角色属性公式计算
角色属性介绍
在游戏之中,我们操纵的角色和一些非玩家角色都会有相关的数值描述,例如血量、等级、攻击、防御等等。下面就是Dota2的一个角色的属性面板。
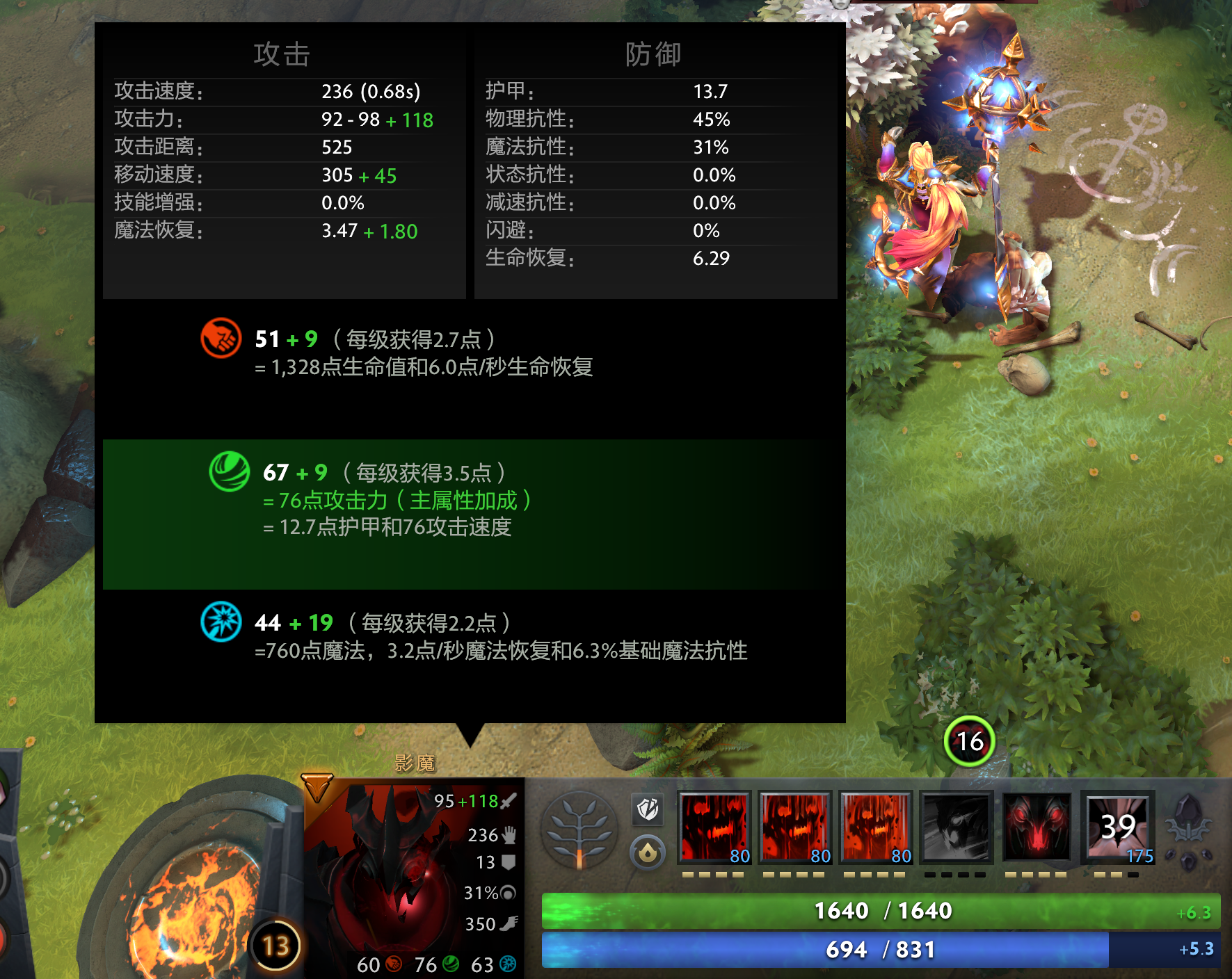
在这个界面上,我们可以看到很多游戏内非常常规的属性:等级、生命值、魔法值、生命恢复速度、魔法恢复速度、攻击力、护甲、移动速度、力量、敏捷、智力、攻击速度、攻击距离、运动速度、技能增强、物理抗性、魔法抗性、状态抗性、减速抗性、闪避。其中有些属性还相互关联:
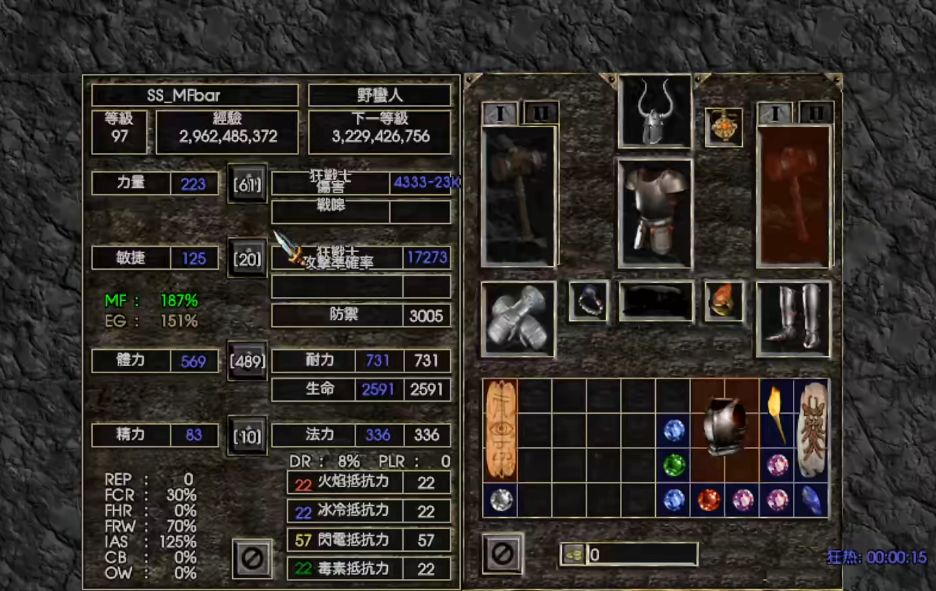
Dota2的角色属性系统还算是比较简单的,只有十几个属性字段,而暗黑破坏神2则有数十个属性字段,下面的面板其实只展示了其中的一部分:
一个角色的属性描述的几十个字段并不是毫无逻辑关系的,同时完整的属性关系之间可能还有其他的面板不可见属性作为中间变量存在。以Dota2中的护甲计算公式为例:
护甲 = 基础护甲 + 额外护甲 + 敏捷 / 3
这里的基础护甲是每个英雄的自带属性,并没有直接在属性面板上显示,额外护甲这个变量则是所有装备的护甲值累加计算出来的中间变量,也就是属性面板中护甲值的绿色部分,而敏捷这个变量其实也是由计算公式生成的
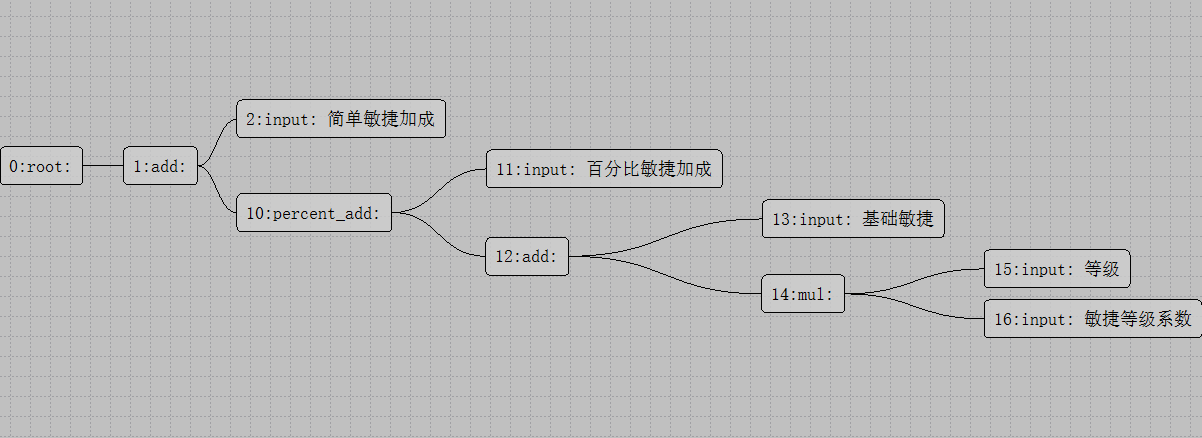
敏捷 = (基础敏捷 + 等级 * 敏捷成长) *(1 + 敏捷放大倍数) + 额外敏捷
这里可以看出,等级提升之后,敏捷会相应提升,并因此更新护甲。这就是最基础的一个护甲属性变化计算公式,非常的简洁明了。其实敏捷这个属性不仅参与了护甲的计算,还会参与攻速的计算。在Dota2中力量敏捷智力这三个属性其实影响了很多其他属性:
- 力量敏捷智力这三个数值会随着角色等级自动增长,这几个属性的每一级增长的数值在不同的英雄中也是不同的。
- 力量敏捷智力之中作为主属性的那个还会增加到攻击力,
- 力量的成长会带来生命值与生命恢复速度的变化,每一点力量对应
19点生命值,每十点力量对应一点生命恢复 - 敏捷的增长会带来攻击速度和护甲的变化,每一点敏捷对应一点攻击速度,每三点敏捷对应一点护甲
- 智力的增长会带来魔法值、魔法恢复速度和魔法抗性的变化,每一点智力对应
12点魔法值,每20点智力对应一点魔法恢复速度,每10点智力对应一点魔法抗性
角色的属性系统除了让面板变得更好看之外,最重要的作用是计算角色之间的伤害,一次攻击,附加伤害是多少,是否会暴击,准确率是多少,是否被会闪避。在Dota2游戏中,伤害计算公式还是比较简单的,只需要考虑两个属性,攻击力与护甲:
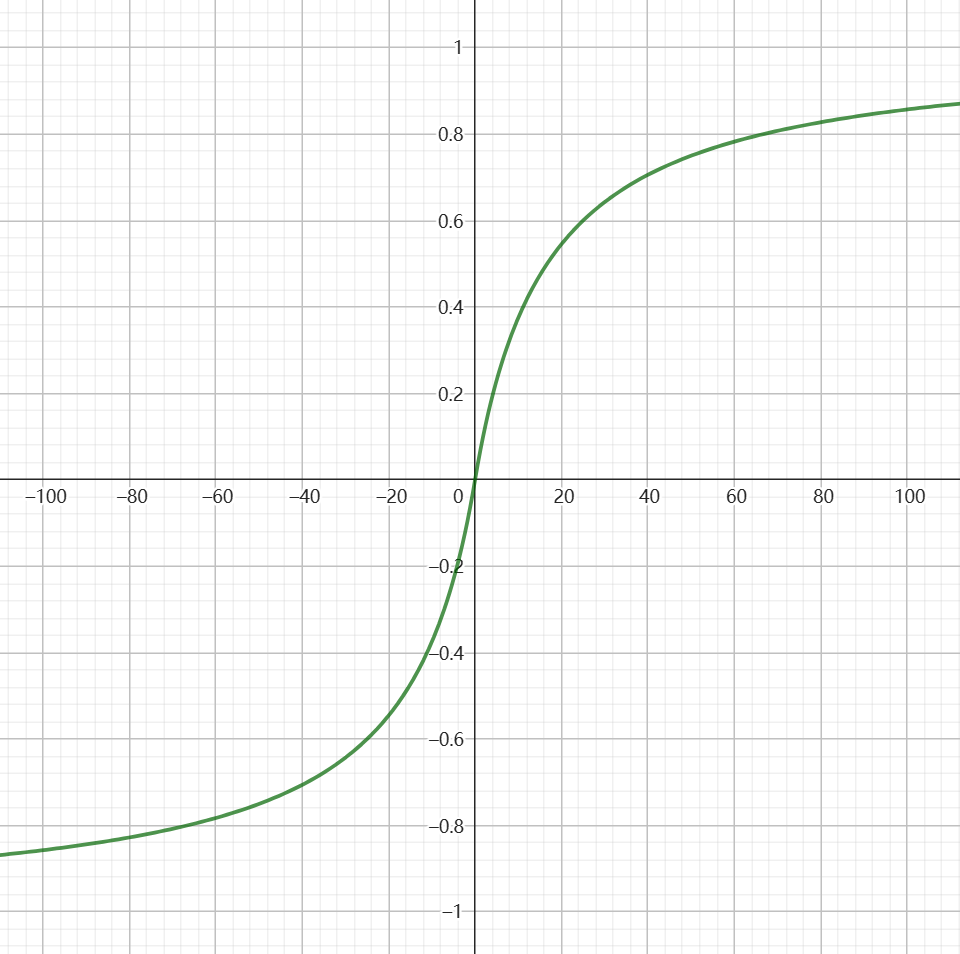
伤害=攻击力*(1-敌方物理抗性) 物理抗性= 护甲 * 0.06/(1+abs(护甲 * 0.06))
这里的物理抗性公式基本继承自魔兽争霸3,其目的就是为了控制物理抗性的取值范围在之内,其函数曲线如下:
遇到比较复杂的游戏,属性计算就会变得很复杂,例如下面的就是暗黑破坏神2中的伤害计算公式:
近战最终伤害=((基本伤害x1.5{无形物品})*(1+武器ed数值/100)+直接最小/最大伤害增加值)*(1+力量或敏捷/100+非武器ed数值/100+技能ed数值/100)*((1-技能伤害惩罚/100))*2(临界一击或者致命一击) + 元素伤害
这个伤害计算已经有点复杂了,但是这个伤害在结算的时候并不是立刻参与扣除攻击目标的血量,还需要经过多轮计算。首先需要处理的就是命中率,在暗黑破坏神2中的命中率公式如下:
实际命中率=自身命中率/(自身命中率+目标防御力)*(自身等级*2/(自身等级+对方等级))
而这里的防御力其实也是一个属性,根据各种参数计算而来:
防御力总值 =(人基本防御+装备防御+各种地方的直接额外防御)*(1+各种防御百分百加成)
计算出命中率之后,再经过一次随机数生成来判定当前能否击中,如果没有击中则本次攻击无效,如果击中则继续走后面的流程,包括粉碎性打击、伤害减免、物理抗性、元素抗性等。完整的一次从伤害计算到血量扣除其实会涉及到非常多的属性计算,下图就是网友总结的DNF中的伤害计算公式:
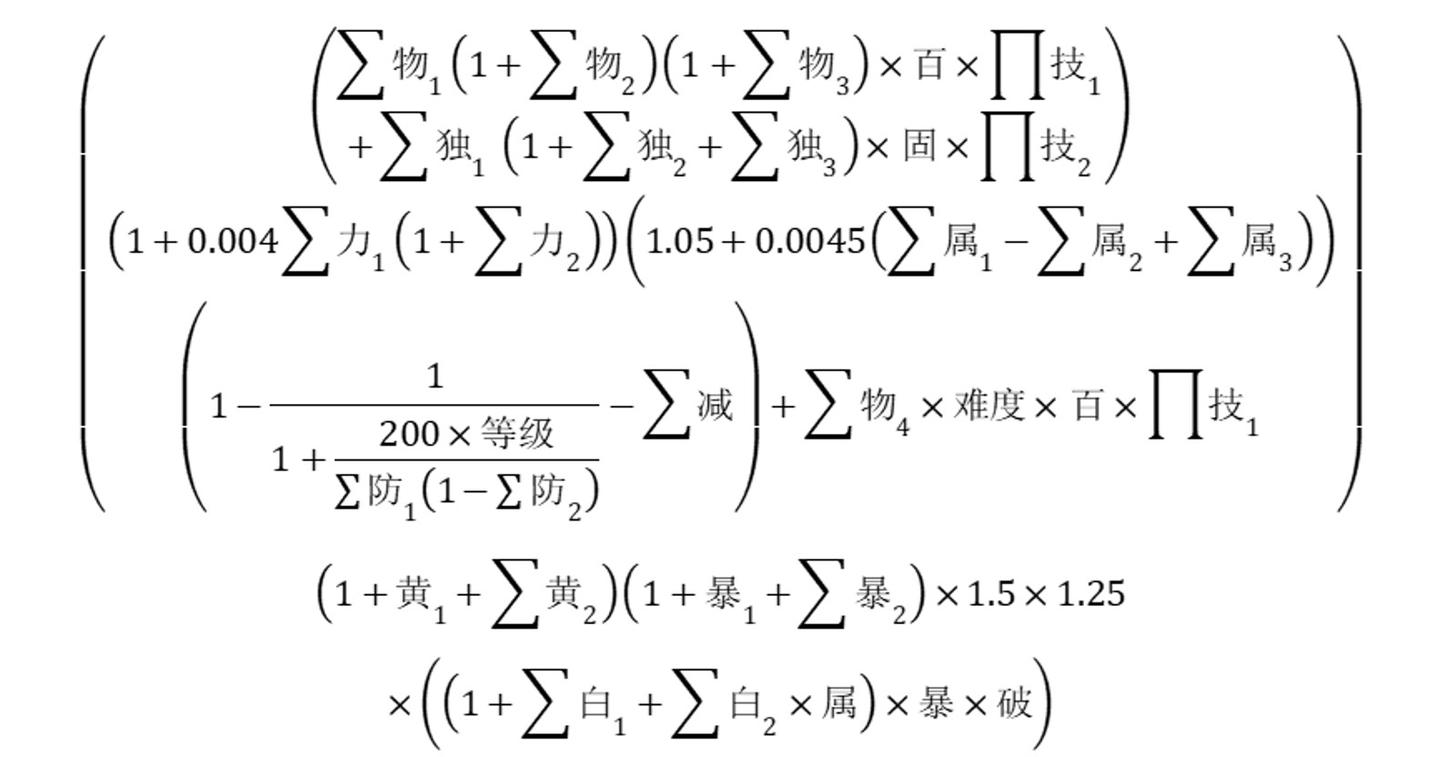
复杂度低的情况下程序可以在代码里硬编码这些计算属性计算公式:
double strength()
{
return base_strength + extra_str + level * str_per_level;
}
double dexterity()
{
return base_dexterity + extra_dex + level * dex_per_level;
}
double intelligence()
{
return base_intelligence + extra_int + level * int_per_level;
}
double health()
{
return base_health + extra_health + strength * health_per_str;
}
double mana()
{
return base_mana + extra_mana + intelligence * mana_per_int;
}
当属性系统不断膨胀时,伤害计算公式将会演变的极其复杂,同时由于技能和buff、道具系统的的无限扩充,伤害计算公式里就可能涉及到上百个属性。在这种复杂的属性系统中,靠程序在代码中直接编码这些公式逻辑已经不太现实。此外属性计算公式的规则基本都是策划主导的,而且在大型游戏中策划根据实际体验去调整计算公式是很频繁的,这样写死在代码里会带来及其繁重的编译和更新成本。同时这些属性更新计算在大型MMO的pvp活动中调用非常频繁,需要一个高效的结构去维护更新。
基于上述因素考虑,需要提供方便的工具让策划对这些属性计算公式进行编辑,同时让程序可以方便的将确定好的公式映射到代码。为了满足这个属性计算公式的编辑、展示、运行的需求,本人根据已有的项目经验,提供了一个比较完整的解决方案,开源在Github/formula_tree,在这个工程中提供了编辑器、调试器以及运行时。
属性公式编辑器
属性公式编辑器的源代码在formula_tree/editor中,是一个QT5的GUI程序,提供了公式的查看与编辑功能。
在属性公式编辑器中,我们把每一个变量的计算都组织成一颗公式计算树,下面这张图就对应了之前提及到的护甲计算流程:
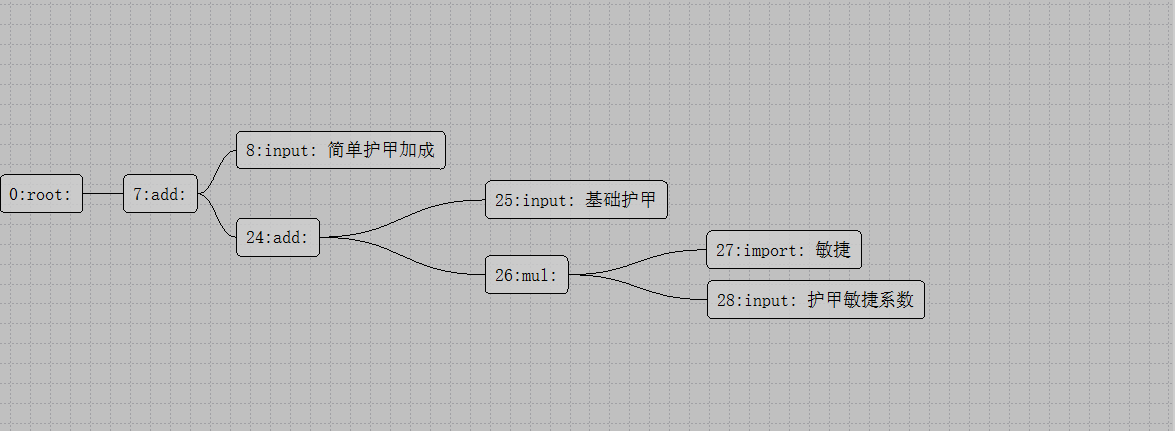
由于护甲依赖于敏捷,而敏捷同样是根据属性公式计算出来的,所以对于敏捷也有一颗计算树:
在这个属性公式计算树结构中,最左侧为根节点,代表当前计算树的最终输出,其他的非叶子节点代表一个数学计算函数,所以这些非叶子节点也称之为计算节点,子节点作为参数的顺序是从上到下。最右侧的则是叶子节点,叶子节点有三种类型:
- 字面值常量(
literal node),代表一个浮点数 - 输入变量(
input node),代表外部提供的一个变量,可以被外部修改 - 引用变量(
import node), 是通过计算公式计算出来的值,无法直接被外部修改,
每个引用变量都有对应名字的单独公式计算树文件,其文件格式为Json。
在了解了公式计算树中的叶子节点、计算节点和根节点之后,要启动这个计算公式编辑器需要额外提供两个文件:
- 提供变量清单的
json文件, 里面有两个字段 一个是input_attrs,这个是所有的输入节点的名字,另外一个是import_attrs,这个是所有的输出节点的名字。如果需要添加输入变量或者输出变量,则需要更新这个文件,下面就是测试用配置的一部分:
{
"input_attrs":
{
"level": "等级",
"strength_base": "基础力量",
"dexterity_base": "基础敏捷",
"intelligence_base": "基础智力",
"str_level_cof": "力量等级系数",
"dex_level_cof": "敏捷等级系数",
"int_level_cof": "智力等级系数",
"hp_base": "基础血量",
"hp_str_cof": "血量力量系数",
"armor_base": "基础护甲",
"armor_add": "简单护甲加成",
"armor_dex_cof": "护甲敏捷系数"
},
"import_attrs":
{
"max_hp": "最大血量",
"strength": "力量",
"dexterity": "敏捷",
"intelligence": "智力",
"armor": "护甲",
"phy_atk": "物理伤害",
"magic_atk": "法术伤害",
"magic_resist": "法术抗性",
"output_phy_atk": "最终物理伤害",
"output_magic_atk": "最终法术伤害"
}
}
- 提供运算符清单的
json文件, 里面定义了所有类型的计算节点编辑器相关字段,如果想添加计算函数,需要更新这个文件,下面就是测试用配置的一部分:
{
"add": {
"child_min": 2,
"child_max": 2,
"editable_item": {},
"comment": "a+b"
},
"dec": {
"child_min": 2,
"child_max": 2,
"editable_item": {},
"comment": "a-b"
},
"mul": {
"child_min": 2,
"child_max": 2,
"editable_item": {},
"comment": "a*b"
}
}
每个节点都以圆角矩形框来显示,框内左侧的数字代表这个节点的编号,注意这里的编号并不代表节点的遍历顺序,只是作为节点的唯一标识符使用,内部实现是这个节点在当前计算树中的创建顺序。
节点编辑时,首先需要选中一个节点,然后按下对应的快捷键:
Insert代表插入一个节点,作为当前节点排序最低的子节点Delete代表删除一个节点,root节点不可删除MoveUp,快捷键为Ctrl加上方向箭头, 代表把提升当前节点在父节点里的排序MoveDown快捷键为Ctrl加下方向箭头,代表降低当前节点在父节点里的排序Copy代表把当前节点为根的子树复制Paste代表把上次复制的节点粘贴为当前节点排序最低的新的子节点Cut代表剪切当前节点
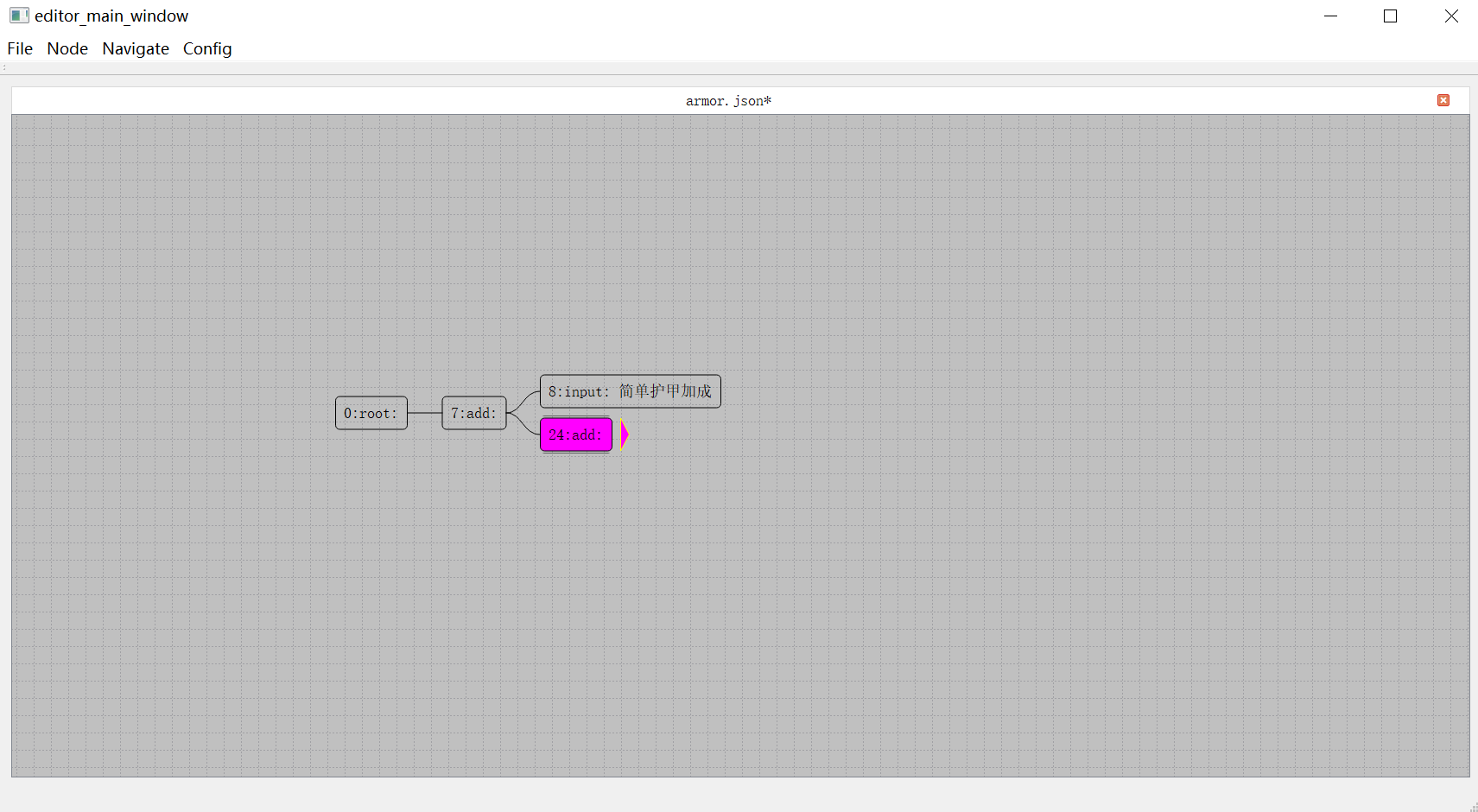
另外如果树里面的某个节点对应的子树节点太多,可以通过双击这个节点,将对应的子树进行折叠,同时这个节点右侧将会出现一个小的粉色钝角三角形,再双击则会展开折叠:
如果需要为一个复合节点增加一个新的子节点,则需要在选中一个复合节点之后按下Insert键,此时会弹出一个子节点创建选择窗口:
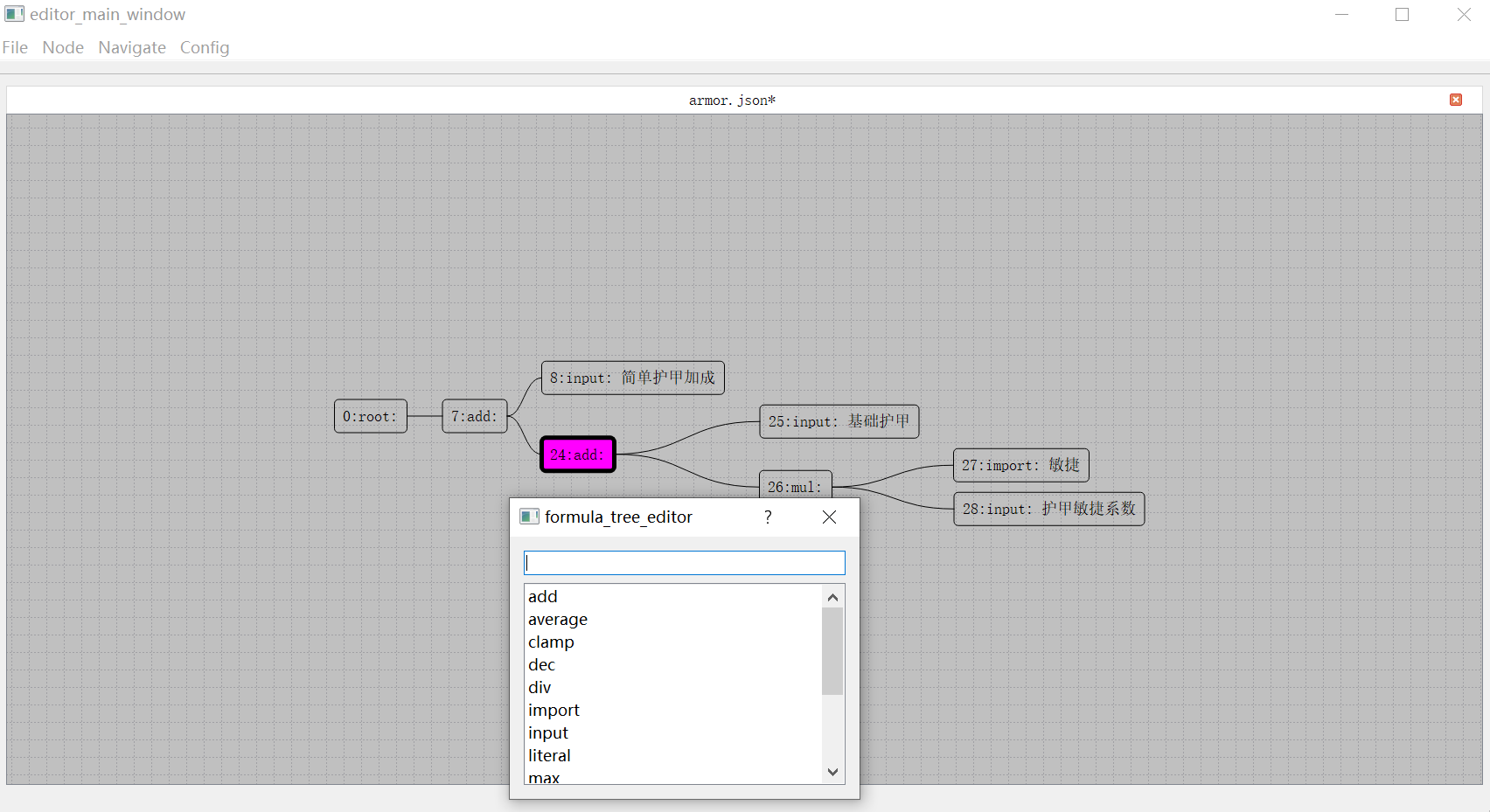
在这个文本框中可以执行搜索过滤,双击下面列表中的一项即为确认选择并以选择的节点类型来创建子节点。
在完成了编辑工作之后,保存的计算树文件是一个json文件,可以很方便的进行diff,下面就是护甲对应的计算树文件中的一部分,以数组的形式存储了整个树结构:
{
"extra": {},
"name": "armor.json",
"nodes": [
{
"children": [
7
],
"color": 0,
"comment": "",
"extra": {},
"idx": 0,
"is_collapsed": false,
"type": "root"
},
{
"children": [
8,
24
],
"color": 0,
"comment": "",
"extra": {},
"idx": 7,
"is_collapsed": false,
"parent": 0,
"type": "add"
}
]
}
有了公式编辑器的帮助,策划可以比较直观的去编辑与查看公式。不过如果有大批量的公式变动的话,整体的去浏览与修改公式就比较繁琐了,这个时候策划更倾向于直接修改基于文本的属性公式,例如这样的公式定义文件:
double base_strength = 1.0;
double base_dexterity = 1.0;
double base_intelligence = 1.0;
double extra_str = 0.0;
double extra_dex = 0.0;
double extra_int = 0.0;
double str_per_level = 1.0;
double dex_per_level = 1.0;
double int_per_level = 1.0;
double level = 1.0;
double base_armor = 0;
double extra_armor = 0;
double armor_per_dex = 1;
double base_physical_damage = 10;
double extra_physical_damage = 0;
double base_magic_defence = 15;
double extra_magic_defence = 0;
double base_health = 500;
double base_mana = 100;
double extra_health = 0;
double extra_mana = 0;
double health_per_str = 20;
double mana_per_int = 10;
double base_health_recovery = 2.0;
double base_mana_recovery = 1.0;
double extra_health_recovery = 0.0;
double extra_mana_recovery = 0.0;
double main_attr = 1.0;
double base_attack_gap = 2.0;
double minimal_attack_gap = 0.2;
double attack_speed_per_dex = 1;
double extra_attack_speed = 0;
double min(...);
double max(...);
double average(...);
double mul(...);
double add(...);
double clamp(double min, double max, double cur);
double pow(double base, double index);
double abs(double value);
double strength = base_strength + extra_str + level * str_per_level;
double dexterity = base_dexterity + extra_dex + level * dex_per_level;
double intelligence = base_intelligence + extra_int + level * int_per_level;
double armor = base_armor + extra_armor + dexterity * armor_per_dex;
double health = base_health + extra_health + strength * health_per_str;
double mana = base_mana + extra_mana + intelligence * mana_per_int;
double physical_damage = base_physical_damage + main_attr + extra_physical_damage;
double attack_speed = 100 + extra_attack_speed + attack_speed_per_dex * dexterity;
double attack_gap = max(minimal_attack_gap, base_attack_gap * 100 / attack_speed);
通过这个文件来看,这种完全基于文本的属性的计算公式在大量公式的可读性和可修改性方面的确有比较明显的优势。所以我在formula_tree/runtime/test/parse_formula中也提供了这种手写公式批量转换到公式计算树json文件的支持,同时在编辑器中也提供了公式树到上述的纯文本公式的转换功能。
属性公式运行时
属性公式运行时的源代码在formula_tree/runtime中,提供了公式的加载、求值等功能。
一个角色的所有属性所需公式被称为一组公式,里面有所有外部可见的输出变量名称,加载这一组公式的时候需要提供一个输出变量名的集合:
std::unordered_set<std::string> related_outputs =
{
"armor",
"dexterity",
"intelligence",
"magic_atk",
"magic_resist",
"max_hp",
"output_magic_atk",
"output_phy_atk",
"phy_atk",
"strength",
};
formula_tree_mgr::instance().set_repo_dir("../../data/export/");
auto cur_formula_tree = formula_tree_mgr::instance().load_formula_group("player", formula_desc{ related_outputs });
这里的load_formula_group内部流程可以概括如下:
-
公式系统会装载所有提供的公式,并对公式内部所引用的输出变量也进行递归加载。
-
每个对输出变量的引用都会生成一条输出变量的
root节点到当前import节点的边,通过这样的连接,组成了一个有向图。如果这个有向图里面有环的话,代表变量之间互相引用了,这是一个非法的公式。 -
在组成一个有向无环图之后,我们再删除所有的引用节点,把从引用节点出发的边的起点都转移到对应的输出变量的
root节点上。降低一点树的深度。
自此,一个角色的公式计算图构建完成。不过这里有一个非常重要的优化细节在上面的流程中没有提到:
- 同一组公式的结构是共享的,第一次加载之后这组公式的计算图就会保留,后续的同样的一组公式就直接复用这个计算图,这样就避免了重复的去加载同一组公式相关的公式文件并建立计算图的过程;
- 由于计算图被共享了,所以运行时公式的具体数值并没有放在计算图的节点里,而是每个使用这组公式的
entity自己创建一片连续内存区来存储这些数值,entity更新属性值的时候需要传递这块连续内存区域的指针进来
在这种设计下,我们需要对计算图中的每一个节点去分配一个唯一且连续的索引,作为运行时数值内存区域的偏移量,因此计算图中的计算节点定义如下:
class calc_node
{
std::vector<calc_node*> children; // 计算当前变量所需的所有子节点
std::vector<std::uint32_t> m_children_idxes; // 每个子节点的唯一索引
std::vector<calc_node*> parents; // 当前依赖当前节点计算结果的其他节点
formula_structure_tree* tree = nullptr; // 所属的计算图
std::uint32_t m_node_idx = 0;// 当前节点对应的唯一索引
node_type cacl_type; // 当前节点的节点类型
std::string name; // 当前节点的名字 如果是中间计算节点则会使用编辑器里设置的节点编号加上原始公式树中的编号
}
void calc_node::add_child(calc_node* child)
{
children.push_back(child);
m_children_idxes.push_back(child->m_node_idx);
child->parents.push_back(this);
}
在这样的节点定义之下,由初始的所有节点构造计算图的流程里除了需要维护好计算图结构之外,还需要处理好每个节点的索引赋值流程:
class formula_structure_tree
{
std::unordered_map<std::string, std::uint32_t> m_name_to_idx; // 每个带名字的节点对应的节点索引
std::vector<calc_node> m_nodes; // 计算图中的所有节点
std::vector<double> m_literals; // 计算图中的所有常量
}
formula_structure_tree::formula_structure_tree(const formula_desc_flat& flat_nodes_info)
{
std::uint32_t name_idx = 0;
m_nodes.reserve(flat_nodes_info.flat_nodes.size());
m_literals.resize(flat_nodes_info.flat_nodes.size(), 0);
// create all nodes
for (auto& one_node : flat_nodes_info.flat_nodes)
{
auto cur_node_name = one_node.name;
if (cur_node_name.empty())
{
cur_node_name = "T-" + std::to_string(name_idx++);
}
auto cur_pointer_node = calc_node(this, m_nodes.size(), cur_node_name, one_node.type);
if (one_node.type == node_type::literal)
{
m_literals[m_nodes.size()] = one_node.value;
}
m_nodes.push_back(cur_pointer_node);
}
// map names to node pointer
auto node_begin_pointer = m_nodes.data();
for (const auto& [k, v] : flat_nodes_info.node_indexes)
{
m_name_to_idx[k] = v;
}
// replace import/input leaf nodes with mapped node pointer
for (auto& one_node : flat_nodes_info.flat_nodes)
{
auto& cur_node = m_nodes[one_node.idx];
for (auto one_child : one_node.children)
{
auto& cur_child_name = flat_nodes_info.flat_nodes[one_child].name;
if (cur_child_name.empty())
{
// for non leaf/ literal nodes
cur_node.add_child(node_begin_pointer + one_child);
}
else
{
// for import input children nodes
cur_node.add_child(&m_nodes[m_name_to_idx[cur_child_name]]);
}
}
}
}
建立好这个计算图之后,每个使用这个计算图的实例都需要分配一个formula_value_tree的结构来作为计算过程中的数值存储区域:
class formula_value_tree
{
std::vector<double> m_node_values; // 这个数组的大小与计算图结构中的节点数量保持一致
const formula_structure_tree& m_node_tree; // 对应的计算图结构
};
formula_value_tree* formula_tree_mgr::load_formula_group(const std::string& formula_group_name, const formula_desc& output_node)
{
auto cur_iter = named_formulas.find(formula_group_name);
if (cur_iter != named_formulas.end())
{
return new formula_value_tree(*cur_iter->second);
}
else
{
auto cur_flat_info = formula_desc_flat(output_node);
auto cur_tree = new formula_structure_tree(cur_flat_info);
named_formulas[formula_group_name] = std::unique_ptr<formula_structure_tree>(cur_tree);
return new formula_value_tree(*cur_tree);
}
}
有了这个formula_value_tree之后我们来描述一下属性更新逻辑。简单版本的公式更新就是:每更新一个节点,就深度优先的更新他的parent节点。但是这样的更新有很严重的问题,如果从这个节点A出发到某个节点B有多条路径,则B节点及从B出发可达的节点会被重复更新多次。例如之前的物理减免公式0.06*dex/(1+abs(0.06*dex)),其构造出来的计算树里会出现多次敏捷这个临时变量:
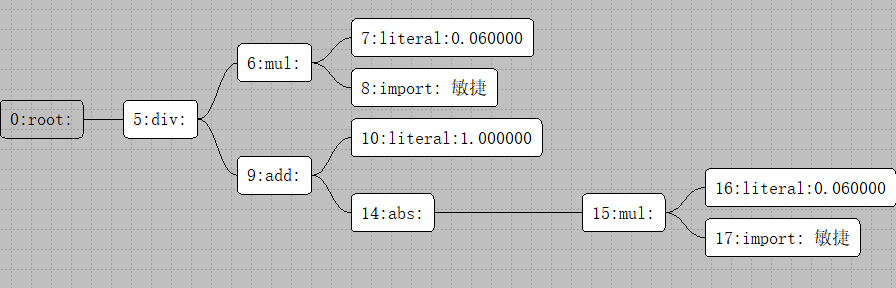
当敏捷更新的时候,会分别触发17->15->14->9->5->0和8->6->5->0这两个更新链路,两条链路都更新完成之后最终的输出才是正确的。
类似的问题在一次性更新多个变量的时候也存在,如果节点A依赖于输入节点B和输入节点C, 某一次更新流程中如果B、C的值都发生了改变,会导致A被更新多次。这种同一个节点在一次计算过程中被更新多次是非常浪费计算资源的,为了优化计算效率我们需要提供一个最优更新逻辑,保证一个节点最多只被更新一次。因此,在上面构建的公式计算图的基础上,我们需要标注节点的额外信息:
对每个节点进行高度标记,所有的输入节点的高度设置为
0,然后进行递归更新,每个节点的高度等于所有子节点的高度最大值再加上1
此时calc_node结构体上需要增加一个字段,来表示这个节点在计算图中的高度,同时在构造计算图的时候要设置好这个高度:
class calc_node
{
// 省略之前的字段
std::uint32_t m_height = 0;
};
formula_structure_tree::formula_structure_tree(const formula_desc_flat& flat_nodes_info)
{
// 省略之前提到的构造计算图逻辑 开始处理节点的深度计算
std::vector<std::uint64_t> node_child_count(m_nodes.size(), 0); // 每个节点的子节点个数
std::deque<calc_node*> height_queue; // 所有的待处理节点
for (auto& one_node : flat_nodes_info.flat_nodes)
{
auto& cur_node = m_nodes[one_node.idx];
auto cur_child_size = one_node.children.size();
if (cur_child_size)
{
node_child_count[one_node.idx] = cur_child_size;
}
else
{
height_queue.push_back(node_begin_pointer + one_node.idx);
}
}
// 在这里 height_queue里的节点都是高度为0的常量节点和输入节点
while (!height_queue.empty())
{
auto cur_node = height_queue.front();
height_queue.pop_front();
for (auto one_parent : cur_node->parents)
{
// 每个节点的高度为所有子节点的最大高度加1
one_parent->m_height = std::max(one_parent->m_height, cur_node->m_height + 1);
// 每次把入度为0的节点删除 同时扣除所有与其连接的其他节点的入度
auto cur_child_count = node_child_count[one_parent->m_node_idx]--;
if (cur_child_count == 1)
{
// 当入度为0的时候 加入到处理队列中
height_queue.push_back(one_parent);
}
}
}
}
在这个新增加的信息基础上, 我们提供了单变量更新和批量更新,其实单变量更新就是只有一个变量的批量更新,所以我们这里只阐述批量更新的逻辑:
void formula_value_tree::update_attr_batch(const std::vector<std::pair<std::string, double>>& input_attrs)
{
const auto& name_to_idx = m_node_tree.name_to_idx();
for (auto one_attr : input_attrs)
{
auto cur_iter = name_to_idx.find(one_attr.first);
if (cur_iter == name_to_idx.end())
{
continue;
}
m_node_tree.nodes()[cur_iter->second].update_value(this, m_node_values, one_attr.second);
}
m_updated_attrs.clear();
return process_update_queue();
}
update_value负责把设置这些节点的最新值,同时这些节点的父节点加入到任务队列中,这里用一个m_node_in_queue_flag数组作为集合来避免重复添加节点到队列中:
void calc_node::update_value(formula_value_tree* value_tree, std::vector<double>& node_values, double new_value) const
{
if (new_value == node_values[m_node_idx])
{
return;
}
node_values[m_node_idx] = new_value;
for (auto one_parent : parents)
{
value_tree->add_node_to_update_queue(one_parent);
}
}
bool formula_value_tree::add_node_to_update_queue(const calc_node* new_node)
{
if (m_node_in_queue_flag[new_node->node_idx()])
{
return false;
}
m_node_in_queue_flag[new_node->node_idx()] = 1;
m_in_queue_nodes.push_back(std::uint32_t(new_node->node_idx()));
update_queue.push(new_node);
return true;
}
然后调用process_update_queue来处理递归更新:只要队列不为空,从队列中取出高度值最低的节点,进行更新计算,如果值进行了改变,则将当前节点的所有可达节点中不在任务队列中的节点加入到任务队列,如此重复直到任务队列为空。由于我们给每个节点设置了一个高度作为计算优先级,所以这个update_queue的定义如下:
struct node_compare
{
bool operator()(const calc_node* a, const calc_node* b) const
{
return a->height() > b->height();
}
};
class formula_value_tree
{
std::priority_queue<const calc_node*, std::vector<const calc_node*>, node_compare> update_queue;
};
有了这个node_compare的支持之后,整个更新流程代码就比较简洁了:
void formula_value_tree::process_update_queue()
{
std::unordered_set<std::string> reached_name;
while (!update_queue.empty())
{
auto cur_top = update_queue.top();
update_queue.pop();
if (cur_top->update(m_node_values))
{
for (auto one_parent : cur_top->parents)
{
add_node_to_update_queue(one_parent);
}
}
}
for (const auto& one_idx : m_in_queue_nodes)
{
m_node_in_queue_flag[one_idx] = 0;
}
m_in_queue_nodes.clear();
}
在上面的更新结构下,我们给每个节点都赋予了一个更新优先级,在优先级的驱动下,我们就保证了一个节点最多被更新一次。这里的cur_top->update就是公式计算的逻辑分发函数,内部发现计算前后的数值一样的话就不再递归更新:
bool calc_node::update(std::vector<double>& node_values) const
{
double result;
switch (cacl_type)
{
case node_type::root:
result = node_values[m_children_idxes[0]];
break;
case node_type::literal:
result = node_values[m_node_idx];
break;
case node_type::add:
result = 0.0;
for (auto one_child: m_children_idxes)
{
result += node_values[one_child];
}
break;
case node_type::dec:
result = node_values[m_children_idxes[0]] - node_values[m_children_idxes[1]];
break;
case node_type::mul:
result = 1.0;
for (auto one_child: m_children_idxes)
{
result *= node_values[one_child];
}
break;
// 下面省略很多其他分支
}
if (result == node_values[m_node_idx])
{
return false;
}
else
{
node_values[m_node_idx] = result;
return true;
}
}
如果外界系统想要知道本次更新过程中有哪些属性被更改,可以注册属性的更新观察:
struct attr_update_info
{
std::uint32_t node_idx; // 公式图使用的内部节点索引
std::uint32_t watch_idx; //外部监听者使用的属性索引
double value;
};
// 所有被关注的节点索引映射到外部的属性索引 如果为0代表没有被关注
std::vector<std::uint32_t> m_node_watch_idxes;
// 本次计算过程中的所有被修改属性
std::vector< attr_update_info> m_updated_attrs;
const std::vector< attr_update_info>& updated_attrs() const
{
return m_updated_attrs;
}
// 将一些attr的名字映射为外部的一些索引 更新attr的时候顺便会更新m_updated_attrs 外部可以通过这些索引来加速处理 不再需要名字来查找
void watch_nodes(const std::unordered_map<std::string, std::uint32_t>& watch_indexes)
{
m_updated_attrs.clear();
std::fill(m_node_watch_idxes.begin(), m_node_watch_idxes.end(), 0);
const auto& all_names = m_node_tree.name_to_idx();
for (const auto& one_pair : watch_indexes)
{
auto temp_iter = all_names.find(one_pair.first);
if (temp_iter == all_names.end())
{
continue;
}
m_node_watch_idxes[temp_iter->second] = one_pair.second;
}
}
在执行队列里的优先级更新的时候,如果发现当前遇到的节点是一个输出节点,则加入到通知列表中:
if (cur_top->cacl_type == node_type::root)
{
auto cur_watch_idx = m_node_watch_idxes[cur_top->m_node_idx];
if (cur_watch_idx)
{
m_updated_attrs.push_back(attr_update_info{ cur_top->m_node_idx, cur_watch_idx, m_node_values[cur_top->m_node_idx] });
}
}
外部系统需要在更新完成之后获取这个m_update_attrs来执行相应的修改回调。
为了方便使用者去验证运行时变量的更新状态是否正确,我还在属性公式运行时里增加了比较方便的调试输出功能,外部可以传递一个函数进来接收属性字段更新时的调试信息:
void formula_value_tree::set_debug(std::function<void(const std::string&)> debug_func)
{
m_debug_print_func = debug_func;
}
在process_update_queue的时候,每次遇到一个root节点,都会调用这个调试输出函数,这样就可以非常方便的跟踪公式计算流程了:
if (cur_top->cacl_type == node_type::root)
{
auto cur_watch_idx = m_node_watch_idxes[cur_top->m_node_idx];
if (cur_watch_idx)
{
m_updated_attrs.push_back(attr_update_info{ cur_top->m_node_idx, cur_watch_idx, m_node_values[cur_top->m_node_idx] });
}
if (m_debug_print_func)
{
std::ostringstream oss;
cur_top->pretty_print_value(m_node_values, reached_name, oss);
m_debug_print_func(oss.str());
}
}
Mosaic Game中的属性公式
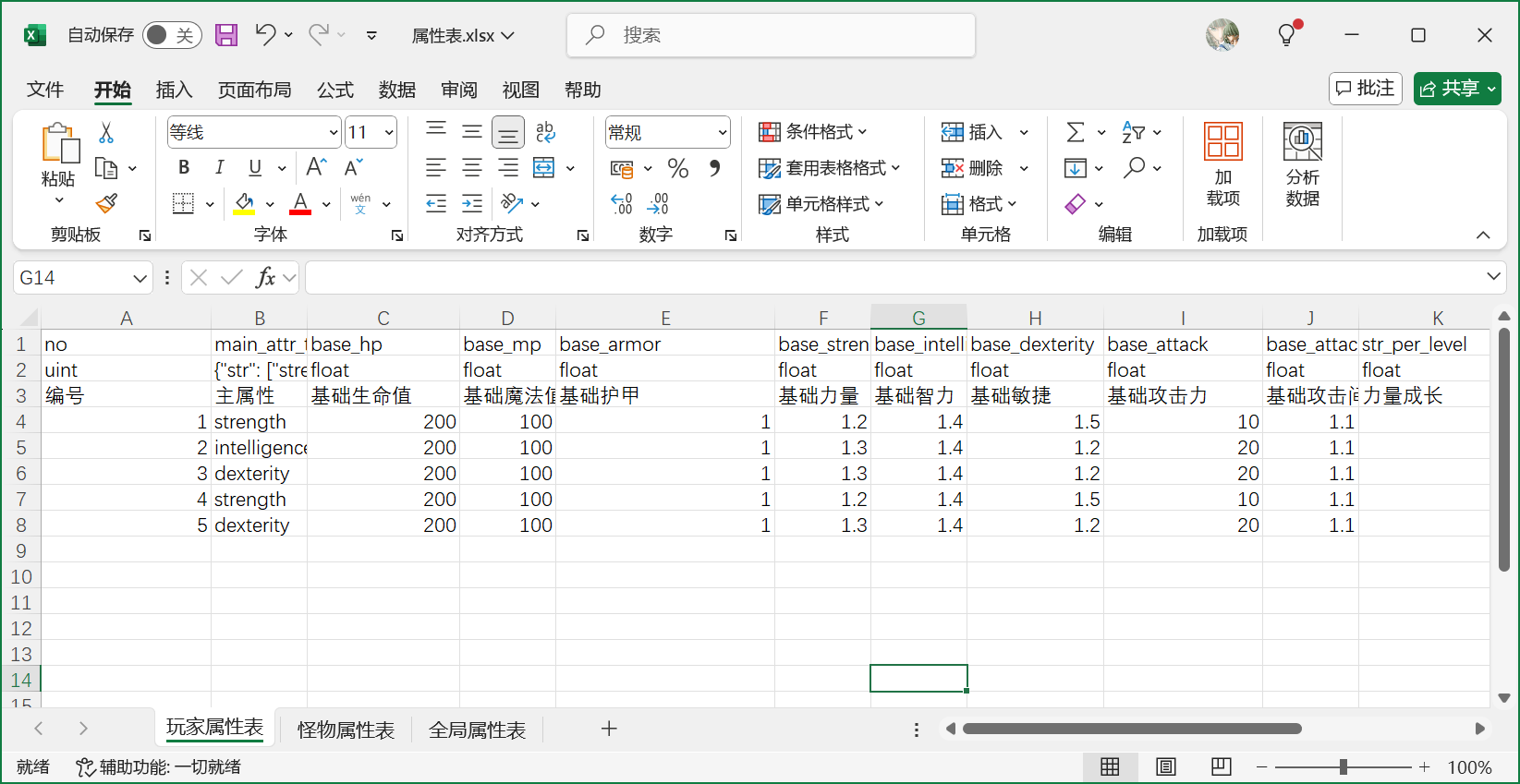
在mosaic_game中并没有使用编辑器去创建公式,而是使用前面介绍过的直接从公式文件生成公式树的方法来创建,对应的公式源文件在generator/config/attr_formula/attr_formula.cpp。在这个公式源文件中会引用到很多输入变量,例如随等级提升的各种属性值,这些变量的值并不是固定的,而是根据配置文件来确定的,下面就是基于excel的怪物属性配置文件:
在每个有战斗功能的actor上,都会有一个对应的actor_attr_component来管理属性公式:
struct attr_desc
{
double value = 0.0;
std::uint32_t idx_in_tree = 0;
std::uint32_t update_count = 0;
};
class Meta(rpc) actor_attr_component final: public actor_component::sub_class<actor_attr_component>
{
std::unique_ptr<formula_tree::runtime::formula_value_tree> m_attr_formula_tree;
std::vector<attr_desc> m_attr_inputs;
std::vector<attr_desc> m_attr_outputs;
}
这里的m_attr_formula_tree就是当前actor所拥有的属性计算图的数值实例,m_attr_inputs里存储了属性计算图里的所有输入节点,m_attr_outputs里存储了属性计算图里的所有输出节点。这两个数组的索引都对应各自的枚举值定义,m_attr_inputs对应的是attr_input,m_attr_outputs对应的是attr_output,下面展示这两个枚举类的部分定义:
enum class attr_input
{
extra_str = 0,
extra_dex,
extra_int,
extra_armor,
extra_attack,
};
enum class attr_output
{
strength,
dexterity,
intelligence,
armor,
hp_max,
mp_max,
attack,
attack_speed,
attack_gap,
physical_damage_final_ratio,
magical_damage_final_ratio,
physical_damage_final,
magical_damage_final,
total_hp_recovery,
total_mp_recovery,
max_output,
};
这里的enums::attr_output定义了所有的actor外部可见的属性名,在attr_formula_init中以这些属性名作为引脚去调用load_formula_group来创建actor这一组公式,构造公式计算图:
void actor_attr_component::attr_formula_init()
{
if(m_attr_formula_tree)
{
return;
}
formula_tree::runtime::formula_desc cur_formula_desc;
for(auto one_output_enum: magic_enum::enum_entries<enums::attr_output>())
{
if(one_output_enum.first == enums::attr_output::max_output)
{
continue;
}
cur_formula_desc.output_names.insert(std::string(one_output_enum.second));
}
auto cur_formula_tree = formula_tree::runtime::formula_tree_mgr::instance().load_formula_group("actor", cur_formula_desc);
m_attr_formula_tree.reset(cur_formula_tree);
// 暂时省略后续代码
}
在加载好公式计算图之后,读取之前excel中配置好的输入节点数据,来执行公式系统的第一次数值初始化:
std::vector<std::pair<std::uint32_t, double>> batched_input_attrs;
batched_input_attrs.reserve(m_attr_inputs.size());
for(auto one_input_enum: magic_enum::enum_entries<enums::attr_input>())
{
if(one_input_enum.first == enums::attr_input::max_input)
{
continue;
}
auto& cur_attr_input = m_attr_inputs[int(one_input_enum.first)];
cur_attr_input.idx_in_tree = cur_formula_tree->name_to_node_idx(std::string(one_input_enum.second));
batched_input_attrs.push_back(std::make_pair(cur_attr_input.idx_in_tree, cur_attr_input.value));
// m_owner->logger()->debug("update input attr {} with value {}", one_input_enum.second, cur_attr_input.value);
}
cur_formula_tree->update_attr_batch(batched_input_attrs);
在第一次数值初始化之后,获取此时的所有属性输出节点的最新值。由于这些数值属性会参与到属性同步系统,所以需要通过set_attr_property来将这些输出数值属性设置到属性同步系统的对应字段上:
for(auto one_output_enum: magic_enum::enum_entries<enums::attr_output>())
{
if(one_output_enum.first == enums::attr_output::max_output)
{
continue;
}
auto& cur_attr_output = m_attr_outputs[int(one_output_enum.first)];
cur_attr_output.idx_in_tree = cur_formula_tree->name_to_node_idx(std::string(one_output_enum.second));
cur_attr_output.value = cur_formula_tree->get_attr_value(cur_attr_output.idx_in_tree).value();
set_attr_property(one_output_enum.first);
}
m_owner->dispatcher().dispatch(enums::event_category::attr_init_finish, std::string{});
set_attr_property的实现就是一个简单的switch_case,将attr_output的枚举映射到参与属性同步的具体字段上:
class Meta(property) attr_prop
{
Meta(property(sync_clients)) double m_hp;
Meta(property(sync_clients)) double m_mp;
Meta(property(sync_clients)) double m_hp_max;
Meta(property(sync_clients)) double m_mp_max;
Meta(property(sync_clients)) double m_str;
Meta(property(sync_clients)) double m_dex;
Meta(property(sync_clients)) double m_intel;
Meta(property(sync_clients)) double m_armor;
Meta(property(sync_clients)) double m_attack_gap;
Meta(property(sync_clients)) double m_attack_speed;
Meta(property(sync_clients)) double m_attack;
Meta(property(sync_clients)) double m_magic_defence;
Meta(property(sync_clients)) std::uint64_t m_recovery_check_ts;
#ifndef __meta_parse__
#include "common/attr_prop.generated.inch"
#endif
};
void actor_attr_component::set_attr_property(enums::attr_output cur_attr_type)
{
auto cur_attr_value = m_attr_outputs[int(cur_attr_type)].value;
// m_owner->logger()->debug("update output attr {} with value {}", magic_enum::enum_name(cur_attr_type), cur_attr_value);
switch (cur_attr_type)
{
case enums::attr_output::strength:
m_owner->attr_prop_proxy()->str().set(cur_attr_value);
break;
case enums::attr_output::dexterity:
m_owner->attr_prop_proxy()->dex().set(cur_attr_value);
break;
case enums::attr_output::intelligence:
m_owner->attr_prop_proxy()->intel().set(cur_attr_value);
break;
case enums::attr_output::armor:
m_owner->attr_prop_proxy()->armor().set(cur_attr_value);
break;
case enums::attr_output::attack:
m_owner->attr_prop_proxy()->attack().set(cur_attr_value);
break;
case enums::attr_output::attack_speed:
m_owner->attr_prop_proxy()->attack_speed().set(cur_attr_value);
break;
case enums::attr_output::attack_gap:
m_owner->attr_prop_proxy()->attack_gap().set(cur_attr_value);
break;
case enums::attr_output::hp_max:
m_owner->attr_prop_proxy()->hp_max().set(cur_attr_value);
break;
case enums::attr_output::mp_max:
m_owner->attr_prop_proxy()->mp_max().set(cur_attr_value);
break;
default:
break;
}
}
上面的逻辑只是做了数值属性初始化时向属性同步系统里的相关属性做初始同步。如果外部的数值输入节点发生了变化,需要将这个输入节点的最新值推送到公式计算图中:
void attr_input_update(enums::attr_input attr_input_type, double delta);
void attr_input_update_batch(const std::vector<std::pair<std::uint32_t, double>>& batch_delta_attrs, bool is_add = true);
void attr_input_set(enums::attr_input attr_input_type, double value);
在这三个接口中都会驱动公式计算图里的相关节点进行数值更新。为了能够及时的通知到属性同步系统,需要在公式计算图中注册相关输出节点的变化通知,所以第一次初始化数值属性的时候顺带的把这些节点改变的监听增加上:
std::unordered_map<std::string, std::uint32_t> cur_watched_nodes;
for(auto one_output_enum: magic_enum::enum_entries<enums::attr_output>())
{
if(one_output_enum.first == enums::attr_output::max_output)
{
continue;
}
cur_watched_nodes[std::string(one_output_enum.second)] = std::uint32_t(one_output_enum.first) + 1;
}
cur_formula_tree->watch_nodes(cur_watched_nodes);
在完成这些注册之后,每次外部触发了公式计算图的更新,都需要使用process_formula_updates检查输出的属性更新信息,并使用set_attr_property通知到属性同步系统:
void actor_attr_component::process_formula_updates()
{
auto& cur_updated_attrs = m_attr_formula_tree->updated_attrs();
for(const auto& one_attr: cur_updated_attrs)
{
auto cur_watch_idx = one_attr.watch_idx - 1;
m_attr_outputs[cur_watch_idx].value = one_attr.value;
m_attr_outputs[cur_watch_idx].update_count++;
set_attr_property(enums::attr_output(cur_watch_idx));
m_owner->dispatcher().dispatch(enums::event_category::attr_update, m_attr_outputs[cur_watch_idx]);
}
}