逻辑驱动机制
游戏中各式各样entity都是为了管理游戏逻辑而创建的,各种类型的entity承担了游戏中不同的角色与功能。这些角色功能不仅仅支撑了场景内各种可见物体的静态几何体,而且还通过各种方式来运行自定义逻辑,从而驱动游戏内的状态改变。一般来说游戏都会有一个主循环来不断的执行tick,但是如何在这个tick函数里驱动这些entity的状态修改就不是那么容易了。因为entity数量实在是太多了,直接给所有entity加上tick接口, 然后在游戏循环的tick函数里遍历所有这些entity来执行这个tick函数是一个非常原始的设计。因为这样做的话,所有的逻辑代码都需要实现在entity::tick里,会导致entity::tick函数体急速膨胀。为了避免这个entity::tick函数膨胀到无法维护,需要采取有效机制来维护entity内各个逻辑的组织关系,解耦逻辑执行流的上下文。目前游戏内用来组织逻辑关系的方法可以归为如下几类:
- 基于虚函数接口的逻辑驱动
- 基于事件分发的逻辑驱动
- 基于计时器的逻辑驱动
- 基于异步回调的逻辑驱动
- 基于
RPC的逻辑驱动
接下来我将对虚函数接口、事件分发、计时器、异步回调这几种主要的逻辑驱动机制做一些详细的解读,至于RPC部分,后面有一个额外章节来做专门的介绍,所以在本章节中略过。
基于虚函数接口的逻辑驱动
虚函数是cpp的class自带的功能,他在基类定义统一接口的同时,频闭了每个具体类型在这个接口下的具体逻辑。下面就是一个虚函数简单例子,在animal基类上声明了一个make_voice的虚接口,然后子类cat,dog都用自己的逻辑实现了这个接口:
class animal
{
public:
virtual std::string make_voice() = 0;
};
class dog: public animal
{
public:
std::string make_voice() override
{
return "wang";
}
};
class cat: public animal
{
public:
std::string make_voice() override
{
return "miao";
}
};
这样我们就可以在拿到一个基类animal的指针A时,可以放心的调用A->make_voice()来执行已经声明的虚函数,而不需要关心这个指针所指向的具体类型是什么,这就是面向对象编程中常说的多态。在cpp语言中多态的实现依赖于两个组件:
- 虚函数表
V-Table:每个包含虚函数的类都有一个虚函数表,表中存储了指向类中所有虚函数的指针。 - 虚函数指针
V-Ptr:子类对象中包含一个指向该类虚函数表的指针。
在没有虚函数之前,要达到类似的效果只有两种方式:
- 在基类
animal中提供一个子类类型字段表明当前的子类是哪一个,子类被创建的时候需要设置好这个子类类型字段,然后执行make_voice的时候判断这个类型字段是dog还是cat执行不同的逻辑 - 在基类
animal中提供一个字段make_voice_func来存储std::string void()类型的函数指针,子类被创建的时候需要设置好这个接口函数字段,然后执行make_voice的时候直接调用return make_voice_func()
第一种方式需要我们在基类中知道所有可能的子类的所有接口逻辑,这样才能基类中根据这些子类的类型执行具体的分支,这种方式只适合子类型数量少且不会再扩张的情况,因此其限制性非常大,基本无法在实践中使用。 第二种方式就是在cpp诞生之前常见的子类型扩张方式,以函数指针的方式来变相的实现虚函数,这种接口实现方式有一个很大的缺点就是每个实例都需要虚函数数量一样多的字段去存储这些函数指针,在虚函数多且实例数量多的时候比较浪费内存。如果每个具体类型以共享同一个函数数组的方式来减小内存开销,这样就相当于以一种非常蹩脚的方式重新实现了一次虚表。
通过上述分析可以看出,以虚函数表的形式去实现多态有如下优势:
- 代码复用:通过基类指针或引用,可以操作不同类型的派生类对象,实现代码的复用。
- 扩展性:新增派生类时,不需要修改依赖于基类的代码,只需要确保新类正确重写了虚函数。
- 解耦:多态允许程序设计更加模块化,降低类之间的耦合度。
在server_entity上,我们定义了如下的一些虚函数,以方便外部代码驱动相关逻辑:
// 执行初始化逻辑
virtual bool init(const json::object_t& data);
// 执行rpc分发逻辑
virtual utility::rpc_msg::call_result on_rpc_msg(const utility::rpc_msg& msg) = 0;
// 执行网络消息分发逻辑
virtual utility::rpc_msg::call_result on_entity_raw_msg(std::uint8_t cmd, std::shared_ptr<const std::string> msg);
virtual ~server_entity()
{
}
virtual void deactivate()
{
m_callback_mgr.clear();
m_is_active = false;
}
同时任意一个支持component的entity上,会同时继承server_entity和component_owner,所以还会从component_owner这个基类继承一些组件相关的接口:
// 用来分发rpc
virtual utility::rpc_msg::call_result rpc_owner_on_rpc(const utility::rpc_msg& cur_msg);
virtual std::optional<utility::rpc_cmd_info> get_rpc_cmd(const std::string& cmd) const;
virtual void destroy()
{
clear_components();
}
virtual ~component_owner()
{
destroy();
}
可以看出,虚函数接口中最重要的就是rpc分发,以至于在server_entity和component_owner上定义了两个类似的接口,同时最终子类会将这两个接口进行合并:
utility::rpc_msg::call_result actor_entity::on_rpc_msg(const utility::rpc_msg& msg) override
{
return rpc_owner_on_rpc(msg);
}
using actor_entity_RpcSuper = utility::component_owner<actor_component, actor_entity>;
utility::rpc_msg::call_result actor_entity::rpc_owner_on_rpc(const utility::rpc_msg& data) override
{
auto temp_result = rpc_helper::rpc_call(this, data);
if(temp_result != utility::rpc_msg::call_result::rpc_not_found)
{
return temp_result;
}
return actor_entity_RpcSuper::rpc_owner_on_rpc(data);
}
因此一次rpc分发起码要经过on_rpc_msg和rpc_owner_on_rpc这两个虚函数,这样的无逻辑中转其实是没有意义的,值得后续优化掉。
我们在server_entity上提供的虚函数接口很少,基本只保留了消息分发相关接口。但是我们在其子类actor_entity上开始提供大量的虚函数接口声明,因为actor_entity才是我们平常处理的最主要entity,包括player_entity,monster_entity,trap_entity等多个子类。在actor_entity上提供的主要外部流程驱动接口如下:
// 迁移出本进程时 通知所有component 并执行数据打包
virtual void migrate_out(json::object_t& migrate_info, bool enter_new_space);
// 迁移到本进程时 通知所有component 并执行数据解包
virtual bool migrate_in(const json::object_t& migrate_info, bool enter_new_space);
void set_space(space_entity* in_space);
// 通知当前actor往指定的cell创建一个ghost
virtual bool try_create_ghost(const std::string& cell_id);
// 通知当前actor往指定的cell进行迁移
virtual bool try_transfer_real(const std::string& cell_id);
// 通知当前actor销毁指定cell里的对应ghost
virtual bool try_destroy_ghost(const std::string& cell_id);
// 迁移时执行actor与component数据打包
virtual void encode_migrate_out_data(json::object_t& migrate_info, bool enter_new_space);
// 创建ghost时 打包ghost所需数据
virtual void prepare_ghost_data(json::object_t& ghost_data);
// 向当前的relay anchor发消息 如果是global entity则这个anchor就是自身的anchor
virtual void call_relay_anchor(const utility::rpc_msg& migrate_msg);
// 进入场景时的回调
virtual void enter_space();
// 离开场景时的回调
virtual void leave_space(space_entity* cur_space);
除了entity上定义了一些驱动接口之外,在component上也可以添加接口,典型样例就是actor_component:
class actor_component_interface
{
public:
virtual void on_leave_space(space_entity* cur_space);
virtual void on_enter_space();
virtual json::object_t encode(bool for_ghost);
virtual void migrate_in(const json::object_t& migrate_info, bool enter_new_space);
virtual void migrate_out(bool enter_new_space);
virtual void on_become_ghost();
virtual void on_become_real();
virtual ~actor_component_interface();
};
这些actor_component_interface上声明的接口基本可以与actor_entity上的相关接口对应起来。以enter_space为例,actor_entity在执行此函数的时候需要遍历所有的actor_component并执行对应的on_leave_space接口:
template <typename F>
void call_component_interface(F& func)
{
for(auto one_comp: m_components)
{
if(!one_comp)
{
continue;
}
func(one_comp);
}
}
void actor_entity::enter_space()
{
m_prop_flags = actor_data_prop_queue::get_actor_property_flags();
auto cur_lambda = [](actor_component* cur_comp)
{
cur_comp->on_enter_space();
};
call_component_interface(cur_lambda);
}
基于事件分发的逻辑驱动
前述的虚接口主要用来处理每个组件都需要处理的主框架逻辑,例如进出场景、迁入迁出等重要逻辑流程,当这些逻辑流程被触发时actor_entity就可以用call_component_interface来通知所有的component。但是有些逻辑可能只有少数几个组件会关心,如果这些逻辑也通过上述的组件接口去实现的话,消息通知的效率将会大打折扣。以角色等级提升后的逻辑处理为例,假设我们在actor_component上定义了一个on_player_levelup的虚接口,则所有的actor_component都会带上这个虚函数,即使大部分actor_component里这个虚函数的实现就是一个简单的return。每添加一个类似的on_player_xxx都会引发整个项目的大规模重编译,在项目庞大之后比较影响迭代效率。在call_component_interface的执行循环中,对于每个component都会执行这个on_player_levelup虚函数调用,而虚函数调用相对于普通函数调用来说是一个比较费时的操作,特别是当函数体基本为空时这种效率损耗更加明显。因此无脑的添加虚接口是不可取的,对于这种少量component才关心的逻辑,需要一个更加精确的定向通知接口,也就是常说的事件分发器dispatcher。
简单来说,dispatcher内部有一个vector<function<void(const K&)>>的数据成员,这里的K是事件携带的参数信息,而function<void(const K&)>则是一个注册过来的事件监听回调,这里用vector来存储所有对此事件感兴趣的回调函数列表。在这样的结构辅助下,一个事件K发生时,只需要查找vector中存储的对应回调函数列表并一一执行即可。不过实际使用时为了处理回调函数的增减,vector内存储的并不是function而是shared_ptr<function>:
template <typename... args>
class typed_dispatcher
{
private:
std::vector<std::shared_ptr<std::function<void(args...)>>> callbacks;
public:
bool dispatch(args... data)
{
if (dispatch_depth >= max_dispatch_depth)
{
return false;
}
dispatch_depth++;
for (std::uint32_t i = 1; i < callbacks.size(); i++)
{
auto& cur_callback = callbacks[i];
if (cur_callback)
{
cur_callback->operator()(data...);
}
}
dispatch_depth--;
return true;
}
};
这里从1开始遍历是因为0被当作一个非法的handler。在dispatch事件的时候有一个需要注意的点,由于外部注册过来的回调函数里可能会再次触发这个dispatcher的事件分发,从而导致递归,所以我们这里记录了一下当前递归深度,如果深度大于指定值就不再处理。
注册回调的时候,为了方便使用,我们支持了一下三种回调类型:function对象,函数指针,以及成员函数指针:
typed_listen_handler<args...> add_listener(std::function<void(args...)> cur_callback)
{
typed_listen_handler<args...> result(std::uint32_t(callbacks.size()));
callbacks.push_back(std::make_shared< std::function<void(args...)>>(cur_callback));
return result;
}
typed_listen_handler<args...> add_listener(void(*cur_callback)(args...))
{
typed_listen_handler<args...> result(std::uint32_t(callbacks.size()));
callbacks.push_back(std::make_shared< std::function<void(args...)>>(cur_callback));
return result;
}
template <typename K>
typed_listen_handler<args...> add_listener( void(K::* cur_callback)(args...), K* self)
{
auto temp_lambda = [=](args... data)
{
return (self->*cur_callback)(data...);
};
typed_listen_handler<args...> result(std::uint32_t(callbacks.size()));
callbacks.push_back(std::make_shared< std::function<void(args...)>>(temp_lambda));
return result;
}
这里的typed_listen_handler是一个类型安全的int封装,保证内部存储的idx不会被typed_dispatcher<args...>修改,避免了直接使用int带来的数据混用问题:
template <typename... args>
class typed_listen_handler
{
std::uint32_t callback_idx;
friend class typed_dispatcher<args...>;
public:
typed_listen_handler()
: callback_idx(0)
{
}
typed_listen_handler(std::uint32_t in_callback_id)
:callback_idx(in_callback_id)
{
}
bool valid() const
{
return !!callback_idx;
}
void reset()
{
callback_idx = 0;
}
};
取消某个事件回调的时候,需要传入之前add_listener返回的handler:
bool remove_listener(typed_listen_handler<args...>& handler)
{
if (handler.callback_idx >= callbacks.size())
{
return false;
}
auto result = !!(callbacks[handler.callback_idx]);
callbacks[handler.callback_idx].reset();
handler.reset();
return result;
}
由于逻辑层可能在回调的过程中执行当前事件的监听,如果取消监听的同时修改了回调数组的大小,则可能会导致dispatch的for循环内产生迭代器失效,引发crash。所以这里取消监听只是设置对应元素为空,同时保留数组大小
上面描述的是一个极其简单的dispatcher实现,直接在游戏的业务逻辑内使用这样的事件分发并不适合。因为游戏业务逻辑里会有很多类型的事件分发,每个事件都有其不同的参数个数与类型,如果给每个事件都创建一个单独的dispatcher的话,dispatcher的数量会膨胀的非常厉害。而且游戏业务逻辑的事件是在不断增加的,每添加一种事件都创建一个专用的dispatcher会引发头文件的频繁修改。所以在游戏逻辑中,entity上除了一些重要逻辑使用的专用dispatcher之外,还有一个中心化的dispatcher来支持各种类型的事件分发。我们在mosaic_game中使用了模板来聚合:
template <typename... args>
class dispatcher
{
private:
std::tuple<dispatcher_impl<args>...> dispatcher_impls;
private:
template <typename K>
dispatcher_impl<K>& dispatcher_for()
{
static_assert(std::disjunction_v<std::is_same<K, args>...>, "invalid dispatch type");
return std::get<dispatcher_impl<K>>(dispatcher_impls);
}
}
这里的K其实并不是事件的参数类型,而是事件的标识符类型,只要这个K支持std::hash就可以作为事件的标识符类型,由于标识符类型可能有多种,所以这里使用变参模板来支持。
对于某个具体的标识符类型,会有一个对应的dispatcher_impl<K>,这个dispatcher_impl负责根据标识符的值进行第二次分发:
template <typename K>
class dispatcher_impl
{
private:
struct event_desc
{
std::uint32_t event_id;
std::uint32_t dispatch_depth = 0; // to stop recursive dispatch
std::map<std::uint32_t, std::vector<std::uint32_t>> data_callbacks; // data type_id to callbacks
};
std::unordered_map<K, std::uint32_t> event_idxes;
std::vector<event_desc> event_descs;
std::vector< std::shared_ptr<std::function<void(const K&, const event_data_wrapper&)>>> handler_to_callbacks;
};
这里的event_desc就是针对一个具体的K值存储的事件分发辅助结构,其内部的data_callbacks成员变量存储了不同的参数类型对应的回调函数索引列表。这个map里的key值是通过模板生成的类型id:
template <typename... args>
class dispatcher
{
static std::uint32_t last_type_id;
template <class K>
static std::uint32_t get_type_id()
{
static const std::uint32_t id = ++last_type_id;
return id;
}
};
template <typename... args>
std::uint32_t dispatcher<args...>::last_type_id = 0;
而这个map里的value里存储的每一个索引都指向handler_to_callbacks这个数组中的元素。为了将不同类型的回调函数统一存储在这个handler_to_callbacks数组中,这里使用event_data_wrapper来做类型擦除:
class event_data_wrapper
{
public:
template <typename K>
event_data_wrapper(const K& data, std::uint32_t data_type_id)
: data_type(data_type_id)
, data_ptr(&data)
{
}
const std::uint32_t data_type;
const void* data_ptr;
};
template <typename K, typename V>
listen_handler<K> dispatcher::add_listener(const K& event, void(*cur_callback)(const K&, const V&))
{
std::function<void(const K&, const V&)> temp_func(cur_callback);
return dispatcher_for<K>().add_listener(event, temp_func, get_type_id<V>());
}
template <typename V>
listen_handler<K> dispatcher_impl::add_listener(const K& event, std::function<void(const K&, const V&)> cur_callback, std::uint32_t cur_data_type_idx)
{
auto cur_callback_idx = get_next_callback_idx();
auto temp_lambda = [=](const K& event, const event_data_wrapper& data)
{
if (data.data_type != cur_data_type_idx)
{
return;
}
return cur_callback(event, *reinterpret_cast<const V*>(data.data_ptr));
};
handler_to_callbacks[cur_callback_idx] = std::make_shared< std::function<void(const K&, const event_data_wrapper&)>>(temp_lambda);
auto cur_event_id = get_event_idx(event);
event_descs[cur_event_id].data_callbacks[cur_data_type_idx].push_back(cur_callback_idx);
return listen_handler<K>{ cur_event_id, cur_data_type_idx, cur_callback_idx};
}
注册listener的时候,会创建一个临时的lambda来接受类型擦除之后的参数,执行强制类型转换来还原出原始的参数类型,然后再调用原始的listener来接收这个参数。
bool invoke_callback(std::uint32_t callback_idx, const K& event, const event_data_wrapper& event_data)
{
if (callback_idx == 0 || callback_idx >= handler_to_callbacks.size())
{
return false;
}
auto callback_copy = handler_to_callbacks[callback_idx];
if (!callback_copy)
{
return false;
}
callback_copy->operator()(event, event_data);
return true;
}
对外提供了一个模板化的dispatch接口,使用event的值找到对应的event_desc,然后再通过V的类型id找到对应的data_callbacks,然后遍历这个data_callbacks来执行回调:
template <typename V>
bool dispatch(const K& event, const V& data, std::uint32_t cur_data_type_id)
{
auto cur_event_desc_iter = event_idxes.find(event);
if (cur_event_desc_iter == event_idxes.end())
{
// this event is not registered
return false;
}
auto& cur_event_desc = event_descs[cur_event_desc_iter->second];
auto& cur_event_callbacks = cur_event_desc.data_callbacks;
auto cur_event_callback_iter = cur_event_callbacks.find(cur_data_type_id);
if (cur_event_callback_iter == cur_event_callbacks.end())
{
return false;
}
if (cur_event_desc.dispatch_depth >= max_dispatch_depth)
{
return false;
}
cur_event_desc.dispatch_depth++;
std::vector<std::uint32_t>& cur_callbacks = cur_event_callback_iter->second;
auto cur_data_wrapper = event_data_wrapper(data, cur_data_type_id);
for (std::size_t i = 0; i < cur_callbacks.size();)
{
if (invoke_callback(cur_callbacks[i], event, cur_data_wrapper))
{
i++;
continue;
}
if (i + 1 != cur_callbacks.size())
{
std::swap(cur_callbacks[i], cur_callbacks.back());
}
recycle_callback_idxes.push_back(cur_callbacks.back());
cur_callbacks.pop_back();
}
cur_event_desc.dispatch_depth--;
return true;
}
由于在dispatch的过程中使用了std::vector<std::uint32_t>&来引用回调函数数组列表,所以我们需要保证在这个dispatch的过程中cur_event_callback_iter需要维持有效,满足这个条件的容器只有map,所以data_callbacks的类型采用了map而不是unordered_map,因为unordered_map在扩容的时候会引发迭代器失效。就这样以三层中转加类型擦除的方式实现了一个中心化的dispatcher,可以支持任意的参数类型,使用起来非常灵活:
dispatcher<int, std::string> cur_dispatcher;
auto handler_1 = cur_dispatcher.add_listener(1, &callback_1);
auto handler_2 = cur_dispatcher.add_listener<int, string>(2, &callback_2);
auto handler_3 = cur_dispatcher.add_listener(std::string("hehe"), &callback_3);
auto handler_4 = cur_dispatcher.add_listener<string, string>(std::string("1"), &callback_4);
auto handler_5 = cur_dispatcher.add_listener(std::string("1"), &temp_a::callback_5, &a);
cur_dispatcher.dispatch(1, 2);
cur_dispatcher.dispatch(2, string("hehe"));
cur_dispatcher.dispatch(std::string("1"), string("hehe"));
cur_dispatcher.dispatch(std::string("hehe"), string("hehe"));
目前这个dispatcher也有其限制,为了支持中心化事件分发,导致事件的参数最多只能有一个。不过这个单参数的限制可以绕过去,也就是说如果事件本来带有多个参数,使用者需要创造一个新的类型来包裹这多个参数,这样就绕过了单参限制的问题。其实这个新类型可以通过变参模板创建std::tuple<Args...>来搞定,但是变参模板的代码实在是不好看懂,因此这里就不添加自动中间类型生成相关代码了。
大部分的业务系统在使用dispatcher分发事件时,使用的事件标识符类型基本都是字符串,由于业务逻辑散落各地组织分散,所以可能出现没有预想过的事件标识符相同引发的错误分发。为了规避事件标识符冲突的问题,在mosaic_game中设计了一种类型强约束的通用事件标识符类型enum_type_value_pair,这个标识符类型支持以枚举的形式来初始化,内部提供两个字段分别来存储枚举类的类型id以及枚举值:
struct enum_type_value_pair
{
std::uint32_t enum_type;
std::uint32_t enum_value;
template <typename T>
enum_type_value_pair(T v)
{
static_assert(std::is_enum_v<T>, "shoud be a enum value");
enum_type = type_hash::hash<T>();
enum_value = std::uint32_t(v);
}
friend bool operator==(const enum_type_value_pair& a, const enum_type_value_pair& b)
{
return a.enum_type == b.enum_type && a.enum_value == b.enum_value;
}
friend bool operator!=(const enum_type_value_pair& a, const enum_type_value_pair& b)
{
return a.enum_type != b.enum_type || a.enum_value != b.enum_value;
}
};
template <>
struct std::hash<spiritsaway::utility::enum_type_value_pair>
{
std::size_t operator()(const spiritsaway::utility::enum_type_value_pair a) const
{
std::uint64_t v = (std::uint64_t(a.enum_type)<<32) + a.enum_value;
return std::hash<std::uint64_t>{}(v);
}
};
在这个enum_type_value_pair类型之上,构造了一个enum_dispatcher,接口层会自动将传入的枚举值转换为enum_type_value_pair,然后再调用之前提到的dispatcher_impl来做事件分发:
class enum_dispatcher
{
private:
dispatcher_impl<enum_type_value_pair> m_dispatcher_impl;
public:
enum_dispatcher()
{
}
template <typename K, typename V>
listen_handler<enum_type_value_pair> add_listener(const K& event, std::function<void(const enum_type_value_pair&, const V&)> cur_callback)
{
return m_dispatcher_impl.add_listener(enum_type_value_pair(event), cur_callback, type_hash::hash<V>());
}
// 省略其他几种形式的listener注册
bool remove_listener(listen_handler<enum_type_value_pair>& handler)
{
auto result = m_dispatcher_impl.remove_listener(handler);
handler.reset();
return result;
}
template <typename K, typename V>
std::size_t dispatch(const K& event, const V& data)
{
return m_dispatcher_impl.dispatch(enum_type_value_pair(event), data, type_hash::hash<V>());
}
};
在actor_entity上我们提供了多种dispatcher,业务逻辑自由选择使用哪一种,这样在迭代过程中可以避免频繁修改actor_entity:
// 事件类型为string的dispatcher 自由度最大化
utility::dispatcher<std::string> m_misc_dispatcher;
// 属性变化通知dispatcher
utility::dispatcher<spiritsaway::property::property_replay_offset> m_prop_dispatcher;
// 对接场景事件分发的dispatcher
utility::dispatcher<std::string> m_space_dispatcher;
// 基于枚举类型的dispatcher
utility::enum_dispatcher m_dispatcher;
// 通知迁移完成的专用dispatcher
utility::typed_dispatcher<void> m_migrate_in_finish_dispatcher;
这里的m_space_dispatcher需要额外介绍一下,其作用是对接到场景内的广播事件。如果场景需要分发一个消息事件给所有actor_entity,需要执行场景内actor_entity的全遍历,然后在这些actor_entity上调用dispatcher.dispatch,这是一个耗时比较大的操作。如果真正在意这个事件的actor_entity数量比较少,就会产生严重的性能浪费。所以这里我们引入一个中间层m_space_dispatcher,只有真正关心一个事件的时候才会将当前actor挂载到space里这个event的通知集合之中:
void actor_entity::on_space_self_event(const std::string& event_id, std::uint64_t event_seq, const json& event_detail)
{
if(get_space()->is_cell_space() && event_seq <= m_space_self_event_seq)
{
return;
}
m_space_self_event_seq = event_seq;
m_space_dispatcher.dispatch(event_id, event_detail);
}
utility::listen_handler<std::string> actor_entity::space_event_listener_add(const std::string& event_id, std::function<void(const std::string&, const json&)> cb)
{
auto cur_listener = m_space_dispatcher.add_listener(event_id, cb);
if(m_space_dispatcher.get_listener_count<std::string, json>(event_id) == 1)
{
get_space()->add_actor_listener(event_id, this);
}
return cur_listener;
}
void actor_entity::space_event_listener_remove(const std::string& cur_event, utility::listen_handler<std::string> cur_handler)
{
m_space_dispatcher.remove_listener(cur_handler);
if(m_space_dispatcher.get_listener_count<std::string, json>(cur_event) == 0)
{
get_space()->remove_actor_listener(cur_event, this);
}
}
在space_entity中使用一个map<string, vector<actor_entity*>>来event的通知集合,这里使用map而不是unordered_map也是为了避免dispatch过程中添加新的事件监听引发的迭代器失效:
void space_entity::add_actor_listener(const std::string& event_id, actor_entity* cur_actor)
{
auto& cur_event_listeners = m_event_listen_actors[event_id];
auto temp_iter = std::find(cur_event_listeners.begin(), cur_event_listeners.end(), cur_actor);
if(temp_iter != cur_event_listeners.end())
{
return;
}
cur_event_listeners.push_back(cur_actor);
}
void space_entity::remove_actor_listener(const std::string& event_id, actor_entity* cur_actor)
{
auto& cur_event_listeners = m_event_listen_actors[event_id];
auto temp_iter = std::find(cur_event_listeners.begin(), cur_event_listeners.end(), cur_actor);
if(temp_iter != cur_event_listeners.end())
{
*temp_iter = nullptr;
}
}
执行事件分发的时候,遇到为nullptr的元素就直接跳过,并累加一个m_temp_invalid_listener_count计数器,同时开启一个60s一次的timer来定期清除为nullptr的元素:
void space_entity::clear_invalid_actor_listeners()
{
if(m_temp_invalid_listener_count > 1000)
{
for(auto& one_pair: m_event_listen_actors)
{
auto& cur_listener_vec = one_pair.second;
cur_listener_vec.erase(std::remove(cur_listener_vec.begin(), cur_listener_vec.end(), nullptr), cur_listener_vec.end());
}
m_temp_invalid_listener_count = 0;
}
add_timer_with_gap(std::chrono::seconds(m_clear_invalid_listener_gap_seconds), [this]()
{
clear_invalid_actor_listeners();
});
}
基于计时器的逻辑驱动
游戏内还有非常多的逻辑依赖于计时器来执行的,例如一些周期性的活动、定期检查的任务以及延迟生效的效果等,这些任务都可以抽象为一个需要在指定时间点执行的std::function<void()>。为了维护这些指定时间点的任务,最简单的数据结构就是一个存储了超时信息的数组:
struct timer_info
{
std::uint64_t timer_id = 0;
std::uint64_t expire_ts = 0;
std::function<void()> callback;
bool operator<(const timer_info& other) const
{
return expire_ts < other.expire_ts;
}
};
class timer_mgr
{
std::vector<expire_info> timers;
std::uint64_t last_timer_id = 0;
std::unordered_set<std::uint64_t> active_timers;
public:
// 创建一个在给定时间点超时的计时器 返回一个uint64 作为这个计时器的唯一id
std::uint64_t add_timer(std::uint64_t expire_ts, std::function<void()> callback);
// 取消一个计时器
bool cancel_timer(std::uint64_t timer_id);
// 执行一次计时器管理器的更新操作 触发所有超时计时器
void check_expire(std::uint64_t cur_ts);
};
每次新建一个计时器任务的时候,都构造一个新的timer_info放到这个timers数组的末尾,并将计时器的id放到active_timers这个集合中。取消一个计时器的时候,只需要从这个集合中删除这个id即可。添加和删除操作都可以认为是常数时间:
std::uint64_t timer_mgr::add_timer(std::uint64_t expire_ts, std::function<void()> callback)
{
if(!callback)
{
return 0;
}
auto new_timer_id = ++last_timer_id;
timers.push_back(timer_info{new_timer_id, expire_ts, callback});
active_timers.insert(new_timer_id);
return new_timer_id;
}
bool timer_mgr::cancel_timer(std::uint64_t timer_id)
{
return active_timers.erase(timer_id) == 1;
}
外部以一定的周期去检查这个数组里是否有过期的时间戳,如果有则执行关联的任务并从这个数组中删除:
void timer_mgr::check_expire(std::uint64_t cur_ts)
{
for(auto& one_timer: timers)
{
if(one_timer.expire_ts <= cur_ts)
{
if(active_timer.erase(one_timer.timer_id) == 1)
{
one_timer.callback();
cur_timer.callback = std::function<void()>{};
}
one_timer.expire_ts = 0;
}
}
timers.erase(std::remove_if(timers.begin(), timers.end(), [](const timer_info& one_timer)
{
return one_timer.expire_ts == 0;
}), timers.end());
}
当游戏业务逻辑开始累积之后,这些计时器就会变得越来越多,很快其数量就开始以百为单位。此时每次以数组全遍历的形式去检查计时器超时就变得非常低效,同时每次执行erase都会造成大量的数组元素移动,这部分的代价也很大。因此我们需要一个效率更高的结构来获取本次检查过程中超时的计时器,目前主流的实现方案分为了三种:
- 基于有序数组实现的计时器
- 基于优先队列实现的计时器
- 基于时间轮实现的计时器
基于有序数组实现的计时器理解起来非常简单,就是timers里的元素是按照expire_ts从小到大排列好的,这样检查超时的计时器代价就很小了,从头开始遍历处理直到遇到一个还没有超时的计时器就跳出循环:
void timer_mgr::check_expire(std::uint64_t cur_ts)
{
std::uint32_t i = 0;
for(; i< timers.size(); i++)
{
auto& cur_timer = timers[i];
if(cur_timer.expire_ts <= cur_ts)
{
if(cur_timer.expire_ts != 0)
{
if(active_timer.erase(cur_timer.timer_id) == 1)
{
cur_timer.callback();
cur_timer.callback = std::function<void()>{};
}
cur_timer.expire_ts = 0;
}
}
else
{
break;
}
}
if(i >= 20 && i > timers.size() * 0.25)
{
timers.erase(timers.begin(), timers.begin() + i);
}
}
在处理完所有超时的计时器之后,这里并没有像之前的实现一样立即删除所有的失效计时器,而是将这些计时器设置为默认值,继续维护数组的有序性。只有当失效计时器的数量大于一定阈值时才删除这些失效计时器,这样就可以避免每次执行check_expire时因为元素的删除导致的数组元素整体移动,平摊下来的数组移动代价就小了很多。
不过这样的最优复杂度也是有其代价的,新建一个计时器的时候无法像往常一样放在数组末尾,而是需要找到有序数组中的插入位置。在有序数组中查找插入位置其实就是插入排序,最坏复杂度为数组的长度,如果计时器的创建比较频繁的话这里的代价就无法接受了。
为了降低这个插入时的最坏线性时间复杂度,很多计时器的实现都使用了一个最小堆来管理timers数组。每次新建一个计时器的时候,创建的timer_info会先放在timers数组的末尾,然后调用std::push_heap就完成了最小堆结构,因此插入的复杂度为log(N)。然后在check_expire时,不断的使用pop_heap来弹出已经超时的计时器,每次操作的时间复杂度也是log(N)。
// 由于stl默认维持的是最大堆,所以要做最小堆的话需要传入一个自定义比较器
struct timer_info_inv_less
{
bool operator()(const timer_info& a, const timer_info& b) const
{
return a.expire_ts > b.expire_ts;
}
};
std::uint64_t timer_mgr::add_timer(std::uint64_t expire_ts, std::function<void()> callback)
{
if(!callback)
{
return 0;
}
auto new_timer_id = ++last_timer_id;
timers.push_back(timer_info{new_timer_id, expire_ts, callback});
active_timers.insert(new_timer_id);
std::push_heap(timers.begin(), timer.end(), timer_info_inv_less{});
return new_timer_id;
}
void timer_mgr::check_expire(std::uint64_t cur_ts)
{
std::uint32_t i = 0;
while(timers.size())
{
if(timers[0].expire_ts <= cur_ts)
{
auto& cur_timer = timers[0];
if(active_timer.erase(cur_timer.timer_id) == 1)
{
cur_timer.callback();
cur_timer.callback = std::function<void()>{};
}
cur_timer.expire_ts = 0;
std::pop_heap(timers.begin(), timers.end(), timer_info_inv_less{});
timers.pop_back();
}
else
{
break;
}
}
}
这里通过手动调用stl里堆相关接口来实现了一个非常简单的优先队列,更好的方式其实是直接使用std::priority_queue<timer_info>,来显示的表明优先队列的语义。
整体check_expire的时间复杂度为k*log(N), k为超时的计时器个数,最坏情况下会出现N*log(N),之前基于有序数组实现的check_expire复杂度只有K,算是一个非常大的劣化。考虑到有序数组实现的定时器check_expire的复杂度是最优的,因此业界在有序数组实现的定时器基础上继续演进,开发出了时间轮(timer wheel)这样的定时器专用数据结构,这个数据结构由 George Varghese与Tony Lauck 在1987年的论文 Hashed and Hierarchical Timing Wheels: data structures to efficiently implement a timer facility中被提出。
首先我们来介绍一下最简单情况下时间轮是如何管理计时器的,此时需要限定添加的新计时器的超时时间与当前时间点的差值不能超过一个指定值。在这个超时限制下,时间轮内部使用一个由数组组成的循环队列,循环队列里的每个元素都是一个计时器的数组。这个循环队列组成一个类似于时钟表盘的圆环,队列里每个元素代表一个时间片[begin,end),每个时间片的时间长度都是相同的,同时使用一个数组来存储超时时间在这个时间片内的所有计时器。此外时间轮内部存储一个索引指向上一次处理的时间片,以及上一次处理的时间。
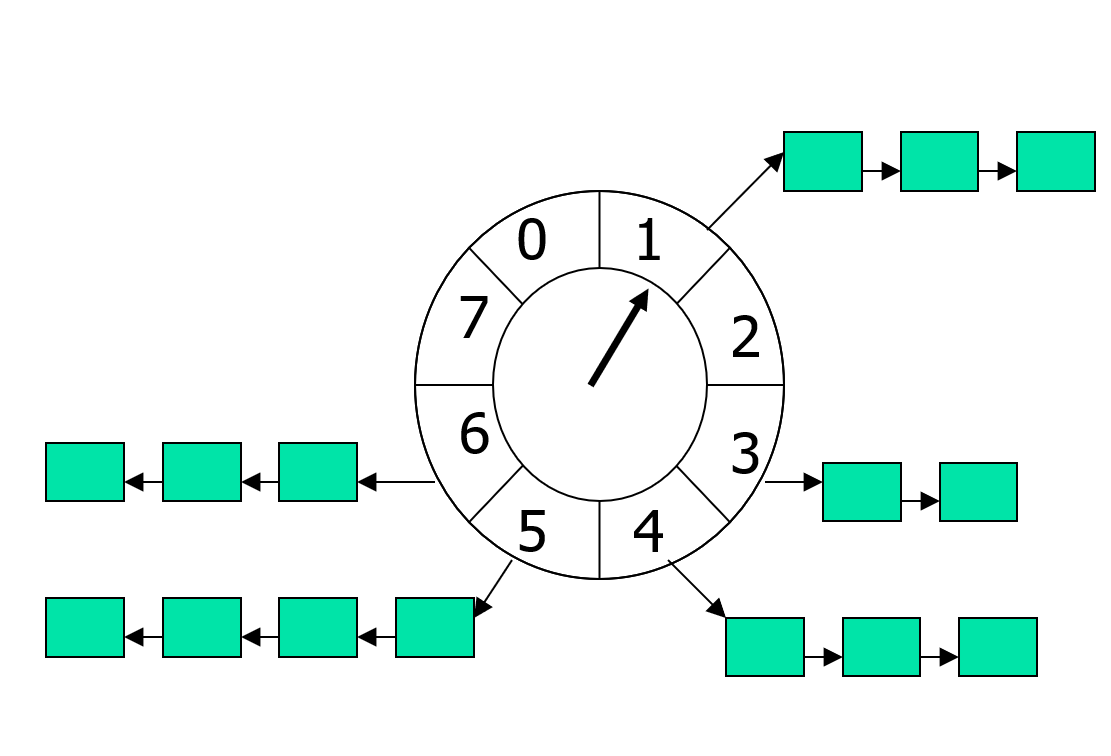
在了解这些基础设定之后,下面就是添加一个计时器的代码,非常简单,复杂度平摊下来就是O(1):
class wheel_timer_mgr
{
std::uint64_t last_timer_id = 0;
std::unordered_set<std::uint64_t> active_timers;
const std::uint32_t timer_slice_range;// 每个时间片的大小
const std::uint32_t timer_circular_num; // 循环队列里时间片的个数
const std::uint64_t base_ts;// 创建时的时间戳
std::uint64_t last_timer_slice_index = 0;// 上次处理的时间片索引
std::vector<std::vector<timer_info>> timer_slices; // 循环队列
public:
wheel_timer_mgr(std::uint32_t slice_range, std::uint32_t circular_num, std::uint64_t in_ts)
: timer_slice_range(slice_range)
, timer_circular_num(circular_num)
, base_ts(in_ts - timer_slice_range)
, timer_slices(circular_num)
{
}
// base_ts初始化的时候减去一个timer_slice_range 保证这里算出来的最小值是1
std::uint64_t calc_timer_slice_index(std::uint64_t cur_ts) const
{
return (cur_ts - base_ts) / timer_slice_range;
}
std::uint64_t add_timer(std::uint64_t expire_ts, std::function<void()> callback)
{
if(!callback)
{
return 0;
}
auto new_timer_id = ++last_timer_id;
assert(expire_ts >= base_ts + (last_timer_slice_index + 1) * timer_slice_range); // 要求过期时间要大于上次时间片的过期时间
auto cur_timer_slice_index = calc_timer_slice_index(expire_ts);
// 要求最大超时间隔不能超过总时间片
assert(cur_timer_slice_index - last_timer_slice_index < timer_circular_num);
timer_slices[cur_timer_slice_index % timer_circular_num].push_back(timer_info{new_timer_id, expire_ts, callback});
active_timers.insert(new_timer_id);
return new_timer_id;
}
};
时间轮的判定计时器超时的代码也很简单,每个时间片里所有的计时器统一过期:
void wheel_timer_mgr::check_expire(std::uint64_t cur_ts)
{
auto cur_timer_slice_index = calc_timer_slice_index(cur_ts);
while((last_timer_slice_index + 1)!= cur_timer_slice_index)
{
last_timer_slice_index++;
for(auto& one_timer: timer_slices[last_timer_slice_index % timer_circular_num])
{
if(active_timer.erase(one_timer.timer_id) == 1)
{
one_timer.callback();
one_timer.callback = std::function<void()>{};
}
}
timer_slices[last_timer_slice_index % timer_circular_num].clear();
}
}
统一过期的好处就是算法复杂度超级简单,平摊下来每个超时的计时器其处理代价就是O(1)。但是这样粗暴的处理也有其缺点,同一个timer_slice里的计时器并没有依照其超时时间从小到大来触发回调。这样可能导致逻辑层有些有先后关系的计时器并没有按照预想的顺序进行回调,从而引发顺序相关的逻辑错误。面对这个问题的解决方法就是在插入新计时器的时候,保持每个timer_slice都是一个以expire_ts从小到大排列的有序数组。在循环队列的容量比较大且时间片的大小比较小的情况下,我们可以比较安全的假设同一个时间片里的计时器数量不会很多,因此这个保持有序的额外代价不会很明显。
前面介绍的最简情况下的时间轮实现有一个非常强的预设条件,即新添加的计时器的过期时间与上一次时间片的过期时间的差值不能超过指定的常量timer_circular_num * timer_slice_range。但是在实际的业务系统中一个长周期的计时器总是无法避免的,所以为了放松这个最大超时时间的限制,在上述的时间轮定义的timer_info里再添加一个字段代表其过期的批次round, 每次一个时间片被调度到的时候只会将与当前批次的计时器执行过期操作,大于当前批次的计时器会保留在这个时间片中:
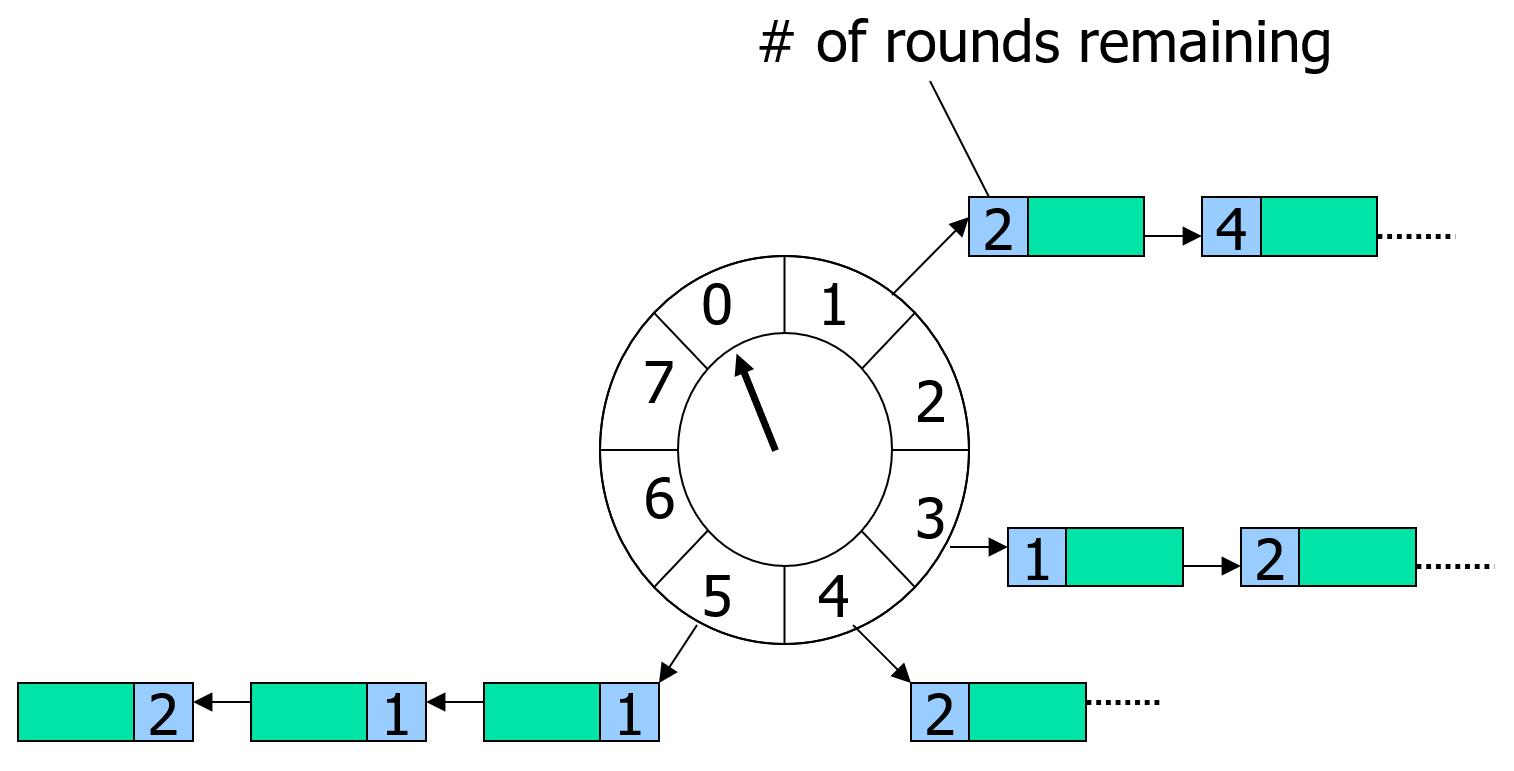
其实这个round字段也不需要添加,可以直接使用内部存储的过期时间计算出来:
std::uint64_t wheel_timer_mgr::calc_expire_ts_round(std::uint64_t expire_ts) const
{
return calc_timer_slice_index(expire_ts) / timer_circular_num;
}
整体来说放松了最大超时时间的限制之后,原始的时间轮管理器的改动代码也没几行,整体复杂度与时间片内保持有序的时间轮一样。
一般来说,将循环数组的大小设置的比较大,例如说1024,同时将时间片精度设置的比较小,如5ms,就可以让整体的计时器基本平均分布在所有的时间片之中。在这个均匀分布的情况下,可以显著的降低维持有序插入时的最坏复杂度O(N)。不过对于有些包含巨量计时器的软件系统而言,这样的平摊后的复杂度还是有点高,典型例子就是linux的内核以及apache-kafka。在这些拥有巨量计时器的软件中,采取了层次化时间轮的结构来管理计时器。
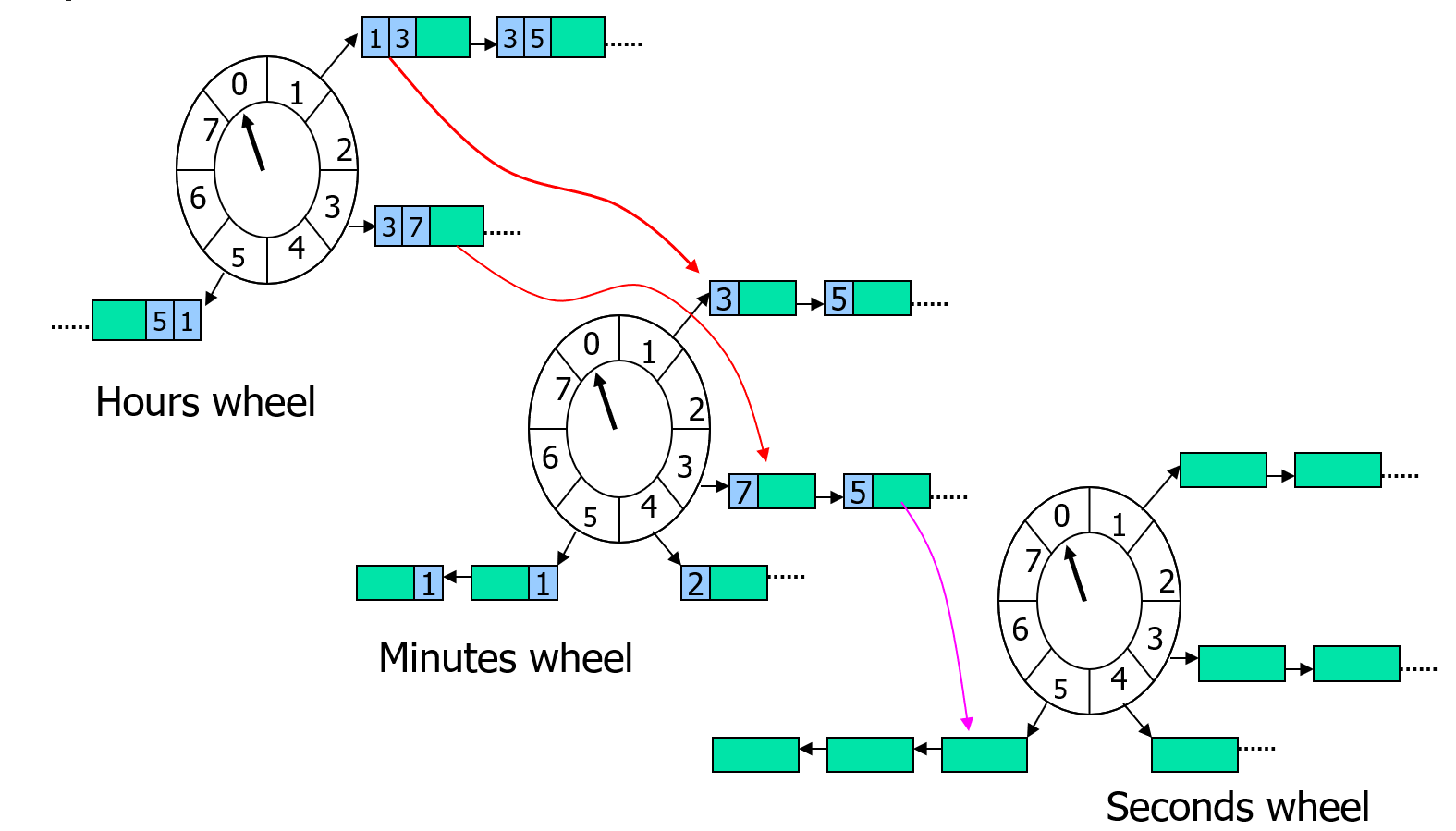
上图就是层次化时间轮的示意图,这里有三种不同精度的时间轮,分别是小时、分钟、秒钟,对应的循环队列的大小分别是24、60、60。秒钟时间轮里存储的是当前分钟对应的所有计时器,分钟时间轮里存储的是当前小时里的所有计时器,小时时间轮里存的是所有计时器。当添加一个新的计时器的时候,首先会使用calc_timer_slice_index计算其在小时时间轮的索引cur_timer_slice_index:
- 如果索引值与小时时间轮里记录的
last_timer_slice_index不一样,则直接插入到这个cur_timer_slice_index对应的时间片之中 - 如果索引值与小时时间轮里记录的
last_timer_slice_index一样,则将这个插入请求传递到下一级的时间轮中,
在分钟时间轮里的计时器插入流程与小时时间轮里一样,可能根据情况继续传递到秒钟时间轮里。到了秒钟时间轮之后,由于其没有下一级的时间轮,因此根据计算的索引直接进行插入即可。
当执行计时器过期操作的时候,操作的是秒钟时间轮,当秒钟时间轮的时间片索引走完一整圈60之后,需要更新上一级的分钟时间轮的时间片索引,并将分钟时间轮当前时间片里的计时器全都转移到秒钟时间轮中执行插入。如果此时分钟实践论的时间片索引也刚好走完一圈60,那么需要先更新小时时间轮的时间片索引,并把这个小时里所有计时器转移到分钟时间轮中执行插入,然后再执行计时器从分钟时间轮转移到秒钟时间轮的流程。
在这样的设计下,分钟时间轮和小时时间轮里每个时间片里存储的计时器并不要求保持有序,因为这些数据只有在秒钟时间轮走完一圈的时候才有机会去访问。此时直接遍历一次筛选出符合要求的计时器即可,这些操作被触发的概率很小,平摊下来就是常数复杂度。
上面的样例里使用的是时分秒的三级时间轮结构,总体的时间片大小就是60+60+24=144, 这样的时间片数量对于内存的压力是比较小的。 实际使用中可以继续添加天数时间轮和毫秒时间轮,甚至我们可以不按照自然时间精度来进行层次划分,而采用每一级精度都是上一级的256倍来划分,逻辑上也是等价的,整体的时间复杂度与空间复杂度都不会发生明显变化。
游戏逻辑里经常会遇到定期触发的相关逻辑,如每周五晚上八点的节日活动开启、每天零点刷新的排行榜、特殊区域的持续性扣血等。这种可重复的计时任务可以以单次计时器的形式模拟出来,即在计时器的callback中重新执行一次指定间隔的计时器添加操作。如果这种可重复计时器有很多的情况下,这种重复添加的模式就会比较影响效率。因此绝大部分的计时器管理器都会提供一个add_repeated_timer(float delay, float gap, std::function<void()> callback)这样的接口,此时对应的timer_info里添加一个bool标记这个计时器是一个重复计时器,在执行计时器回调的时候修改其超时时间然后重新执行一次后续的管理操作即可。
基于异步回调的逻辑驱动
entity内有些逻辑需要涉及到与外部entity以及其他系统的通信,在发出的请求得到应答之后再继续之前的逻辑执行后续处理,这样的逻辑模式可以简化为下面的代码:
void func_a()
{
json request;
// 发送数据请求
send_request(request);
// 通过某种方式等待另外一端返回数据
wait_for_response();
// 获取返回的结果
json response = fetch_response();
handle_respose(response);
}
如果我们在wait_for_response里使用同步的方式来等待返回值,则当前线程的运行将会被这个等待函数阻碍。如果每次执行func_a的时候都创建一个线程的话系统资源消耗的就过大,所以实际的系统中都会以异步的形式来等待请求的完成,原来的单个函数被拆为多个函数:
void func_a_send()
{
json request;
// 发送数据请求
send_request(request);
}
void func_a_recv()
{
// 获取返回的结果
json response = fetch_response();
handle_respose(response);
}
在这个模式下,先执行func_a_send将请求发送到外部,完成之后系统继续执行其他任务。当系统接收到外部发送回来的数据时,再执行func_a_recv来获取返回数据并执行后续的流程。这里只是阐述了一个最简流程,一次发送对应一次接收,实际运用中的系统其实远比这个复杂,最主要的差异在于:接受返回值的后续处理很可能需要知道发送请求的上下文。 这个问题比较好解决,直接让外部系统将请求request和返回值一起打包发送回来就好了。
void func_a_recv()
{
auto [request, response] = fetch_response();
handle_response(request, response);
}
不过这样的设计会导致通信流量的明显增加,而且也并没有完全解决恢复请求上下文的问题。因为我们的请求上下文并不仅限于发送的数据request,可能还会出现一些不可序列化的其他对象,例如一些裸指针、智能指针等等。这些对象的引用有些时候可以以标识符的形式转换为可序列化的数据,每次接收response的时候再手动的根据这些标识符重新构造出这些对象。但是随着上下文内对象的增多,这种对象转化为标识符然后再从标识符转化为对象的代码就变得很冗长,我们需要一个自动的方式来打包所有要用到的请求上下文对象。此时lambda函数就非常满足需求,在使用lambda的情况,流程代码可以简化为下面的样子:
void func_a_send()
{
entity* other;// 上下文里会使用到的对象
json request;
auto callback_id = add_callback([=](const json& response)
{
handle_response(request, response, other);
});
send_request(request, callback_id);
}
void invoke_callback(const json& response, std::uint64_t callback_id)
{
std::function<void(const json&)> request_callback = fetch_callback(callback_id);
if(request_callback)
{
request_callback(response);
}
}
这里依赖了一个add_callback函数来注册一个回调上下文,返回一个uint64的回调id,随着请求数据一起发送出去。当请求得到响应时,对端会同时下发响应数据以及回调上下文的id。我们再通过fetch_callback接口来获取出注册的回调,然后再以这个返回数据来执行。
这个就是常规的异步回调的处理流程,但是在游戏中server_entity的异步回调又有一些不一样。因为server_entity会出现进程间迁移,server_entity在发送请求的时候在A进程上,但是数据下发的时候可能已经迁移到了B进程。虽然我们能够在send_request的时候带上server_entity的迁移不变地址proxy,在其他服务返回数据的时候通过这个迁移不变地址proxy发送到迁移后的新server_entity上。但是正确的处理这个返回数据还要求我们能将对应的回调也能迁移过来,对于这种需要支持迁移的回调,我们需要用一种可序列化的形式来对其进行封装:
struct json_callback_info
{
std::string cb_type;
std::uint64_t cb_id;
json cb_args;
NLOHMANN_DEFINE_TYPE_INTRUSIVE(json_callback_info, cb_type, cb_id, cb_args);
};
struct json_callback_result : public json_callback_info
{
json cb_result;
};
这里的cb_type就是回调函数的名字,cb_args是记录这个回调所需要的一些额外参数。同时callback_manager上还需要记录现在已经分配的最大回调计时器大小,这样就可以避免迁移后出现相同的计数器:
class json_callback_manager
{
public:
using callback_handler = handler_wrapper<std::uint64_t, json_callback_manager>;
protected:
std::uint64_t m_callback_counter = 0;
// use map in case iterator invalidate
std::map<std::uint64_t, json_callback_info> m_callbacks;
public:
NLOHMANN_DEFINE_TYPE_INTRUSIVE(json_callback_manager, m_callback_counter, m_callbacks);
};
server_entity在接收到返回值之后,利用rpc机制执行回调分发,此时返回值response拼接到原来存储的参数数组最后:
void server_entity::invoke_callback(utility::mixed_callback_manager::callback_handler callback_id, const json& result)
{
utility::json_callback_info cur_cb_info;
if (m_callback_mgr.invoke_callback(callback_id, result, cur_cb_info))
{
if(!cur_cb_info.cb_type.empty())
{
if(!cur_cb_info.cb_args.is_array())
{
m_logger->warn("fail to invoke_callback with callback_id {}, result {} cb_args not array", callback_id.value(), result.dump());
return;
}
utility::rpc_msg cur_msg;
cur_msg.cmd = cur_cb_info.cb_type;
cur_msg.args = cur_cb_info.cb_args.get<json::array_t>();
cur_msg.args.push_back(result);
if(on_rpc_msg(cur_msg) != utility::rpc_msg::call_result::suc)
{
m_logger->warn("fail to invoke_callback with callback_id {}, result {} rpc call fail cmd {} args {}", callback_id.value(), result.dump(), cur_msg.cmd, json(cur_msg.args).dump());
}
}
}
else
{
m_logger->warn("fail to invoke_callback with callback_id {}, result {}", callback_id.value(), result.dump());
}
}
实际上为了支持非迁移回调和迁移回调,我们在mosaic_game中提供的是一个聚合了的mix_callback_manager:
class mixed_callback_manager
{
public:
using json_func_cb = func_callback_manager::json_callback_t;
using json_cb_handler = json_callback_manager::callback_handler;
using func_cb_handler = func_callback_manager::callback_handler;
using json_cb_info = json_callback_info;
using callback_handler = handler_wrapper<std::uint64_t, mixed_callback_manager>;
protected:
json_callback_manager m_json_cb_mgr;
func_callback_manager m_func_cb_mgr;
public:
callback_handler add_callback(json_func_cb func_cb)
{
auto temp_handler = m_func_cb_mgr.add_callback(func_cb);
return callback_handler(temp_handler.value() * 2 );
}
callback_handler add_callback(const std::string& cb_type, const json& cb_args)
{
auto temp_handler = m_json_cb_mgr.add_callback(cb_type, cb_args);
return callback_handler(temp_handler.value() * 2 + 1);
}
};
这里同时提供了两个类型的添加回调接口,当添加的是非迁移回调的时候返回值会变成2*a+1,当添加的是迁移回调的时候返回值会变成2*a,这样的设计是为了更好的做回调触发时的区分:
bool is_json_cb_handler(callback_handler cb_handler) const
{
return cb_handler.value() % 2 == 1;
}
bool invoke_callback(callback_handler cb_handler, const json& result, json_callback_info& cb_info)
{
if(is_json_cb_handler(cb_handler))
{
// 此时并不执行回调 而是删除之前的cb 信息
json_cb_handler temp_handler = m_json_cb_mgr.construct_handler(cb_handler.value()/2);
return m_json_cb_mgr.invoke_callback(temp_handler, cb_info);
}
else
{
func_cb_handler temp_handler = m_func_cb_mgr.construct_handler(cb_handler.value() / 2);
return m_func_cb_mgr.invoke_callback(temp_handler, result);
}
}