外一个叫做Reviver进程,这个全局只有一个,负责上述进程的心跳维持和崩溃时的重启。
在上述进程角色中,LoginApp和BaseApp是客户端可以直接连接的,其他进程则不允许客户端连接。因此官方说明书推荐LoginApp和BaseApp所在的物理机配置两个网卡,从而可以接入两个交换机:一个是外网交换机,负责将客户端的请求路由到对应的LoginApp或BaseApp上;另一个是内网交换机,负责将LoginApp或BaseApp上的请求路由到其他角色的进程上。
bigworld中使用一个Space类来表示表示一个完整地图,然后Space又根据负载情况动态分割成一个或多个矩形区域Cell。每个Cell负责Space的矩形区域是不会重叠的,且所有Cell的矩形区域的并集就是这个Space的完整区域。同时一个Cell的区域并不是固定的,会根据其相邻区域之间的负载分布情况来动态调整。全局唯一的CellAppMgr管理所有的CellApp,也就是场景服务器进程,一组服务器一般会有数十个CellApp。然后每个CellApp都会有不定个数的Cell在进程内执行。所以Space与Cell的相关信息都会经由CellApp上传到CellAppMgr上,通过这些信息就可以维护Cell的创建、销毁以及边界调整。
当一个客户端想连接到游戏服务器时,涉及到的流程以及进程角色如下:
- 首先会连接到
LoginApp上。LoginApp会验证客户端的登录信息, - 如果验证成功且通过
DBMgr从数据库里加载出来了对应的玩家数据,然后往BaseAppMgr发送这个玩家数据来请求创建对应实体。 BaseAppMgr接收到这个请求之后就会筛选出合适的BaseApp,并通知选定的BaseApp来创建一个proxy对象,代表对应的玩家。BaseApp创建proxy对象完成之后,就会反向通知BaseAppMgr操作完成,然后BaseAppMgr又会通知回LoginApp。- 此时
LoginApp就可以通知原来的客户端当前登录操作已经成功,且会附带上对应的proxy对象的地址。
客户端接收到登录成功的返回之后,就会以这个proxy对象地址去连接对应的BaseApp,请求将这个proxy对象绑定到当前的客户端连接,绑定的同时会下发这个玩家所有的客户端可见属性,让客户端创建一个对应的对象。
但是此时还没有进入场景,如果玩家想进入场景与其他玩家进行互动,流程链依然很长:
- 首先客户端发送一个进入场景的请求到
BaseApp上的对应proxy对象。 proxy对象就会以此为基础构造一个进入场景的请求,里面填充场景编号、位置数据以及当前proxy对象属性里的Cell可见属性,并将这个请求发送到CellAppMgr。CellAppMgr接收到这个请求之后就会根据传入的场景编号获取对应的Space, 然后再根据出生位置来计算出覆盖这个区域的Cell,并将这个进入场景的请求发送到这个Cell所在的CellApp。CellApp找到对应的Cell后,就会以请求里携带的玩家的属性数据来创建一个真正的RealEntity,并绑定proxy所在的通信地址为数据下行通道。创建成功之后会将这个RealEntity的唯一标识符返回给CellAppMgrCellAppMgr再附带这个Cell的地址返回给proxy对象。- 当
proxy对象接收到对应的RealEntity的地址之后,就会绑定对应RealEntity的通信地址为数据上行通道。
当RealEntity需要给对应的客户端发消息的时候,会先通过与对应proxy之间的通道来传递消息, proxy接收到消息之后,解析发现这是一个发往客户端的消息,就会转发到绑定的客户端连接。同时如果客户端的玩家对象想往对应的RealEntity发送消息,则也需要通过proxy进行中转。
由于Cell的区域是动态调整的,所以Cell之间的边界是会发生变化的,同时玩家又是可以任意移动的,所以玩家的RealEntity并不是一直绑定在同一个Cell上。当一个RealEntity绑定到一个新的Cell时,就会通知新Cell来创建一个新的RealEntity,同时老的RealEntity退化为一个GhostEntity,并通知对应的proxy对象切换上行通道的地址为新的RealEntity。一个RealEntity上发生的所有客户端可见属性的变化都会广播到其管理的GhostEntity集合,同时一个RealEntity下发的其他Entity的状态数据不仅包括周围的RealEntity,还包括周围的GhostEntity。如何通过RealEntity/GhostEntity来将分布式的场景营造成一个支持无缝迁移的统一逻辑场景复杂度其实挺高的,这也是Bigworld的核心技术所在。
Unreal Engine 服务端介绍
Unreal Engine(后文中将简称UE)是由Epic Games开发的商用游戏引擎,最早于1998年发布,之后更新了多个版本。在2014年发布了虚幻四(后文简称UE4),并在Github上公开了其源代码,这种开放使用的策略大大的加速了UE的推广。然后在2022年进一步的发布了UE5,其黑客帝国Demo令人印象深刻,使得UE5次世代大世界这个词组成为了一个不可分割的整体。使用UE开发的游戏有很多,近年来比较知名的有PUBG、堡垒之夜、黑神话悟空、三角洲行动等。而且UE不仅仅能做游戏,还在虚拟现实、增强现实、电影特效、建筑可视化等各种实时互动内容制作里大显身手。
UE引擎有一个跟其他引擎非常不一样的地方,就是他的服务端与客户端源代码是混合在一起的,打包的时候使用同一份代码进行打包。引擎里自动就维护好了客户端与服务端之间的通信协议和状态同步机制,不需要去额外的做开发工作,这种设定下打包出来的服务器叫做专属服务器Dedicated Server,简称DS。如果需要在运行时区分客户端与服务端,那么就需要在代码里进行判断。以官方UE4样例项目ShooterGame的一个函数AShooterCharacter::PostInitializeComponents为例,运行时可以通过GetLocalRole()来判断当前进程是否有这个AShooterCharacter的控制权,然后GetNetMode()这个接口来判断当前进程的角色是客户端还是服务端:
void AShooterCharacter::PostInitializeComponents()
{
Super::PostInitializeComponents();
if (GetLocalRole() == ROLE_Authority)
{
Health = GetMaxHealth();
// Needs to happen after character is added to repgraph
GetWorldTimerManager().SetTimerForNextTick(this, &AShooterCharacter::SpawnDefaultInventory);
}
// 省略一些代码
// play respawn effects
if (GetNetMode() != NM_DedicatedServer)
{
// 省略一些代码
}
}
更为厉害的是在编辑器内可以通过不同的命令行参数来分别启动客户端与服务端,这样可以非常方便的在编辑器里进行开发与测试。这样前后端代码一体化开发的方式,再加上UE引擎自带的蓝图(Blueprint)这个图形化编程工具,极大提升了非程序人员对UE引擎的接受度。
不过这样的一体化开发方式也有一些弊端,特别是服务端,因为服务端也需要处理物理、移动、骨骼动画等性能消耗非常高的任务,导致服务端的性能受到很大的限制,单进程的玩家承载量也受到了很大的限制,基本只能在100左右。正是由于这种承载量的限制,UE引擎目前适用的联网游戏类型基本都是一些匹配对战的开房间游戏,在需要大量玩家同场景的MMORPG(Massively Multiplayer Online Role-Playing Game)类型游戏中则比较少见。
UE打包生成的DS单个进程基本只能服务一个地图场景,在不深度修改的情况下无法做到多地图共存。而且单个DS进程长时间运行下会有比较严重的内存占用,所以一般来说单个DS进程只能存活比较短的时间,粒度基本都是以小时为单位,无法像MMORPG那样单个进程可以持续运行数周直到版本维护。同时UE开发框架里基本只能写地图内的玩家交互逻辑,无法作为聊天、好友、商城的常见游戏服务的进程宿主,导致还需要使用cpp/python/go等语言额外开发一些联网服务,并修改UE引擎来接入与这些服务相通信的RPC。所以一般使用UE作为房间服务器的服务端架构基本会设计成这个样子:
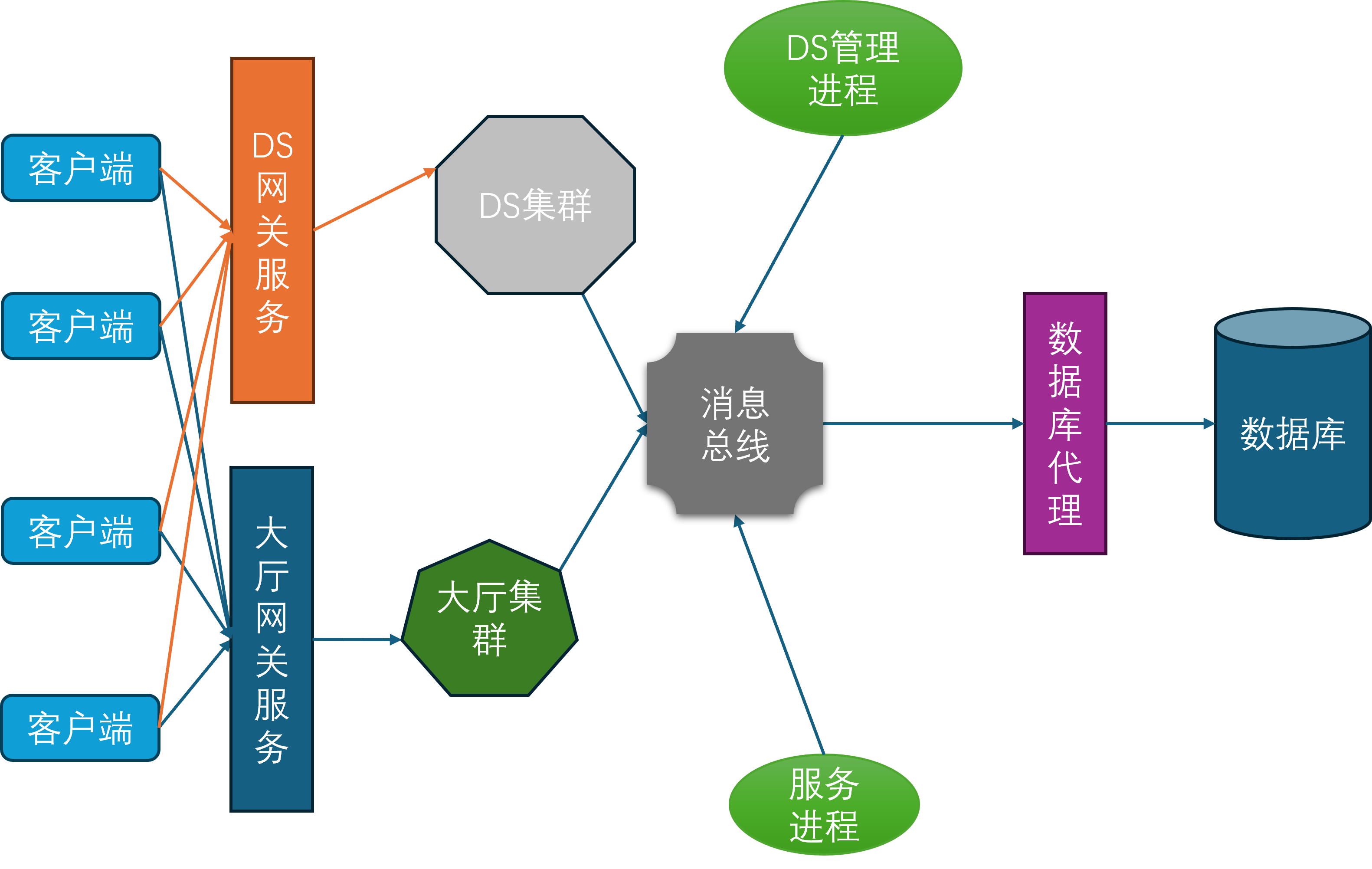
在这个架构图里,前置的网关分为了两种:一种是对接大厅服务的网关,采用TCP协议;一种是对接DS进程的网关,采用UDP协议。大厅服务主要负责玩家的注册登录、匹配、好友、组队、聊天等功能,而DS进程主要负责游戏场景的运行与玩家的交互逻辑。玩家客户端在启动之后,先连接到大厅网关服务,执行登录验证工作,登录成功之后就可以在大厅内执行一些场景无关操作。如果玩家需要进入特定的场景来进行相关玩法,则需要执行一个比较长的交互链条:
- 首先需要得到大厅服务这边的许可。当大厅服务认为可以进入特定场景的时候,会通知
DS管理进程DS Manager来获取一个可用的DS进程来加载这个场景。 - 其实这里还有一个类似于
Bigworld的BWMachined的DS Agent进程,部署在所有能承载DS的物理机器上,用来管理本机的所有DS的拉起、销毁和负载上报,这些DS Agent进程都受到接受DS Manager的管理。大厅请求DS Manager分配一个新的DS,DS Manager接收到请求之后会去找一个机器负载比较小的DS Agent,通知其创建一个新的DS进程,并加载指定的地图,开启特定的玩法。 - 当
DS Agent执行完这个DS进程的拉起操作之后,就会汇报给DS Manager,DS Manager就带上这个DS进程的地址信息通知回大厅。 - 大厅接收到目标
DS的地址信息之后,先通知到DS网关,给当前玩家加上目标DS的绑定,然后再通知当前玩家的客户端可以去发起到DS网关的连接。 - 客户端接收到
DS的连接允许信息之后,就会以UE的连接协议去连接到DS网关。注意此时客户端与大厅之间的连接是没有断的,所以此时客户端与服务器之间会同时存在两条连接通路。 DS网关此时会验证这个客户端是否有绑定的DS目标进程,如果有则开启一个UDP中转会话,用来桥接客户端与DS进程之间的UDP通信。
有的读者可能注意到UE里也有无缝迁移Seamless Travel的概念,但是这里的无缝迁移指的是一个DS进程以无缝的形式切换地图,此时客户端不需要断开与DS进程之间的连接,玩家控制的角色Character、控制器PlayerController和状态PlayerState能够自动的绑定到新的World。相对应的DS的非无缝迁移就是在切换地图之前DS通知所有客户端断开连接,然后再加载新的地图,此时客户端进程则重新执行连接与登录流程,这就会带来Character、PlayerController和PlayerState在服务端的销毁以及重新创建。
UE引擎是非常庞大的,包含了非常多的概念与模块,而且代码更新也极其频繁。在我有限的工作经历中,引擎重新编译涉及到的编译单元从UE4.23的不到2000个增长到现在UE5.5的将近6000个。不过跟服务端相关的Gameplay和网络相关功能UE4与UE5之间的差异并不大,所以本书所讲解的UE相关内容附带的代码都是基于UE4的。如果读者之前没有接触过UE,可以先去阅读一下Epic中国社区经理大钊在知乎写的系列文章Inside UE4,补充一下知识储备。当然读者如果完全对UE不感兴趣,可以在后文的阅读中直接跳过UE相关的章节。如果不是工作需要查证相关问题的话,我自己都有点看不下去这些源代码。
Mosaic Game 服务端介绍
mosaic_game这个项目创建于2020年,但是其实其使用的核心组件在2018年就可以开始陆陆续续的开发了。当时我负责了项目内的行为树与AI,但是当时的编辑器是PyQt实现的,代码非常扭曲,导出的数据文件居然是基于Pickle的,更新功能难度非常大。备受折磨的我准备使用CPP + QT5来重写,将数据格式改成json,顺带体验一下什么叫做GUI开发。完成了行为树编辑器的重新迭代之后,为了方便日常开发中的行为树问题调试,就给这个编辑器添加了调试器的功能。整个行为树开发套件开源在huangfeidian/behavior_tree上。刚好项目内有一套基于树形结构的角色数值属性计算系统,就顺带以这个图形化的编辑器框架为基础,构造了属性公式编辑器,以及属性公式求值运行时,开源在huangfeidian/formula_tree。
当时项目组使用的服务端引擎是没有源代码的,我们日常开发只能使用Python来写业务逻辑。写Python写烦了就开始琢磨这个引擎的底层实现,特别是玩家属性在Python脚本里修改之后是怎么自动同步到客户端的。当时Bigworld代码还未开源,同时UE4引擎还在我的认知之外,自己对CPP还很热情,因此开始从零开始用CPP来实现一个属性自动同步系统。这个属性自动同步系统还是比较复杂的,为此开发了好几个库:基于json的序列化与反序列化库huangfeidian/any_container;基于libclang的CPP反射库huangfeidian/meta;最终的属性修改自动同步库huangfeidian/property_sync。
在开发huangfeidian/meta这个CPP反射库的过程中,发现这个库提供的元数据收集加代码生成功能不仅可以为上面的属性同步系统服务,还可以来构造基于json的RPC系统,甚至还可以以此来构造基于Actor/Component的Entity系统。构造完这些系统之后发现项目组使用的游戏服务器的大半功能都被覆盖了,为什么不去整个大活,仿造一个完整的游戏服务器!刚好在网络通信上我也有一些积累,基于boost/asio实现过一个带流量加密的http代理服务器huangfeidian/http-proxy。于是就有了mosaic_game这个项目的诞生,开始了我慢慢填坑的过程。
这个mosaic_game是基于纯CPP实现的,但是CPP的包管理功能很弱,不像Python有很多开箱即用的库,因此在开发这个项目的过程中,我需要自己实现很多功能。为了方便游戏内各个功能的验证与调试,避免每次都启动整个游戏服务器通过再添加日志来定位问题,后续功能的添加基本都是以库的形式来组织的,除了上述介绍的功能之外,主要的功能库还有:
- 将
excel表格中的数据转换为json的工具库huangfeidian/typed_matrix。这个库里还引用了我写的另外两个小组件:用来规定和验证excel数据格式的huangfeidian/typed_string和用来读取excel文件的huangfeidian/xlsx_reader。 - 聚合了各种
AOI计算方法的库huangfeidian/aoi。 - 聊天系统huangfeidian/chat。
- 事件和状态机库huangfeidian/events。
- 匹配系统huangfeidian/match_maker。
- 游戏内的
Entity系统huangfeidian/entity_component_factory。 Redis桥接库huangfeidian/http_redis。MongoDB桥接库huangfeidian/http_mongo。- 基于
RecastNavigation的异步寻路库huangfeidian/AsyncDetourCrowd。 - 分布式场景管理库huangfeidian/distributed_scene。
通过集成上述功能,并不断的完善基础的游戏玩法,mosaic_game逐渐有了一个完整的游戏服务器雏形,下图就是最终的服务端架构图:
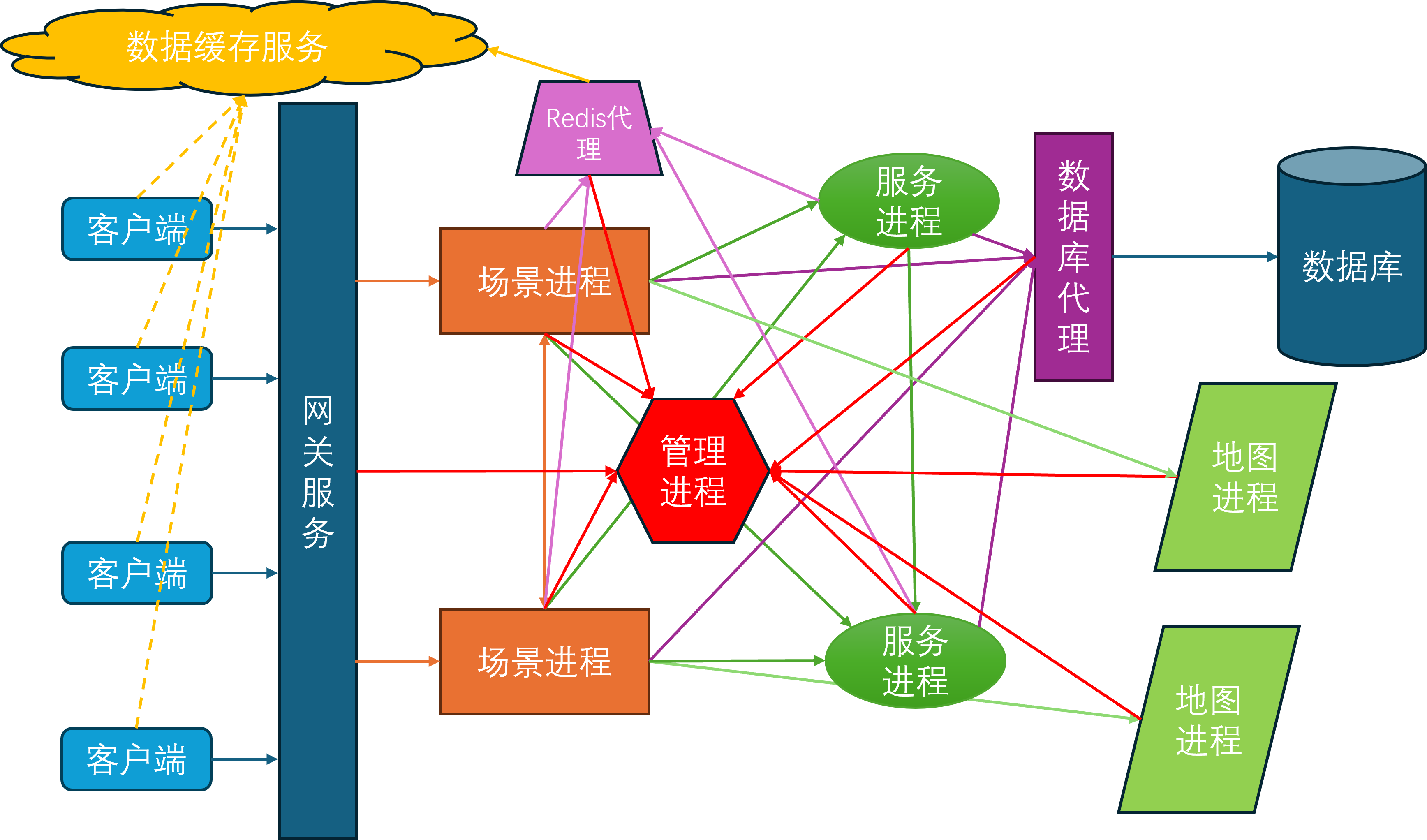
在这个架构图里,除了外部提供的Mongo进程和Redis进程,主要的进程角色有:
- 管理进程
mgr_server,全局唯一,负责管理整体服务器集群的启动与退出,每个其他进程启动之后都需要向mgr_server注册。当一个进程完全可用之后,会通知mgr_server,然后mgr_server会将这个新进程的信息广播到现有的所有进程。同时mgr_server负责收集各个进程的负载信息,以方便执行一些进程角色的负载均衡 Redis代理进程redis_server,可以有多个,负责代理其他进程与Redis服务器进行交互,MongoDB代理进程db_server,可以有多个,负责代理其他进程与MongoDB数据库进行交互- 服务进程
service_server,可以有多个,作为承载社交等场景无关逻辑的容器,一个service_server内可以有多个service - 场景进程
space_server,可以有多个,作为承载游戏场景逻辑的容器,一个space_server内可以有多个space - 网关进程
gate_server,可以有多个,负责中转客户端与space_server之间的通信 - 地图进程
map_server,可以有多个,负责管理游戏场景中的地图数据,目前只承担了地图寻路功能,一个map_server可以为多个场景提供地图服务
由于当前的设计里还没有集成消息总线,所以目前的进程间互联图看上去乱糟糟的,等以后有空了去使用消息总线来简化一下连接拓扑:
- 所有进程都需要连接到
mgr_server - 每个
space_server和每个service_server都需要连接到一个redis_server和一个db_server - 每个
space_server都需要连接到所有的service_server,这样space_server上才知道任意一个service在哪一个service_server上 - 每两个
space_server之间都需要有一个连接 - 每个
space_server都需要连接到一个map_server - 每个
gate_server都需要连接到所有的space_server
在当前的服务端架构之下,只有gate_server是外网可以直接访问的,此时客户端的登录和进入场景的流程是这样的:
- 客户端以某种方式获取当前可用的
gate_server列表,随机选择一个gate_server发送会话建立请求 gate_server接受了这个连接之后,先执行加密握手,验证客户端的身份,创建一个会话,并商定后续的对称加密密钥gate_server随机选择一个space_server来创建这个客户端对应的服务端账号对象account_entity,然后属性同步系统会通知客户端来同步创建这个client_account,之后gate_server就会当作一个透明的通信中转代理的作用,因此不再提及- 客户端
client_account对象再发起一个登录请求,包含账号密码 space_server上的对应account_entity收到登录请求后,将登录请求转发到登录服务login_service上login_service收到登录请求,通过db_server查询账号密码是否正确,并将验证结果下发到account_entity,如果正确则记录当前账号已经在线space_server上的account_entity收到登录验证结果后,根据验证结果来通知客户端登录成功或失败,如果成功则开始往db_server请求这个账号的角色列表数据,并进行角色列表的下发- 客户端的
client_account收到角色列表数据后,通知服务端account_entity来选择其中一个来创建角色 space_server上的account_entity收到角色选择请求后,通过db_server查询所选角色的完整数据,并以此数据来创建角色对象player_entityspace_server上的player_entity创建完成之后,属性同步系统会将player_entity的属性同步到客户端,通知客户端创建角色对象client_player- 客户端的
client_player创建完成之后,可以发送RPC到space_server上的player_entity来申请进入特定场景 space_server上的player_entity收到进入场景请求后,会转发这个请求到场景服务space_service上space_service检查是否有对应的场景space_entity,如果没有则通过负载均衡选择一个space_server来创建一个新的场景space_entityspace_service找到合适的space_entity之后,将这个player_entity添加到space_entity的玩家列表中,同时通知player_entity开始切换到目标space_entity中,space_server上的player_entity开始执行场景切换,这个切换可能发生在同一个space_server上,也可能发生在不同的space_server上,如果是不同的space_server则还涉及到迁移流程,这里就不去展开了space_server上的player_entity进入到新的场景之后,属性同步系统会将新场景的属性同步到客户端,通知客户端切换到新的场景- 客户端的
client_player收到场景切换通知后,开始执行场景切换,并填充场景属性数据,通知space_server上的player_entity场景切换完成 space_server上的player_entity收到客户端场景切换完成通知后,AOI系统就开始工作,开始向客户端同步周围的其他entity的状态
上述流程虽然冗长,但是好在都是面条代码,逻辑复杂度都非常低,实现起来都比较简单,大概2022年就完成了这些内容。但是随着无缝迁移这个目标的引入,场景管理和属性同步系统就需要大修,这样就缝缝补补了一年多才搞好。现在看上去无缝迁移的核心问题都被解决了,但是后面我已经没有多少精力去做各种测试样例,所以不保证当前的mosaic_game能够像想象中的样子来正确支持无缝迁移, BUG应该会有很多。好在应该没有人会在实际项目中使用mosaic_game这个玩具,这样我就先心安理得的休息一段时间,等有空了再去补这些单元测试。