游戏中的视野对象同步
游戏中的视野对象同步介绍
多人在线游戏的核心内容就是玩家与玩家之间的互动,玩家在游戏虚拟场景里使用其在游戏内控制的虚拟角色与其他玩家控制的虚拟角色做各种交互,特别是在3D游戏中玩家控制的3D角色之间的互动,包括文字、语音、角色外观、角色动作等各种交流与展现方式。这种多样性的互动带来的体验远远大于平常的聊天软件提供的文字互动,这也是游戏这种虚拟现实世界的核心吸引力。为了构造这种虚拟世界里的多人互动,在游戏客户端呈现的虚拟世界中我们不仅需要将当前主角玩家控制的虚拟角色渲染出来,还需要将处于同一虚拟世界中的其他玩家也渲染出来。但是由于客户端计算资源、服务器计算资源和网络带宽等各种资源限制,我们无法将整个虚拟世界里的玩家角色都在一个客户端里呈现,更具体的来说主流游戏的手机端同屏角色数量基本都小于30。同时由于人脑也是一种计算资源,其计算能力也是有限的,现实生活中无时无刻向我们传递过来的各种视觉听觉信息都会人脑过滤掉其中的很大一部分,只处理大脑认为有用的那些信息。具体体现在离自身越近的信息越不容易被过滤,越靠近视野中心的信息越不容易被过滤。在游戏资源和人脑资源的双重限制下,游戏客户端一般都只会渲染离当前玩家一定范围内的且在视野中那些玩家,这个关注区域就叫做AOI(Area of Interest),而这个关注范围半径则叫做AOI_Radius(虽然叫radius但是其形状不一定是圆形,也可能是正方形)。所以多人在线游戏服务器的网络角色同步系统内都会有一个AOI系统,来针对每个角色的客户端计算出其需要关心的其他角色的集合。集合内的玩家位置、外观、动作等数据的变化会通知到此客户端,而集合外的玩家数据变化则不通知。除了客户端玩家对于AOI计算有需求之外,很多服务端的逻辑也需要AOI系统,包括但不限于:
NPC的战斗感知半径,当玩家进入此半径之后会触发该NPC进入战斗状态- 场景内布置的陷阱等触发区域
- 战斗系统的光环类型技能实现
本章内容将对游戏内的AOI系统提供一个基本的介绍,包括主流的AOI算法、UE中的Actor同步机制以及mosaic_game中的AOI系统实现细节。
主流AOI算法
aoi_entity
为了更加详细的以cpp代码说明下文中介绍的各种AOI算法的流程,我们定义了一个aoi_entity的类型,这里为了简化讨论,只限制场景为平面,坐标系为二维坐标,暂时不考虑三维坐标场景:
using pos_t = std::array<float, 2>; // 这里的坐标为(x, y)形式
struct aoi_entity
{
std::uint64_t id; // entity 的唯一标识符
std::unordered_map<std::uint64_t, aoi_entity*> interest; // 最终进入当前entity 视野的aoi_entity
std::unordered_map<std::uint64_t, aoi_entity*> interested; // 当前entity进入了哪些aoi_entity的视野
pos_t pos; // 当前actor的位置
float radius; // 当前entity的AOI半径
void calc_aoi(aoi_entity* other); // 计算另外一个aoi_entity是否应该进入当前的interest 集合
virtual void on_enter_aoi(aoi_entity* other); // 当有其他entity进入当前entity->interest 时的回调
virtual void on_leave_aoi(aoi_entity* other); // 当有其他entity离开当前entity->interest 时的回调
};
float distance(const pos_t& a, const pos_t& b); // 这个函数负责计算两个坐标之间的距离
另外再定义一个world类型,来存储所有的参与AOI计算的aoi_entity:
struct world
{
std::unordered_map<std::uint64_t, aoi_entity*> aoi_entities;
virtual void update_aoi();
};
基于暴力遍历的AOI计算
暴力遍历法顾名思义就是对于每个客户端控制的玩家aoi_entity, 先遍历其interest集合,删除掉其中已经不在当前radius范围内的,然后遍历当前场景内的所有aoi_entity,计算两者之间的距离是否在同步范围之内,如果在同步范围内,则尝试加入到AOI集合。
void aoi_entity::clear_invalid()
{
std::vector<std::pair<std::uint64_t, aoi_entity*>> remove_entitiess;
for(const auto [one_id, one_entity]: interest)
{
if(distance(one_entity->pos, pos) > radius)
{
remove_entitiess.push_back(std::make_pair(one_id, one_entity));
}
}
for(auto one_remove: remove_entitiess)
{
interest.erase(one_remove.first);
one_remove.second->interested.erase(id);
on_leave_aoi(one_remove.second);
}
}
void aoi_entity::calc_aoi(aoi_entity* other)
{
if(this == other_entity)
{
return;
}
if(interest.find(other_entity->id) != interest.end())
{
return;
}
if(distance(pos, other_entity->pos) <= radius)
{
interest[other_entity->id] = other_entity;
other_entity->interested[id] = this;
on_aoi_enter(other_entity);
}
}
void world::update_aoi()
{
for(const auto [one_id, one_entity]: aoi_entities)
{
one_entity->clear_invalid();
for(const auto [other_id, other_entity]: aoi_entities)
{
one_entity->calc_aoi(other_entity);
}
}
}
在这种计算流程下,拥有N个aoi_entity且有K个客户端玩家的的world单次执行update_aoi最坏情况下的算法复杂度为K*N。在我们所期望的大世界场景下,K经常超过1000,而 N则超过10000,此时的计算复杂度就非常高了,1s内执行不了几次update_aoi。因此这个暴力算法在实际的游戏服务器中基本不被采用,一般来说都是作为对比方案而存在的。
基于网格空间划分的AOI计算
在上面介绍的暴力遍历计算AOI的实现中,最大的计算压力在第二层循环里计算当前world->aoi_entities里的每个aoi_entity到当前aoi_entity之间的距离,此时在判定全场景内哪些玩家在当前玩家AOI半径内。实际上在正常的游戏场景中,不会出现所有玩家和NPC(Non-Player Character)都挤在一小片区域的情况,一般来说NPC都比较稀疏的布置在场景中,而玩家则主要分布在场景中的道路沿线。此时在玩家AOI半径内的aoi_entity其实数量不是很多,相对于world->aoi_entities集合的大小来说,不足其1/10。如果我们可以快速的把一些与当前玩家较远的aoi_entity筛出,就可以大规模的减少distance函数的调用与距离的比较,从而加快AOI的执行效率。这里的快速筛查手段一般使用的都是基于网格的空间划分,此时我们选取一个合适的划分粒度cell_size,将整个二维平面场景从左上角进行切分,这样场景就会被分割为多个正方形cell。我们给每个正方形cell进行编号(x,y),同时给每个正方形cell都附加一个集合entities_in_cell,内部存储所有在当前正方形cell空间区域内的aoi_entities:
struct cell_id
{
std::uint32_t x;
std::uint32_t y;
};
struct cell_info
{
cell_id id;
std::unordered_map<std::uint64_t, aoi_entity*> entities_in_cell;
};
struct grid_world: public world
{
const float cell_size; // 当前world所选取的正方形cell的边长
pos_t bound_min; // 当前world的坐标最低点
cell_id calc_cell_id(const pos_t& pos) const; // 计算一个pos到对应的cell_id
std::vector<std::vector<cell_info>> all_cells; // 存储了当前world里的所有cell
void update_aoi() override;
};
在有了这个结构之后,对于一个aoi_entity(A),我们计算以A->pos为中心以A->radius为半径的圆形有交集的cell_id集合cellsA。对于不在这个交集区域内的其他所有cell,其中的entities_in_cell中存储的aoi_entity(B)一定不在当前aoi_entity(A)范围内,因为这些cell代表的正方形区域到A->pos的最短距离都大于A->radius。通过计算cellsA,我们极大的减少了计算A->interest所需要遍历的aoi_entities集合大小,更新AOI的效率得到了极大的提升,此时grid_world->update_aoi的实现如下:
void grid_world::update_aoi()
{
for(const auto [one_id, one_entity]: aoi_entities)
{
one_entity->clear_invalid();
// 计算包含当前aoi_entity 的AOI圆所覆盖的cell 区域
auto low_cell_id = calc_cell_id(one_entity->pos - pos_t(one_entity->radius, one_entity->radius));
auto high_cell_id = calc_cell_id(one_entity->pos + pos_t(one_entity->radius, one_entity->radius));
for(auto cell_x = low_cell_id.x; cell_x <= high_cell_id.x; cell_x++)
{
for(auto cell_y = low_cell_id.y; cell_y <= high_cell_id.y; cell_y++)
{
const auto& cur_cell = all_cells[cell_x][cell_y];
for(const auto [other_id, other_entity]: cur_cell->entities_in_cell)
{
one_entity->calc_aoi(other_entity);
}
}
}
}
}
下面我们以一个简单的图形化样例来更加形象的解释上述代码的流程,在此图例中场景被划分为了4*4的网格,带字母的蓝色小圆圈A-H对应了8个不同的aoi_entity,图中的黄色大圆圈代表A对应的AOI圆。此时A的AOI圆覆盖的low_cell_id为(1, 1),high_cell_id为(2, 2),覆盖的cell集合包含了四个cell分别是(1,1),(1,2),(2,1),(2,2)。在这四个cell中的entities_in_cell为(A, B, C, J, G, H, I),计算AOI时只需要与这些entity做calc_aoi计算,而(D, E, F)则被筛除掉了。
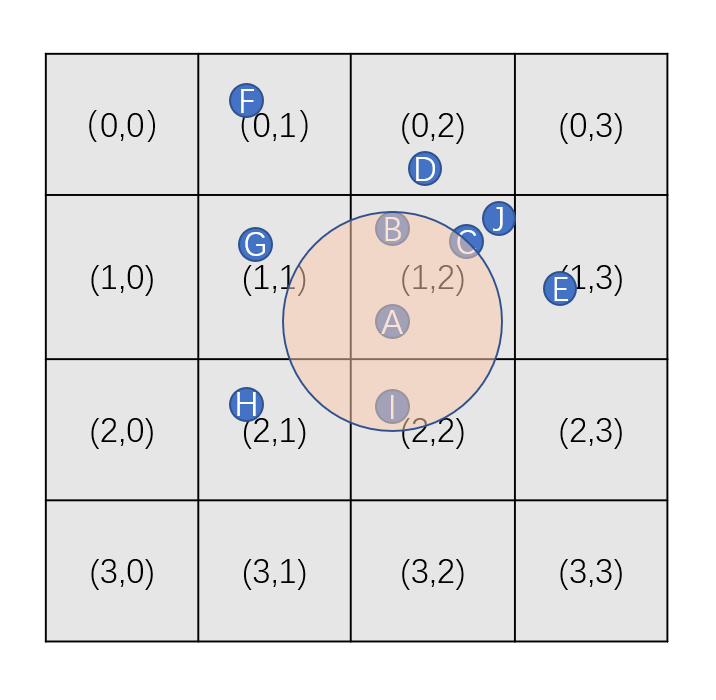
为了维持我们定义的cell->entities_in_cell字段里的aoi_entity的确在此cell中,最简单的做法是每次在update_aoi之前都将网格清空然后重新往网格中插入所有的aoi_entity,这里的时间复杂度为网格数量加aoi_entity数量之和的常数项。但是如果网格的数量级大于aoi_entity的数量级时,这种重建的方法是非常低效的。考虑到每次update_aoi间隔期间移动的aoi_entity一般不多,我们可以在每个aoi_entity改变位置时都尝试去修正其所在的cell,为此grid_world上需要添加一个接口:
void grid_world::on_entity_move(aoi_entity* cur_entity, const pos_t& new_pos)
{
auto pre_cell_id = calc_cell_id(cur_entity->pos);
cur_entity->pos = new_pos;
auto new_cell_id = calc_cell_id(cur_entity->pos);
if(new_cell_id != pre_cell_id)
{
all_cells[pre_cell_id.x][pre_cell_id.y].entities_in_cell.erase(cur_entity->id);
all_cells[new_cell_id.x][new_cell_id.y].entities_in_cell[cur_entity->id] = cur_entity;
}
}
由于calc_cell_id的复杂度为常数,所以on_entity_move的复杂度也为常数,效率非常高,即使每个aoi_entity都移动位置触发了此函数,其总的时间复杂度也就是aoi_entity数量的常数倍,其维护消耗低于重建的小号,同时相对于update_aoi的时间复杂度来说都是忽略不计。
这个基于网格的空间划分在计算AOI上的加速效果受cell_size的影响:如果cell_size很大,则会导致覆盖区域内的网格总面积过大,其内部的entities_in_cell集合会显著的增多,影响筛查效率;如果cell_size过小则会导致on_entity_move时频繁的在cell中添加和删除aoi_entity,也会影响一定的性能。一般来说这里的cell_size会选择客户端玩家的aoi_radius的中位数,这样达到一些效率上的均衡。
对于大地图而言,上面代码实现基于网格的空间划分在内存上会有很大的压力,假设在特定粒度的cell_size下当前地图的最大cell坐标为(x,y),场景内没有任何aoi_entities时grid_world::all_cells所占的内存为(x+1)*sizeof(vector<cell_info>) + (x+1)*(y+1)*sizeof(cell_info)。地图大小为8km*8km而cell_size为20时, grid_world::all_cells大约会使用8Mb左右的内存,也算是一个不小的开销。而且上面的实现使用了太多的std::unordered_map容器,运行时的动态删减会触发很多的内存动态分配与释放。所以实际项目中会以一个数组形式实现的unordered_map来存储所有的cell_info以及关联的aoi_entities:
// 链表内的节点定义 对于每个aoi_entity 都需要分配一个hash_cell_node
struct hash_cell_node
{
cell_id id;
aoi_entity* entity = nullptr;
hash_cell_node* next = nullptr;
};
std::vector<hash_cell_node> linked_hash_map; // 数组形式实现的unordered_map 其容量一般设置为场景内aoi_entity的最大可能数量 * 4 然后再往2的指数上取整
std::uint32_t get_cell_hash(cell_id in_cell_id, std::uint32_t mask)
{
// 这里随便选取两个常量来简单的计算hash 不同的项目可以采取不同的实现
const std::uint32_t h1 = 0x8da6b343;
const std::uint32_t h2 = 0xd8163841;
std::uint32_t n = h1 * in_cell_id.x + h2 * in_cell_id.y;
return n & mask;
}
hash_cell_node* get_hash_cell_node(cell_id in_cell_id) // 计算一个cell_id对应的链表head节点
{
const std::uint32_t mask = linked_hash_map.size() - 1;
return &linked_hash_map[get_cell_hash(in_cell_id, mask)];
}
下面提供一个图形来形象的描述一下场景内的aoi_entity是如何存储在linked_hash_map之中的,这里使用一个非常简单的hash = (4*x + y)/2:
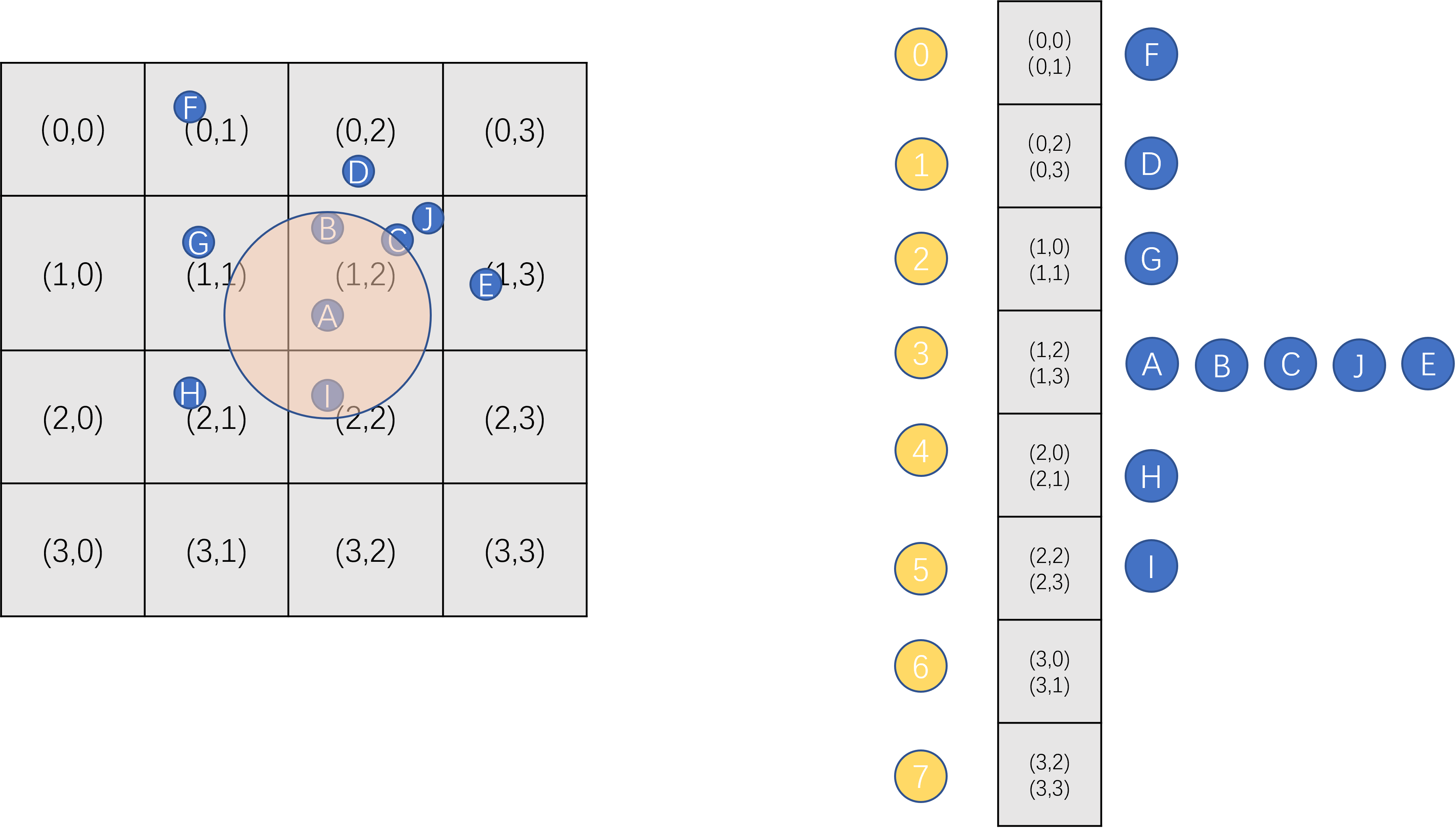
在这种设计下,如果一个场景内的aoi_entity最大数量为4096,则我们将linked_hash_map的大小初始化为4096*4,在64bit平台下的内存占用为384Kb,这个的内存占用相比之前的8Mb降低到了原来的1/20。
由于linked_hash_map内的每个链表都包含了hash值相同的所有cell内的aoi_entity,所以update_aoi时需要小心的过滤不是所期望的cell:
void grid_world::update_aoi()
{
for(const auto [one_id, one_entity]: aoi_entities)
{
one_entity->clear_invalid();
// 计算包含当前aoi_entity 的AOI圆所覆盖的cell 区域
auto low_cell_id = calc_cell_id(one_entity->pos - pos_t(one_entity->radius, one_entity->radius));
auto high_cell_id = calc_cell_id(one_entity->pos + pos_t(one_entity->radius, one_entity->radius));
for(auto cell_x = low_cell_id.x; cell_x <= high_cell_id.x; cell_x++)
{
for(auto cell_y = low_cell_id.y; cell_y <= high_cell_id.y; cell_y++)
{
cell_id cur_cell_id(cell_x, cell_y);
const auto cur_next = get_hash_cell_node(cur_cell_id)->next;
while(cur_next)
{
if(cur_next->cell_id == cur_cell_id)
{
// 只处理cell_id 相同的
one_entity->calc_aoi(cur_next->entity);
}
cur_next = cur_next->next;
}
}
}
}
}
这里的cell_id引发的hash冲突会带来一些性能损失,因为会遍历到cell_id不一样但是hash一样的aoi_entity。如果所有的hash_cell_node都通过线性内存池来分配的话,缓存局部性又会导致遍历时的性能提升,这样能弥补一些性能损失。
同样由于cell_id的hash冲突,我们要小心的维护grid_world::on_entity_move
void grid_world::on_entity_move(aoi_entity* cur_entity, const pos_t& new_pos)
{
auto pre_cell_id = calc_cell_id(cur_entity->pos);
cur_entity->pos = new_pos;
auto new_cell_id = calc_cell_id(cur_entity->pos);
if(new_cell_id == pre_cell_id)
{
return;
}
auto pre_cell_list = get_hash_cell_node(pre_cell_id);
auto new_cell_list = get_hash_cell_node(new_cell_id);
if(pre_cell_list == new_cell_list)
{
// 列表相同时 只需要修改对应node的cell_id 即可
pre_cell_list = pre_cell_list->next;
while(pre_cell_list)
{
if(pre_cell_list->entity == cur_entity)
{
pre_cell_list->id = new_cell_id;
break;
}
pre_cell_list = pre_cell_list->next;
}
}
else
{
// 当列表不同时 需要从老的列表中摘除原来的node
hash_cell_node* dest_node = nullptr;
while(pre_cell_list->next)
{
if(pre_cell_list->next->entity == cur_entity)
{
dest_node = pre_cell_list->next;
pre_cell_list->next = pre_cell_list->next->next;
break;
}
pre_cell_list = pre_cell_list->next;
}
assert(dest_node);
// 然后再插入到新的列表头部
dest_node->id = new_cell_id;
dest_node->next = new_cell_list->next;
new_cell_list->next = dest_node;
}
}
通过这样的实现,每次更新aoi_entity的位置时,最坏情况下需要遍历两个列表。不过aoi_entity移动时触发cell_id的修改的频率比较低,一般来说其radius一般来说是移动速度的10倍以上,此时触发cell_id修改的频率不到1/10。而且我们给linked_hash_map分配的槽位足够多,在玩家分布稀疏的时候,每个链表中的元素平均来说也是常数个。因此这个位置更新函数带来的开销常规情况下不需要担心,只有在大量玩家聚居在一小块区域不断的跨cell移动时才会触发很大的开销,不过此时update_aoi的开销也会变得很大,相比之下位置更新函数的开销就不怎么需要去在意了。
基于十字链表的AOI计算
前述的暴力遍历AOI计算和网格空间划分AOI计算的核心思想都是在update_aoi函数中,主动的去获取每个aoi_entity相关的其他aoi_entity集合S,暴力遍历AOI计算中S就是当前场景内的所有aoi_entity,网格空间划分AOI计算则利用空间筛选机制显著降低了S的大小。获取了集合S之后,再用calc_aoi函数去遍历S,一一判断是否在aoi_entity->radius范围内,即使参与calc_aoi的两个aoi_entity在上次update_aoi之后都没有移动。在非聚集区域,且aoi_entity的移动频率和速度都不是很大的时候,一定时间内这个集合S是不会变的,同时aoi_entity->interest集合也可以维持一段时间的不变。update_aoi如果利用这种局部常速移动的短期AOI不变性质,可以减少很多不必要的S集合计算以及calc_aoi计算,大大的优化执行效率。针对这种情况,基于十字链表的AOI计算被设计出来。
这里的十字链表其实包含了两个结构一样的有序链表,分别管理坐标的x, y两个轴。链表中的每个节点都有一个附加的坐标,同时链表中的节点按照坐标的升序排列。每个aoi_entity在每个链表中都会有三个节点,以x轴为例, 这三个节点的坐标分别为x - radius, x, x+radius。每个链表都有一个head节点和一个tail节点分别代表链表的头与尾。为了维持链表有序性,head节点的坐标等于场景最小坐标值减去所有aoi_entity的最大radius, 同时tail节点的坐标等于场景最大坐标加上所有aoi_entity的最大radius。下面就是这个十字链表的基本结构体定义:
enum aoi_list_node_type
{
left = 0,
center,
right,
invalid,
};
struct aoi_list_node;
struct aoi_list_entity: aoi_entity
{
std::array<aoi_list_node*, 3> x_nodes; // 0 为left 1为center 2为right
std::array<aoi_list_node*, 3> y_nodes; // 0 为left 1为center 2为right
}
struct aoi_list_node
{
// 这里的比较策略使用 (pos, entity)这个pair来进行比较 即优先比较pos pos相同时比较entity->id
aoi_list_entity* entity = nullptr;
float pos;
aoi_list_node_type type;
aoi_list_node* pre = nullptr;
aoi_list_node* next = nullptr;
};
struct aoi_axis_list
{
aoi_list_node head;
aoi_list_node tail;
void remove_node(aoi_list_node* cur); // 从链表中摘除cur节点
void insert_before(aoi_list_node* cur, aoi_list_node* next); //在next节点之前插入cur节点
}
struct list_world: public world
{
aoi_axis_list x_list;
aoi_axis_list y_list;
};
在这样的结构设计下,整个list_world所需的内存基本就是场景内aoi_entity数量的常数倍,相对于前面的两个算法节省了很多内存。
为了加深对十字链表结构的理解,我们提供图形来介绍。假设场景里有(A,B,C,D)四个aoi_entity以下图的形式存在于场景中:
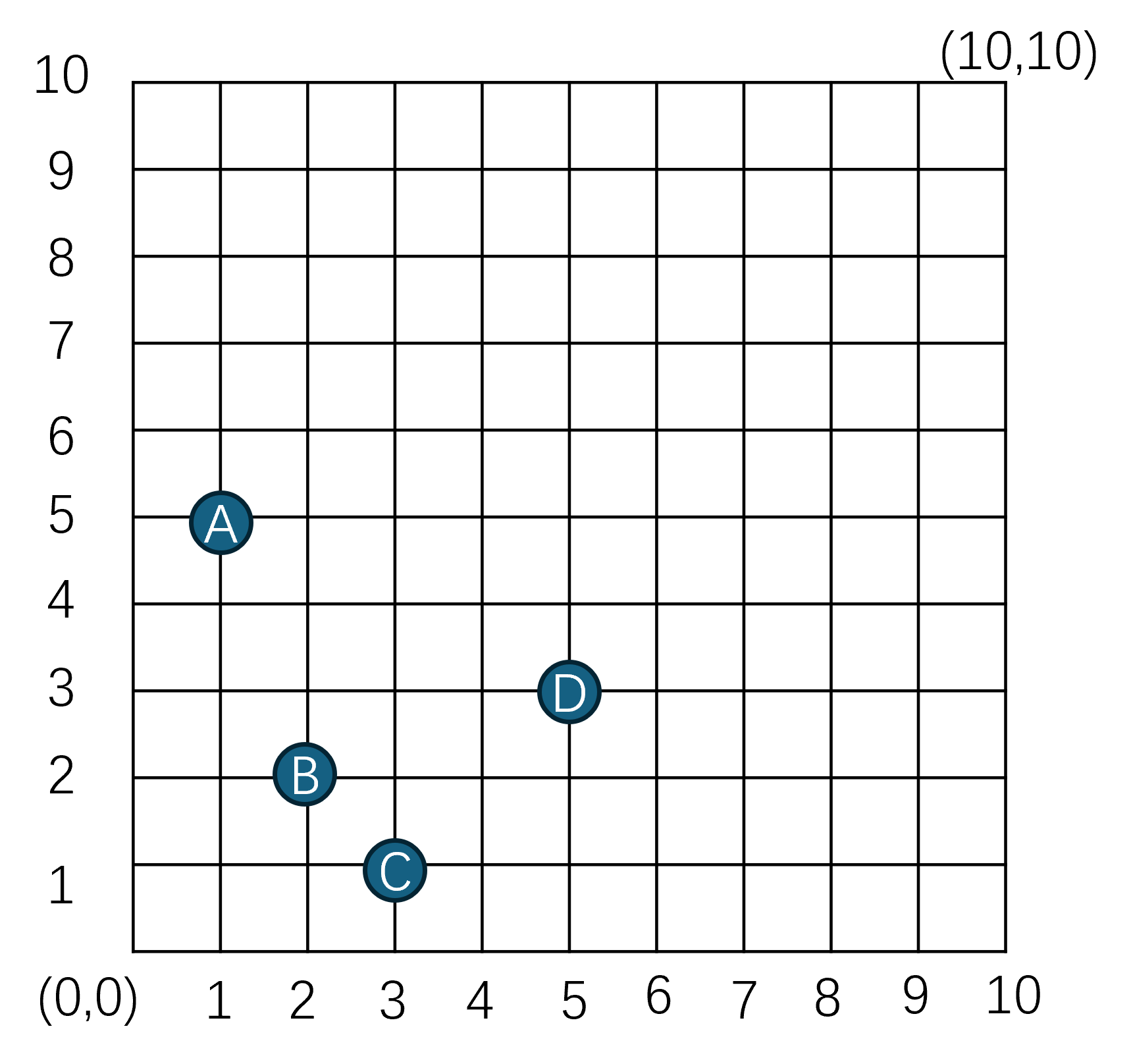
在radius设置为3时,上图场景对应的十字链表里的节点布局如下,图中绿色节点代表aoi_list_node_type::left, 浅蓝色节点代表aoi_list_node_type::center,深蓝色节点代表aoi_list_node_type::right,红色节点代表aoi_list_node_type::invalid,红色节点只提供给head, tail使用:

有了上图所示的十字链表结构之后,一个aoi_list_entity(M)在aoi_list_entity(N)的radius内需要满足两个条件:
M->x_nodes[1]处于(N->x_nodes[0], N->x_nodes[1])区间内M->y_nodes[1]处于(N->y_nodes[0], N->y_nodes[1])区间内
满足上面两个条件后,M处于N的AOI正方形内,如果要求在N的AOI圆内则需要额外的平面距离计算。为了加速计算我们在使用十字链表时不再采用AOI圆形区域,而采用正方形区域。使用正方形AOI区域之后,我们可以以如下的方式计算一个aoi_entity的interest集合:分别在x_list和y_list上扫描这个aoi_list_entity的left节点与right节点之间的所有center节点,收集这些center节点对应的entity,生成x_entities和y_entities两个集合,然后计算两个集合的交集,即为所有在当前aoi_entity内的aoi_entity集合。这样的计算方式依赖于在aoi_axies_list上提供这样的一个scan接口,来获取两个aoi_list_node之间特定type的aoi_list_entity集合:
std::vector<aoi_list_entity*> aoi_axis_list::scan(aoi_list_node* a, aoi_list_node* b, aoi_list_node_type check_type)
{
std::vector<aoi_list_entity*> result;
while(a->next != b)
{
a = a->next;
if(a->type == check_type)
{
result.push_back(a->entity);
}
}
return result;
}
有了这个scan接口后,再配合集合交集接口,就可以很简单的完成单个aoi_entity的AOI的计算:
std::vector<aoi_list_entity*> list_world::set_intersect(const std::vector<aoi_list_entity*>& a, const std::vector<aoi_list_entity*>& b) const
{
std::unordered_set<aoi_list_entity*> temp_set;
for(auto one_entity: a)
{
temp_set.insert(one_entity);
}
std::vector<aoi_list_entity*> result;
for(auto one_entity : b)
{
if(temp_set.count(one_entity) == 1)
{
result.push_back(one_entity);
}
}
return result;
}
void list_world::update_aoi()
{
for(const auto [one_id, one_entity]: aoi_entities)
{
one_entity->clear_invalid();
auto cur_list_entity = reinterpret_cast<aoi_list_entity*>(one_entity);
auto temp_result_x = x_list.scan(cur_list_entity->x_nodes[0], cur_list_entity->x_nodes[2], aoi_list_node_type::center);
auto temp_result_y = y_list.scan(cur_list_entity->y_nodes[0], cur_list_entity->y_nodes[2], aoi_list_node_type::center);
for(auto one_result: set_intersect(temp_result_x, temp_result_y))
{
one_entity->cacl_aoi(one_result);
}
}
}
虽然我们可以这样做来实现update_aoi,但是这样计算的效率相对于网格划分来说太差了,因为现在一个aoi_entity会引入六个aoi_list_node,导致scan的时间消耗会是网格划分里扫描cell的时间消耗的六倍,这里还存在一个计算量比较繁重的set_intersect操作。使用十字链表计算AOI的正确用法是介入到on_entity_move内,在一个aoi_entity(M)移动时,移动其六个aoi_list_node到合适的位置,同时分别对两个aoi_axis_list计算出下面的四个集合:
- 移动后进入
M->radius区域的aoi_entity集合Enter_M - 移动后离开
M->radius区域的aoi_entity集合Leave_M - 移动后
M进入N->radius区域的aoi_entity集合Enter_N - 移动后
M离开N->radius区域的aoi_entity集合Leave_N
aoi_entity在aoi_axis_list往坐标增大的方向移动的流程细节与往坐标缩小的方向移动的流程细节互为镜像,同时每个坐标轴上的处理完全一致,所以为了简化讨论这里只考虑往在x_list上往坐标增大的方向移动。此时上述四个集合可以通过遍历aoi_list_entity在当前轴上的三个x_nodes在从左向右调整位置时遍历到的各种其他aoi_list_node计算出来:
Enter_M为x_nodes[2]在移动时经过的center节点的aoi_list_node->entity集合Leave_M为x_nodes[0]在移动时经过的center节点的aoi_list_node->entity集合Enter_N为x_nodes[1]在移动时经过的left节点的aoi_list_node->entity集合Leave_N为x_nodes[1]在移动时经过的right节点的aoi_list_node->entity集合
为了快速的计算上面的四个集合,我们在aoi_axis_list上增加一个接口move_right,来收集一个节点向右移动时所经过的感兴趣的节点:
struct sweep_result
{
std::vector<aoi_list_entity*> left;
std::vector<aoi_list_entity*> center;
std::vector<aoi_list_entity*> right;
};
enum aoi_list_type_flag
{
left = 1,
center = 2,
right = 4,
};
void aoi_axis_list::move_right(aoi_list_node* cur, sweep_result& visited_nodes, std::uint8_t flag)
{
auto next = cur->next;
// 将cur节点从list中摘除
remove_node(cur);
// 向坐标轴增大的方向遍历 直到找到一个大于当前pos的节点
while(next->pos <= cur->pos)
{
switch (next->type)
{
case aoi_list_node_type::left:
if(flag & std::uint8_t(aoi_list_type_flag::left))
{
visited_nodes.left.push_back(next->entity);
}
break;
case aoi_list_node_type::center:
if(flag & std::uint8_t(aoi_list_type_flag::center))
{
visited_nodes.center.push_back(next->entity);
}
break;
case aoi_list_node_type::right:
if(flag & std::uint8_t(aoi_list_type_flag::right))
{
visited_nodes.right.push_back(next->entity);
}
break;
default:
break;
}
next = next->next;
}
// 在next之前插入cur节点
insert_before(cur, next);
}
有了这个move_right函数之后,上面的四个集合就可以很方便的计算出来了:
void aoi_axis_list::on_move_right(aoi_list_entity* cur_entity, const std::array<aoi_list_node*, 3>& cur_nodes, float diff_pos)
{
sweep_result temp_sweep_result;
cur_nodes[1]->pos += diff_pos;
move_right(cur_nodes[1], temp_sweep_result, (std::uint8_t)aoi_list_type_flag::left + (std::uint8_t)aoi_list_type_flag::right);
Enter_N = temp_sweep_result.left;
Leave_N = temp_sweep_result.right;
cur_nodes[2]->pos += diff_pos;
move_right(cur_nodes[2], temp_sweep_result, (std::uint8_t)aoi_list_type_flag::center);
Enter_M = temp_sweep_result.center;
temp_sweep_result.center.clear();
cur_nodes[0]->pos += diff_pos;
move_right(cur_nodes[0], temp_sweep_result, (std::uint8_t)aoi_list_type_flag::center);
Leave_M = temp_sweep_result.center;
}
由于目前有两个坐标轴,我们对这四个集合分别添加X_, Y_前缀,最终生成了8个集合。由于aoi_entity->interested集合与aoi_entity->interest集合是相互关联的,两者是同时进行插入与删除的,所以这里讨论时只考虑维护好interest集合。接下来我们使用这8个集合来更新aoi_entity->interest集合:
- 计算
X_Enter_M与Y_Enter_M的并集Union_Enter_M,对于Union_Enter_M内的每个aoi_entity(N)都执行一次M->calc_aoi(N),来尝试添加N到M的interest集合中 - 计算
X_Leave_M与Y_Leave_M的并集Union_Leave_M,对于Union_Leave_M内的每个aoi_entity(N)都执行一次M->interest.erase(N->id)来尝试执行删除,如果删除成功则继续执行M->on_aoi_leave(N)回调 - 计算
X_Enter_N与Y_Enter_N的并集Union_Enter_N,对于Union_Enter_N内的每个aoi_entity(N)都执行一次N->calc_aoi(M),来尝试添加M到N的interest集合中 - 计算
X_Leave_N与Y_Leave_N的并集Union_Leave_N,对于Union_Leave_N内的每个aoi_entity(N)都执行一次N->interest.erase(M->id)来尝试执行删除,如果删除成功则继续执行N->on_aoi_leave(M)回调
通过计算上述8个集合即可在on_entity_move时维护好aoi_entity->interest集合,此时list_aoi::update_aoi函数不再需要做任何事情,所以list_aoi的运行效率完全依托于on_entity_move的执行效率。在非瞬移情况下一个aoi_entity在每帧期间移动的位置diff其实是很小的,在非密集聚集的情况下其所有的6个aoi_list_node更新位置时收集的上述8个集合所包含的元素都非常小,如果能够避免计算过程中的各种stl容器内部的动态内存分配,则整体on_entity_move的执行时间基本为一个可控的常数时间。为了达到这个常数时间的需求,我们对上述代码做一些改进:
- 将
on_move_right中的temp_sweep_result从临时变量修改为aoi_axis_list的成员变量,并提前对内部的三个vector做reserve操作,以避免push_back时触发动态内存分配 - 计算集合的交集与并集时,不再使用
unordered_set,而是在aoi_list_entity内增加一个mutable bool变量来标记是否已经在目标集合中了,此时集合的交集与并集可以采取下面的优化实现,这样计算时只会触发一次动态内存分配:
struct aoi_list_entity
{
mutable bool is_in_set = false;
};
std::vector<aoi_list_entity*> list_world::set_intersect(const std::vector<aoi_list_entity*>& a, const std::vector<aoi_list_entity*>& b) const
{
std::vector<aoi_list_entity*> result;
result.reserve(std::min(a.size(), b.size()));
for(auto one_entity: a)
{
one_entity->is_in_set = true;
}
for(auto one_entity : b)
{
if(one_entity->is_in_set)
{
result.push_back(one_entity);
}
}
for(auto one_entity: a)
{
one_entity->is_in_set = false;
}
return result;
}
std::vector<aoi_list_entity*> list_world::set_union(const std::vector<aoi_list_entity*>& a, const std::vector<aoi_list_entity*>& b) const
{
std::vector<aoi_list_entity*> result;
result.reserve(a.size() + b.size());
for(auto one_entity: a)
{
one_entity->is_in_set = true;
result.push_back(one_entity);
}
for(auto one_entity : b)
{
if(!one_entity->is_in_set)
{
result.push_back(one_entity);
}
}
for(auto one_entity: a)
{
one_entity->is_in_set = false;
}
return result;
}
上述优化手段都使用之后,此时即使每个aoi_entity都执行了一次局部移动,其维护on_entity_move的时间相对于网格划分的AOI计算来说也有显著降低。但是对于非局部移动,on_entity_move的执行时间则会显著的增高,最坏情况下如果执行场景的对角线移动,将会执行3次x_list和3次y_list的完整扫描。这种执行时间的不稳定性对于玩家的感官影响是非常恶劣的,为此我们需要对十字链表做一定的修改,在坐标轴上加入一些哨兵节点,来加速这种瞬移过程的处理。
struct aoi_axis_list
{
// anchors[0]保证有效且坐标与head坐标一致
std::vector<aoi_list_node*> anchors;
void on_teleport(aoi_list_entity* cur_entity, const std::array<aoi_list_node*, 3>& cur_nodes)
{
for(auto one_node: cur_nodes)
{
remove_node(one_node);
}
sweep_result temp_sweep_result;
for(auto one_node: cur_nodes)
{
auto temp_iter = std::lower_bound(anchors.begin(), anchors.end(), one_node->pos);
aoi_list_entity* left_anchor = *(temp_iter--);
left_anchor = left_anchor->next;
insert_before(one_node, left_anchor);
// move_right 的第三个参数传0 代表不记录期间遇到的任何节点
move_right(one_node, temp_sweept_result, 0);
}
}
}
在aoi_axis_list中我们用anchors字段存储所有的哨兵节点,按照节点里的pos从小到大排好序,同时我们在运行时保证anchors[0]一定是有效的,且其坐标等同于head节点的坐标,即场景最小坐标值减去所有aoi_entity的最大radius。进行长距离瞬移时,先将当前aoi_list_entity在这个坐标轴上的三个aoi_list_node摘除,然后以二分查找的方式找到第一个pos大于等于 当前entity->pos - radius的节点temp_iter。由于我们保证了head对应的节点一定在anchors的开头 且这个节点的坐标小于任何有效的节点, 所以可以安全的执行temp_iter--操作。执行--操作后temp_iter对应的节点left_anchor坐标一定小于cur_nodes[0]->pos,这样我们按照顺序在left_anchor之前插入cur_nodes,然后再进行向右移动来修正这三个节点即可完成cur_entity的节点更新。如果我们在坐标轴上每K个节点添加一个哨兵,则在包含了N个aoi_entity的坐标轴上的on_teleport的时间为log(N/K) + K,相对于原来的全链表遍历来说时间复杂度远远降低了。而这个anchors数组不需要实时更新,在传送移动不是非常频繁的时候,每分钟更新一次都是可以接受的。
void aoi_axis_list::arrage_anchors() // 这个函数定期执行 在合适的位置插入哨兵
{
for(auto one_anchor: anchors)
{
remove_node(one_anchor);
delete one_anchor;
}
anchors.clear();
int anchor_gap = 30; // 每30个节点插入一个anchor
int temp_counter = anchor_gap; // 这样初始化保证有一个anchor的坐标与head一样
auto next= head.next;
do
{
auto pre = next->pre;
next = next->next;
temp_counter++;
if(temp_counter >= anchor_gap)
{
auto new_anchor = new aoi_list_node;
new_anchor->pos = pre->pos;
new_anchor->type = aoi_list_node_type::invalid;
new_anchor->entity = nullptr;
insert_before(new_anchor, next);
temp_counter = 0;
}
}while(next)
}
上面的更新实现只需要一次全链表遍历,如果在new时复用前面delete的anchor节点,这种复杂度下秒级更新也是可以的。
现在还剩下一个关键的问题,on_teleport维护好三个aoi_list_node之后,如何进一步去维护aoi_entity->interest集合。对于瞬移的aoi_list_entity(M),在其6个aoi_list_node都更新完毕之后,我们利用之前定义的scan函数就可以更新aoi_list_entity(M)->interest集合。然后由于M瞬移导致的aoi_list_entity(N)->interest集合的修改,分如下两步进行:
- 遍历
M->interested内的每个aoi_list_entity(N), 检查M是否还在N的radius范围内,如果不在则从N->interest集合中删除M,并从M->interested中删除N。 - 根据配置好的场景内
list_aoi_entity的最大AOI半径为max_radius,利用anchors在aoi_axis_list上找到包含在[M->pos - max_radius, M->pos + max_radius]区间且覆盖区间最大的节点对(begin_node, end_node),使用scan函数收集其中的type==center的aoi_list_entity集合,对于此集合内的所有aoi_list_entity(N)执行N->calc_aoi(M)
在max_radius与radius相差不大的情况下,上述维护interest集合相关操作的消耗时间基本正比与M->interest.size() + M->interested.size(),在非密集聚集的情况下其执行时间还是可控的。正常的游戏环境下aoi_entity执行局部移动的次数与执行瞬移的次数比值基本都在200以上,所以基于十字链表实现的AOI计算在效率方面相对于网格划分实现的AOI计算有一定的优势。这种优势随着场景内aoi_entity的数量增大而增大,随着每次update_aoi期间参与移动的aoi_entity数量增大而减少。在实际测算中,在一千个aoi_entity的场景中,如果超过1/3的aoi_entity都参与了移动,则基于十字链表的AOI计算不再具有效率优势。