Asio 介绍
Asio是一个建立在Boost所提供的相关组件之上的异步的网络库,可以运行在Win/Linux/Unix等各种平台之上。不过随着C++11的发布,其对于Boost的依赖也越来越少,作者又做了一个不依赖于boost的版本。对于Asio所提供的功能以及整体架构,可以从下图中可窥一斑:
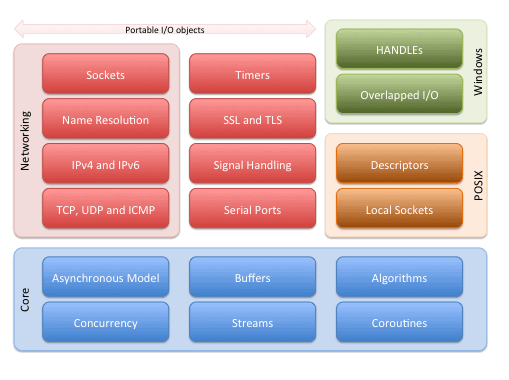
网络IO模型
在W. Richard Stevens 的Unix Network Programming中, 谈到了5种IO模型:
-
阻塞 blocking ,当前线程发出IO请求后阻塞在等待IO就绪,然后再发去数据复制请求,然后再阻塞在等待数据拷贝完成;
-
非阻塞 non-blocking,不停的调用recv_some 或send_some,每次都能progress一点,最后仍然会在data copy这里阻塞在系统调用上;
-
IO多路复用 IO multiplexing,基本类似于blocking,只不过一个线程可以同时处理多个socket的请求,也就是所谓的线程复用了;
-
异步 asynchronouse,线程提交IO请求之后直接返回,系统在执行完IO请求并复制到用户提供的数据区之后再通知完成
-
信号驱动 singal-driven,没啥用,不说了
总的来说,这几种IO模型下,线程的运行状态如下图:

在三个主流的操作系统平台中,都采用了各自的主流IO模型。Windows上采用的的是IOCP,Linux上采用的是Epoll,Unix上采用的是kqueue。Asio通过一个中间层来实现在各个不同的平台上调用不同的底层实现。所以,为了更好的理解Asio,首先需要了解这几种不同的IO多路复用的机制。在此我只对IOCP和Epoll做一些介绍,kqueue因为不熟所以忽略。
IOCP
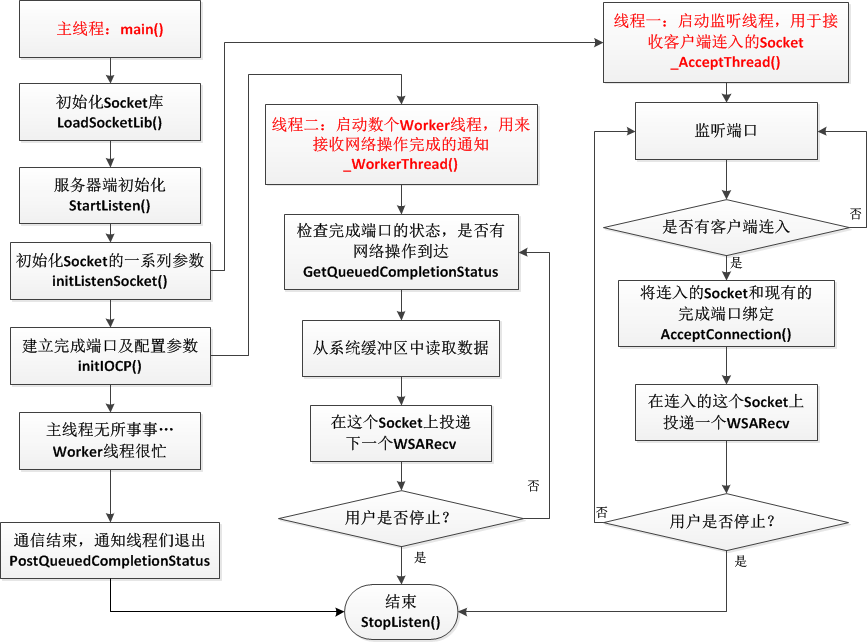
IOCP的全称是IO Completion Port,中文名叫做I/O完成端口。其模型简要来说就是:客户向操作系统提交IO任务,操作系统执行客户所发出的各项IO请求,在完成IO请求之后操作系统将对应的IO任务提交到完成队列中,同时一个线程池不断的监听该完成队列中是否有消息。具体的完成之后的业务逻辑依赖于线程池中的具体代码,系统提供的主要功能是这个完成队列。
在Windows,与IOCP关联最紧密的API主要有三个,分别是CreateIoCompletionPort, GetQueuedCompletionStatus, PostQueueCompeltionStatus。
CreateIoCompletionPort的作用是建立一个IO完成端口,其函数签名如下:
HANDLE CreateIoCompletionPort ( HANDLE FileHandle, // handle to file HANDLE ExistingCompletionPort, // handle to I/O completion port ULONG_PTR CompletionKey, // completion key DWORD NumberOfConcurrentThreads // number of threads to execute concurrently );
这个函数需要注意的是:他同时承担着建立完成端口和将设备绑定到完成端口这两个任务。当这个函数用于建立一个新的完成端口时,其参数调用是这样的:
CreateIoCompletionPort(INVALID_HANDLE_VALUE, nullptr, 0, 0)
这里的INVALID_HANDLE_VALUE的值其实是-1。简而言之呢,如果我们给他的都是一些无效的值,则这个函数会创建一个新的完成端口。最后一个参数是代表的是允许应用程序同时执行的线程数量。需要注意的是,这个参数并不是我们线程池中线程的数量,而是完成端口允许的活动线程的数量。如果设置为0,就是说有多少个处理器,就允许同时多少个线程运行,这样就可以避免频繁的上下文切换。至于真正执行任务的线程池,需要我们自己设置线程数量,folklore说一般设置为2*cpu+2个工作线程。
如果我们想将一个IO设备绑定到现有的完成端口之上,则需要以另外的形式调用CreateIoCompletionPort。当前我们需要处理网络事件,因此需要将socket作为HANDLE和一个完成键(对你有意义的一个32位值,也就是一个指针, 操作系统并不关心你传什么)传进去。
CreateIoCompletionPort(ioHandle, iocp, (ULONG_PTR)fn, 0)
每当你向端口关联一个设备时,系统向该完成端口的设备列表中加入一条信息纪录。
一个函数来做两件事这种设计很不好!
GetQueuedCompletionStatus是用来处理IO完成事件的,其函数签名如下:
BOOL WINAPI GetQueuedCompletionStatus( __in HANDLE CompletionPort, // 这个就是我们建立的那个唯一的完成端口 __out LPDWORD lpNumberOfBytes, //这个是操作完成后返回的字节数 __out PULONG_PTR lpCompletionKey, // 这个是我们建立完成端口的时候绑定的那个自定义结构体参数 __out LPOVERLAPPED *lpOverlapped, // 这个是我们在连入Socket的时候一起建立的那个重叠结构 __in DWORD dwMilliseconds // 等待完成端口的超时时间,如果线程不需要做其他的事情,那就INFINITE就行了 );
GetQueuedCompletionStatus使调用线程挂起,放入到等待线程队列中,直到指定的端口的I/O完成队列中出现了一项或直到超时。
-
当有任务成功时,返回TRUE,dwCompletionKey返回调用CreateIOCompletionPort将I/O设备(比如文件,套接字等等)句柄关联到完成端口时提供的dwCompletionKey参数,lpOverlapped返回异步调用时提供的lpOverlapped参数,nBytesTransferred返回写入或读取的字节数。
-
当没有任务完成,也没有任务出现错误时,返回FALSE。lpOverlapped被设置为nil。调用GetLastError可以得到更详细的原因,如果GetLastError返回WAIT_TIMEOUT,表明超时了,如果是其他错误,可以查MSDN上的系统错误码,了解原因。
-
如果有任务失败了,返回FALSE。dwCompletionKey和lpOverlapped的设置情况跟第一种结果一样。GetLastError返回任务失败的原因。对于Winsock2的WSARecv调用,如果GetLastError返回ERROR_NETNAME_DELETED,表示连接被通讯的另一方复位或者异常中断了,比如对方死机,此时应关闭套接字。对于Winsock2的ConnectEx调用,如果GetLastError返回ERROR_CONNECTION_REFUSED,表示远端主机没有在这一端口进行监听;如果返回ERROR_HOST_UNREACHABLE,表示网络不通。
这里的线程等待队列其实不是一个队列,而是一个栈,后进先出。这样如果反复只有一个I/O操作而不是多个操作完成的话,内核就只需要唤醒同一个线程就可以了,而不需要轮着唤醒多个线程,节约了资源,而且可以把其他长时间睡眠的线程换出内存,提到资源利用率。
PostQueueCompeltionStatus是用来通知完成端口的线程退出的函数,其函数签名如下:
BOOL WINAPI PostQueuedCompletionStatus( __in HANDLE CompletionPort, __in DWORD dwNumberOfBytesTransferred, __in ULONG_PTR dwCompletionKey, __in_opt LPOVERLAPPED lpOverlapped );
这个函数的参数几乎和GetQueuedCompletionStatus()的一模一样,都是需要把我们建立的完成端口传进去,然后后面的三个参数是 传输字节数、结构体参数、重叠结构的指针。可以理解为一个是完成队列的push操作,一个是完成队列的pop操作。我们在push是加上一些标志性的参数,使得工作线程在检查结果时遇到这些参数就直接退出工作。因此,对于每一个工作线程,我们都需要push一次,即调用PostQueuedCompletionStatus一次:
for (int i = 0; i < m_nThreads; i++) { PostQueuedCompletionStatus(m_hIOCompletionPort, 0, (DWORD) NULL, NULL); }
综上,一个使用IOCP的接收服务器的整体工作流程可以以下图概括:
Epoll
在谈到epoll时,不得不谈他的演化史,即select-poll-epoll。这三者都是linux上的多路复用机制,通过监听描述符的就绪态来通知程序进行读写。其工作流程见下图:
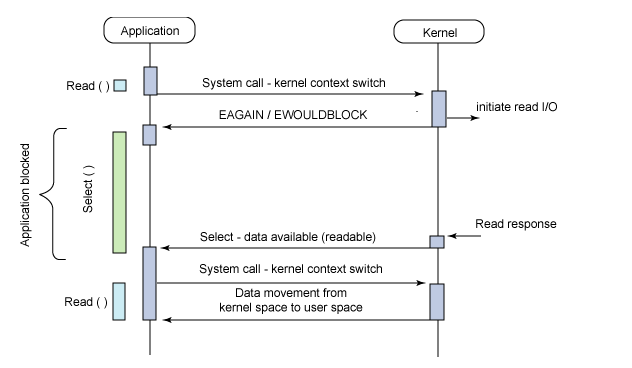
select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的。而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间,正如前面提到的IOCP。
在调用select时,我们需要提供三个fd_set,分别代表可读、可写、可错三个感兴趣的文件描述符列表。调用时我们需要将这些fd_set 考入内核空间,然后对于每个fd都调用其poll方法来查看其是否就绪。如果有就绪的fd则直接返回,否则当前线程休眠直到timeout,timeout唤醒之后再扫描一遍fd_set查看是否有就绪fd,然后直接返回。返回时需要把fd_set从内核拷贝到用户空间中。
poll相对与select的改进就是不再采用三个fd_set,而是采取了一个单独的pollfd来存储所有涉及到的文件描述符以及每个描述符上感兴趣的事件。可以说是拷贝的数据量减少了,但是select所拥有的缺点poll仍然完美的继承了下来:
-
每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大;
-
同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大;
-
select支持的文件描述符数量太小了,默认是1024。
而epoll的改进则更彻底一些,他提供了三个函数epoll_create,epoll_ctl,epoll_wait。epoll_create是创建一个epoll句柄;epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。在具体的执行机制上,epoll做了如下改进:
-
每次注册新的事件到epoll句柄中时(在
epoll_ctl中指定EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。 -
epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,而只在
epoll_ctl时把current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调函数,而这个回调函数会把就绪的fd加入一个就绪链表)。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd(利用schedule_timeout()实现睡一会,判断一会的效果。 -
epoll所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,具体数目可以
cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
Asio 异步模型
Asio使用的是Proactor(前摄器)模型,其模型图见下:
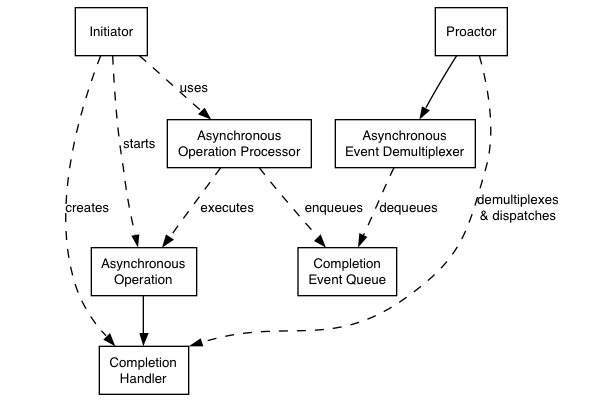
这里需要解释一下各个部分代表着什么:
-
Asynchronous Operation:异步操作,调用后直接返回,不阻塞;
-
Asynchronous Operation Processor:异步操作执行单元,用来执行异步操作,异步操作执行完成之后将对应的完成事件放入完成事件队列
-
Completion Event Queue:存储完成事件的队列
-
Asynchronous Event Demultiplexer:异步事件多路复用单元,等待Completion Event Queue出现完成事件,然后返回一个完成事件
-
Proactor:调用异步事件多路复用单元来获得一个完成事件,然后分发这个完成事件所关联的完成操作句柄(回调函数)到具体的执行单元中
-
Initiator:初始化器,用来提供初始的异步操作。
在windows上,这个模型很容易的就可以映射到IOCP之上:
-
asynchrounous Operation Processor:这个是系统自己处理,我们直接将异步操作映射到操作系统自带的异步api即可委托给操作系统执行;
-
completion Event Queue: 这个完成事件队列也是由windows自己管理好了,我们只需要用GetQueuedCompletionStatus即可获得一个完成事件;
-
Asynchronous Event Demultiplexer:这部分是由Asio调用GetQueuedCompletionStatus来获得完成事件以及相应的完成操作句柄。
而在Linux/Unix上情况则不同了,因为这两个平台系统所提供的操作是同步的,其模型是Reactor模型,只能通知IO操作是否可以开始进行,而不能通知IO操作的完成。所以,Asio需要进行如下处理:
-
Asynchronous Operation Processor: 当通过select/epoll/kqueue实现的reactorr通知某项IO操作可以进行时,这个processor执行这个异步操作,然后将完成事件和完成操作挂在到完成事件队列上;
-
Completion Event Queue : 一个以链表形式存在的完成操作句柄队列;
-
Asynchronous Event DemultiPlexer:这个是由Asio实现的一个等待机制,主要是通过条件变量来进行等待
io service
在Asio中,最重要的类就是io_service类,继承自nocopyable。这个类是一个接口类,主要提供了下面的几个操作:
-
run
-
poll
-
stop
-
dispatch
-
post
同时这个类只有三个成员:
private: #if defined(BOOST_ASIO_WINDOWS) || defined(__CYGWIN__) detail::winsock_init<> init_; #elif defined(__sun) || defined(__QNX__) || defined(__hpux) || defined(_AIX) \ || defined(__osf__) detail::signal_init<> init_; #endif // The service registry. boost::asio::detail::service_registry* service_registry_; // The implementation. impl_type& impl_;
而这些操作最后都会委托到io_service 内的成员impl_type& impl去执行,也就是说采取的是pimpl模式。至于这个impl_type,是io_service所定义的一个类型别名:
typedef detail::io_service_impl impl_type;
他的具体类型是与平台相关的:
namespace detail { #if defined(BOOST_ASIO_HAS_IOCP) typedef class win_iocp_io_service io_service_impl; class win_iocp_overlapped_ptr; #else typedef class task_io_service io_service_impl; #endif class service_registry; } //
至于init_成员,是用来做各个平台的各项网络初始化和销毁工作的,简单来说就是一个RAII类型。
而关于service_registry_类型,则没有那么简单了,首先我们看一下io_service的构造函数里这个成员是怎么使用的
io_service::io_service() : service_registry_(new boost::asio::detail::service_registry( *this, static_cast<impl_type*>(0), (std::numeric_limits<std::size_t>::max)())), impl_(service_registry_->first_service<impl_type>()) { }
这里的static_cast<impl_type*>(0)只是为了参数类型推导用的。通过分析service_registery的实现,可以看出他世纪只能就是一个管理service的链表,impl_type也是一个service类型。每种service都有一个唯一id。在调用 use_service
对于不同的操作我们有不同的对应的service子类,所以加入某个特定的service的最佳时机便是对应操作的启动者的构造期,具体代码见下:
explicit basic_io_object(boost::asio::io_service& io_service) : service(boost::asio::use_service<IoObjectService>(io_service)) { service.construct(implementation); }
在构造过程中,使用use_service的返回值来初始化该service成员;我们知道,use_service会在io_service所维护的service链表中查找该类型,如果没有,就创建一个新的service实例;在此,就可以确保resolve_service<tcp>的实例已经被创建出来了,该服务就可以工作了。
这里还需要提到的一点是:resolver自己会创建一个IOCP,因为windows并没有提供resolver的重叠IO操作,这个resolver还会创建自己的线程来执行。但是会回调两次,一次是在resolver的线程中,其回调操作就是把结果发送到主线程的IOCP之中去,在主线程之中取出之后才会调用用户提供的回调函数。
io objects
这里的io objects是承载具体IO功能的对象,常见的有acceptor/resolver/timer/socket等。在Asio中主要的io object的关系图如下:
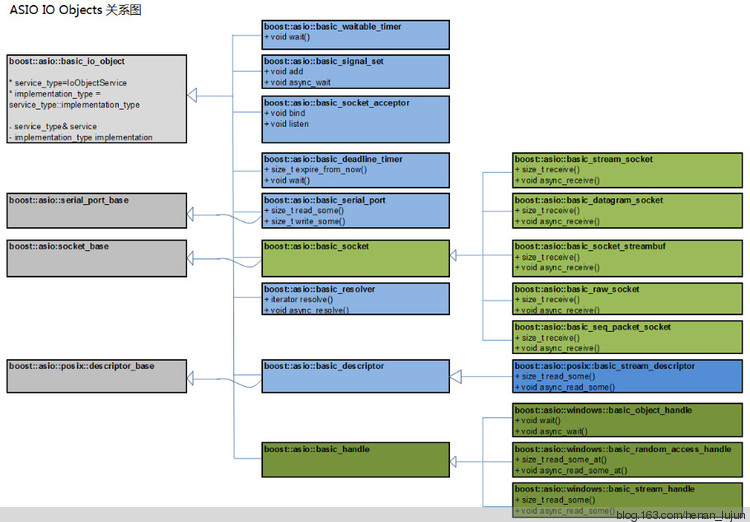 具体的类型及其功能包括:
具体的类型及其功能包括:
-
basic_deadline_timer提供定时器功能,可以同步等待,也可以异步等待。 -
basic_waitable_timer和basic_deadline_timer具有同样的功能,主要区别为该定时器可以和C++ 11中引入的chrono库协作。 -
basic_signal_set支持信号相关的操作,异步方式等待单个或者多个信号的发生。 -
basic_socket_acceptor作为服务器进行侦听,接收连接请求。 -
basic_serial_port对串口操作进行支持。 -
basic_resolver地址解析类。 -
basic_stream_socket提供同步、异步方式的基于流的socket操作。 -
basic_datagram_socket提供同步、异步方式的基于数据报文的socket操作。 -
basic_raw_socket提供同步、异步方式的基于raw数据的socket操作 -
basic_seq_packet_socket提供同步、异步方式的基于有序包的socket操作 -
basic_socket_streambuf? -
basic_object_handle对windows handle的封装,可以以异步或者同步方式等待 -
basic_random_access_handle对windows 可随机访问的handle的封装,可以以异步或者同步方式等待 -
basic_stream_handle对windows面向流handle的封装,可以以异步或者同步方式等待 -
basic_descriptor对POSIX描述符进行封装。
最重要的一点:所有这些io object的构造函数,都要求有一个io_service& 作为参数,使用这一参数,这些io_object对象知道了自己的归属,之后自己所要派发出去的同步、异步操作请求,都将通过自己所在的这个io_service对象来完成。这也就说明了,为什么创建io_service对象是整个Asio程序的第一步。
在使用时,我们并不直接使用这些basic 模板,而是使用这些basic模板的特化类型的别名,例如resolver
typedef basic_resolver<tcp> resolver;
这个用法在stl中很常见,例如cout/cin/string等都是一些basic模板的特化别名。
事实上,这些basic模板所做的也只是作为一些接口类,其具体任务都会被层层转接到asio::detail::service上。以resolver为例,当我们调用async_resolve时,会继续调用下一层的service
template <typename ResolveHandler> void async_resolve(const query& q, BOOST_ASIO_MOVE_ARG(ResolveHandler) handler) { // If you get an error on the following line it means that your handler does // not meet the documented type requirements for a ResolveHandler. BOOST_ASIO_RESOLVE_HANDLER_CHECK( ResolveHandler, handler, iterator) type_check; return this->service.async_resolve(this->implementation, q, BOOST_ASIO_MOVE_CAST(ResolveHandler)(handler)); }
这里的this->service 的类型是asio::ip::resolver_service,然而asio::ip::resolver_service并不算真正的执行者,他下面还有一层:
/// Asynchronously resolve a query to a list of entries. template <typename ResolveHandler> BOOST_ASIO_INITFN_RESULT_TYPE(ResolveHandler, void (boost::system::error_code, iterator_type)) async_resolve(implementation_type& impl, const query_type& query, BOOST_ASIO_MOVE_ARG(ResolveHandler) handler) { boost::asio::detail::async_result_init< ResolveHandler, void (boost::system::error_code, iterator_type)> init( BOOST_ASIO_MOVE_CAST(ResolveHandler)(handler)); service_impl_.async_resolve(impl, query, init.handler); return init.result.get(); }
然而,这里并不是终点,可以看出这里还有一层。这里的service_impl_的类型是service_impl_type,由这个类型名可以看出这个类型又是由宏定义的typedef,其真实类型是:
#if defined(BOOST_ASIO_WINDOWS_RUNTIME) typedef boost::asio::detail::winrt_resolver_service<InternetProtocol> service_impl_type; #else typedef boost::asio::detail::resolver_service<InternetProtocol> service_impl_type; #endif
这样我们继续跟踪boost::asio::detail::resolver_service<InternetProtocol>的async_resolve
// Asynchronously resolve a query to a list of entries. template <typename Handler> void async_resolve(implementation_type& impl, const query_type& query, Handler& handler) { // Allocate and construct an operation to wrap the handler. typedef resolve_op<Protocol, Handler> op; typename op::ptr p = { boost::asio::detail::addressof(handler), boost_asio_handler_alloc_helpers::allocate( sizeof(op), handler), 0 }; p.p = new (p.v) op(impl, query, io_service_impl_, handler); BOOST_ASIO_HANDLER_CREATION((p.p, "resolver", &impl, "async_resolve")); start_resolve_op(p.p); p.v = p.p = 0; }
这里的op是一个临时封装类,执行的时候最终还是由start_resolve_op:
void resolver_service_base::start_resolve_op(operation* op) { start_work_thread(); io_service_impl_.work_started(); work_io_service_impl_.post_immediate_completion(op, false); }
前两个操作都是one shot 的执行,即如果之前的操作已经启动了thread和work的话,则相当于什么都没干。所以最终是post这个op到io_service上了。
Operation
在前面的resolver分析中,我们知道了最后的执行者是Operation,但是Operation最后是怎么与io_service服务的并没有说明。我们先来看Operation的类型定义:
namespace boost { namespace asio { namespace detail { #if defined(BOOST_ASIO_HAS_IOCP) typedef win_iocp_operation operation; #else typedef task_io_service_operation operation; #endif } // namespace detail } // namespace asio } // namespace boost
想必大家都已经开始呵呵了吧,在Asio里面要习惯这种事情啊。简单来说,在IOCP平台下,Operation的类型是win_iocp_operation;而在linux/unix平台下,Operation的类型是task_io_service_operation。
在Asio中,主要有如下的一些operation类型,这里标红色的是与IOCP有关的,白色的是与select/epoll/kqueue有关的。

windows IO Operation
在win_iocp_operation中,主要的内部函数及数据成员有如下几个:
void complete(win_iocp_io_service& owner, const boost::system::error_code& ec, std::size_t bytes_transferred) { func_(&owner, this, ec, bytes_transferred); } void destroy() { func_(0, this, boost::system::error_code(), 0); } typedef void (*func_type)( win_iocp_io_service*, win_iocp_operation*, const boost::system::error_code&, std::size_t); win_iocp_operation(func_type func) : next_(0), func_(func) { reset(); } win_iocp_operation* next_; func_type func_;
从这几个核心成员可以看出,整个win_iocp_operation是一个侵入式的链表,封装了一个func_。从这个func_的类型签名就可以看出这非常像我们使用Asio时的回调函数,但又有一些区别。这个func_的初始化是在win_iocp_operation的各个子类的构造函数中进行的,同样以resolver_op为例:
resolve_op(socket_ops::weak_cancel_token_type cancel_token, const query_type& query, io_service_impl& ios, Handler& handler) : operation(&resolve_op::do_complete), cancel_token_(cancel_token), query_(query), io_service_impl_(ios), handler_(BOOST_ASIO_MOVE_CAST(Handler)(handler)), addrinfo_(0) { }
这里的构造函数使用了自身的resolve_op::do_complete来初始化func_,其他类型的operation也会定义一个do_complete来初始化func_。也就是说,func_其实等价于一个虚函数,我们可以直接将其替换为virtual do_complete=0之类的函数声明,这样构造的时候就不再需要去赋值了。
将其修改为虚函数的解决方案看上去很美,但是这里我们忽略了一点,事实上win_iocp_operation是继承自OVERLAPPED这个类的:
class win_iocp_operation : public OVERLAPPED
至于OVERLAPPED,之前谈及IOCP时也间接提到了,在GetQueuedCompletionStatus的签名中的第四个参数就是这个结构。该结构是Win32进行交叠IO一个非常重要的结构,用以异步执行过程中的参数传递。如果我们将func_更改为虚函数do_complete的话,win_iocp_operation的地址则不再是OVERLAPPED的地址,中间还差一个虚函数表的指针,改变了POD的内存布局。这样使得传参时必须使用dynamic_cast,这样有损效率,而且容易出错。所以Asio这里回避了虚函数这个monster,而是手动初始化func_。还需要注意一点,子类中的do_complete都是声明为静态函数的,这样才能与func的类型匹配。
static void do_complete(io_service_impl* owner, operation* base, const boost::system::error_code& /*ec*/, std::size_t /*bytes_transferred*/)
如果不是声明为static的话,则需要修改func的类型从函数指针到成员函数指针去,同时子类在构造的时候还需要使用reinteprete_cast将son::*转换为father::*。这样使用起来非常不优雅,所以最后选择了static这种机制。
至于operation具体做了什么,我们以recieve操作为例来讲解。在win_iocp_socket_service_base中,为了启动一个receive的异步操作, start_receive_op函数就直接把传递进来的operation指针作为OVERLAPPED结构传递给::WSARecv函数,从而发起一个异步服务请求。
void win_iocp_socket_service_base::start_receive_op( win_iocp_socket_service_base::base_implementation_type& impl, WSABUF* buffers, std::size_t buffer_count, socket_base::message_flags flags, bool noop, operation* op) { update_cancellation_thread_id(impl); iocp_service_.work_started(); if (noop) iocp_service_.on_completion(op); else if (!is_open(impl)) iocp_service_.on_completion(op, boost::asio::error::bad_descriptor); else { DWORD bytes_transferred = 0; DWORD recv_flags = flags; int result = ::WSARecv(impl.socket_, buffers, static_cast<DWORD>(buffer_count), &bytes_transferred, &recv_flags, op, 0); DWORD last_error = ::WSAGetLastError(); if (last_error == ERROR_NETNAME_DELETED) last_error = WSAECONNRESET; else if (last_error == ERROR_PORT_UNREACHABLE) last_error = WSAECONNREFUSED; if (result != 0 && last_error != WSA_IO_PENDING) iocp_service_.on_completion(op, last_error, bytes_transferred); else iocp_service_.on_pending(op); } }
这个函数做了一系列的错误判断之后,之后才通过on_pending操作把op挂在在完成端口上:
void win_iocp_io_service::on_pending(win_iocp_operation* op) { if (::InterlockedCompareExchange(&op->ready_, 1, 0) == 1) { // Enqueue the operation on the I/O completion port. if (!::PostQueuedCompletionStatus(iocp_.handle, 0, overlapped_contains_result, op)) { // Out of resources. Put on completed queue instead. mutex::scoped_lock lock(dispatch_mutex_); completed_ops_.push(op); ::InterlockedExchange(&dispatch_required_, 1); } } }
当然,如果挂在不成功的话(系统忙时可能出现),我们就暂时存储这个op在一个备用队列上completed_ops_。
除了recieve_op,还有很多其他类型的op。各个op与async函数的对应关系见下表

Linux IO Operation
这里我们先来看一下回调函数的封装类,也就是operation对应的类,这个是放在task_io_service_operation中的。
class task_io_service_operation BOOST_ASIO_INHERIT_TRACKED_HANDLER { public: void complete(task_io_service& owner, const boost::system::error_code& ec, std::size_t bytes_transferred) { func_(&owner, this, ec, bytes_transferred); } void destroy() { func_(0, this, boost::system::error_code(), 0); } protected: typedef void (*func_type)(task_io_service*, task_io_service_operation*, const boost::system::error_code&, std::size_t); task_io_service_operation(func_type func) : next_(0), func_(func), task_result_(0) { } // Prevents deletion through this type. ~task_io_service_operation() { } private: friend class op_queue_access; task_io_service_operation* next_; func_type func_; protected: friend class task_io_service; unsigned int task_result_; // Passed into bytes transferred. };
其实这个类看上去与operation类差不多,内部也包含了一个func_type的回调函数,也是使用子类的静态函数来做初始化的,也有一个next指针构造了一个侵入性链表。只不过不再继承自OVERLAPD结构体。这样,我们就定义了一个CompletionHandle。
这个类型只是参与管理回调的,我们还需要记录真正的IO操作是什么,执行IO然后再进行回调。同时记录了IO与Completion Handle的类型是descriptor_state,首先查看descriptor_state的类型定义:
class descriptor_state : operation { friend class epoll_reactor; friend class object_pool_access; descriptor_state* next_; descriptor_state* prev_; mutex mutex_; epoll_reactor* reactor_; int descriptor_; uint32_t registered_events_; op_queue<reactor_op> op_queue_[max_ops]; bool shutdown_; BOOST_ASIO_DECL descriptor_state(); void set_ready_events(uint32_t events) { task_result_ = events; } BOOST_ASIO_DECL operation* perform_io(uint32_t events); BOOST_ASIO_DECL static void do_complete( io_service_impl* owner, operation* base, const boost::system::error_code& ec, std::size_t bytes_transferred); };
这个类型继承自operation,而do_complete与之前我们提到的回调很像,同样的签名同样是static的,都是在构造函数中被传入operation之中。
epoll_reactor::descriptor_state::descriptor_state() : operation(&epoll_reactor::descriptor_state::do_complete) { } void epoll_reactor::descriptor_state::do_complete( io_service_impl* owner, operation* base, const boost::system::error_code& ec, std::size_t bytes_transferred) { if (owner) { descriptor_state* descriptor_data = static_cast<descriptor_state*>(base); uint32_t events = static_cast<uint32_t>(bytes_transferred); if (operation* op = descriptor_data->perform_io(events)) { op->complete(*owner, ec, 0); } } }
这里的perform_io函数便是执行这项工作的:
operation* epoll_reactor::descriptor_state::perform_io(uint32_t events) { mutex_.lock(); perform_io_cleanup_on_block_exit io_cleanup(reactor_); mutex::scoped_lock descriptor_lock(mutex_, mutex::scoped_lock::adopt_lock); // Exception operations must be processed first to ensure that any // out-of-band data is read before normal data. static const int flag[max_ops] = { EPOLLIN, EPOLLOUT, EPOLLPRI }; for (int j = max_ops - 1; j >= 0; --j) { if (events & (flag[j] | EPOLLERR | EPOLLHUP)) { while (reactor_op* op = op_queue_[j].front()) { if (op->perform()) { op_queue_[j].pop(); io_cleanup.ops_.push(op); } else break; } } } // The first operation will be returned for completion now. The others will // be posted for later by the io_cleanup object's destructor. io_cleanup.first_op_ = io_cleanup.ops_.front(); io_cleanup.ops_.pop(); return io_cleanup.first_op_; }
这里的流程就是首先处理异常事件,这里的EPOLLERR和EPOLLDHUP好像都是处理异常断线的。然后开始处理存储在op_queue_中的IO任务,分别是如下几种:
enum op_types { read_op = 0, write_op = 1, connect_op = 1, except_op = 2, max_ops = 3 };
这三个队列的初始化到没有看见,估计都放在async之类操作里建立各种子类型然后初始化了。这个reactor_op的类型定义如下:
class reactor_op : public operation { public: // The error code to be passed to the completion handler. boost::system::error_code ec_; // The number of bytes transferred, to be passed to the completion handler. std::size_t bytes_transferred_; // Perform the operation. Returns true if it is finished. bool perform() { return perform_func_(this); } protected: typedef bool (*perform_func_type)(reactor_op*); reactor_op(perform_func_type perform_func, func_type complete_func) : operation(complete_func), bytes_transferred_(0), perform_func_(perform_func) { } private: perform_func_type perform_func_; };
这里的完成函数是放在operation里的,而io函数是放在自身的数据成员之中。
每次执行完IO之后,把对应的回调operation放入一个完成队列之中,等待进一步处理。
strand
这个strand类型的用途是用来序列化执行流的。在Asio中,由于回调函数是由线程池分发执行的,所以多个回调函数可能在不同的线程中操作一些公共的数据成员,例如共用标准输出导致输出错乱,这就引入了多线程同步的问题。要解决这种多线程同步的问题一般是使用同步原语,例如mutex和cond_var等。但是这些都是比较低级的原语,很容易用错,而我们所要求的仅仅是不可同时执行而已。所以Asio中引入了strand这个类型,来串行化回调函数的执行。
如果要使用strand,我们首先需要声明一个strand类型的对象,然后通过strand.wrap将回调函数包裹起来:
boost::asio::io_service::strand strand_(&io); //注意io_service对象地址作为他的参数。 timer1_.async_wait(strand_.wrap(boost::bind(&printer::print1, this))); timer2_.async_wait(strand_.wrap(boost::bind(&printer::print2, this)));
这里的wrap会生成一个wrapped_handler对象:
template <typename Handler> #if defined(GENERATING_DOCUMENTATION) unspecified #else detail::wrapped_handler<strand, Handler, detail::is_continuation_if_running> #endif wrap(Handler handler) { return detail::wrapped_handler<io_service::strand, Handler, detail::is_continuation_if_running>(*this, handler); }
而这个wrapped_handler的主要内容见下:
wrapped_handler(Dispatcher dispatcher, Handler& handler) : dispatcher_(dispatcher), handler_(BOOST_ASIO_MOVE_CAST(Handler)(handler)) { } void operator()() { dispatcher_.dispatch(BOOST_ASIO_MOVE_CAST(Handler)(handler_)); }
所以到头来还是调用了strand.dispatch函数:
template <typename CompletionHandler> BOOST_ASIO_INITFN_RESULT_TYPE(CompletionHandler, void ()) dispatch(BOOST_ASIO_MOVE_ARG(CompletionHandler) handler) { // If you get an error on the following line it means that your handler does // not meet the documented type requirements for a CompletionHandler. BOOST_ASIO_COMPLETION_HANDLER_CHECK(CompletionHandler, handler) type_check; detail::async_result_init< CompletionHandler, void ()> init( BOOST_ASIO_MOVE_CAST(CompletionHandler)(handler)); service_.dispatch(impl_, init.handler); return init.result.get(); }
这里又根据pimpl模式转接到了boost::asio::detail::strand_service上,这个strand_service里面有一个io_service的引用,但是实际任务还是根据pimpl规则放在strand_impl之中。这个类才真正承载了互斥操作:
class strand_impl : public operation { public: strand_impl(); private: // Only this service will have access to the internal values. friend class strand_service; friend struct on_do_complete_exit; friend struct on_dispatch_exit; // Mutex to protect access to internal data. boost::asio::detail::mutex mutex_; // Indicates whether the strand is currently "locked" by a handler. This // means that there is a handler upcall in progress, or that the strand // itself has been scheduled in order to invoke some pending handlers. bool locked_; // The handlers that are waiting on the strand but should not be run until // after the next time the strand is scheduled. This queue must only be // modified while the mutex is locked. op_queue<operation> waiting_queue_; // The handlers that are ready to be run. Logically speaking, these are the // handlers that hold the strand's lock. The ready queue is only modified // from within the strand and so may be accessed without locking the mutex. op_queue<operation> ready_queue_; };
继承了operation,同时还有mutex,就是他了!这个mutex_就是用来保护队列用的,而waiting_queue则是所有的等待执行的回调队列,ready_queue_则是可以执行的回调。而locked_则是表明这个strand里面是否已经有函数在执行。
而执行操作仍然把持在strand_service中:
template <typename Handler> void strand_service::dispatch(strand_service::implementation_type& impl, Handler& handler) { // If we are already in the strand then the handler can run immediately. if (call_stack<strand_impl>::contains(impl)) { fenced_block b(fenced_block::full); boost_asio_handler_invoke_helpers::invoke(handler, handler); return; } // Allocate and construct an operation to wrap the handler. typedef completion_handler<Handler> op; typename op::ptr p = { boost::asio::detail::addressof(handler), boost_asio_handler_alloc_helpers::allocate( sizeof(op), handler), 0 }; p.p = new (p.v) op(handler); BOOST_ASIO_HANDLER_CREATION((p.p, "strand", impl, "dispatch")); bool dispatch_immediately = do_dispatch(impl, p.p); operation* o = p.p; p.v = p.p = 0; if (dispatch_immediately) { // Indicate that this strand is executing on the current thread. call_stack<strand_impl>::context ctx(impl); // Ensure the next handler, if any, is scheduled on block exit. on_dispatch_exit on_exit = { &io_service_, impl }; (void)on_exit; completion_handler<Handler>::do_complete( &io_service_, o, boost::system::error_code(), 0); } }
这里的执行流程是:首先判断当前线程是否已经在执行strand所包裹的函数。如果是的话,则说明当前函数是在strand内部被调用的,可以理解为尾递归。此时我们的句柄可以直接执行,类似于递归锁的机制。
否则我们就调用do_dispatch:
bool strand_service::do_dispatch(implementation_type& impl, operation* op) { // If we are running inside the io_service, and no other handler already // holds the strand lock, then the handler can run immediately. bool can_dispatch = io_service_.can_dispatch(); impl->mutex_.lock(); if (can_dispatch && !impl->locked_) { // Immediate invocation is allowed. impl->locked_ = true; impl->mutex_.unlock(); return true; } if (impl->locked_) { // Some other handler already holds the strand lock. Enqueue for later. impl->waiting_queue_.push(op); impl->mutex_.unlock(); } else { // The handler is acquiring the strand lock and so is responsible for // scheduling the strand. impl->locked_ = true; impl->mutex_.unlock(); impl->ready_queue_.push(op); io_service_.post_immediate_completion(impl, false); } return false; }
这里才开始利用之前的mutex和locked_。另外还有一个标志位是can_dispatch,这个变量的值表示当前线程是否是io_service开的线程。如果不是io_service的运行线程则我们不能执行这个操作。话说这种情况好诡异。
然后获取队列锁,如果此时strand中没有函数在执行且当前线程可以调度的话,则我们直接返回true,让调用方直接执行op。执行完成之后会有一个RAII类on_dispatch_exit来将locked_设置为false。
struct strand_service::on_dispatch_exit { io_service_impl* io_service_; strand_impl* impl_; ~on_dispatch_exit() { impl_->mutex_.lock(); impl_->ready_queue_.push(impl_->waiting_queue_); bool more_handlers = impl_->locked_ = !impl_->ready_queue_.empty(); impl_->mutex_.unlock(); if (more_handlers) io_service_->post_immediate_completion(impl_, false); } };
饿,好像跟我设想的不太一样啊,执行完成之后直接把等待队列的全扔进就绪队列,如果最后的就绪队列里面还有任务,则当前线程不停的执行这些任务。这样的设计简直机智啊。
如果其他的线程正在执行当前strand中的一个函数,则将当前函数放入等待队列;否则放在就绪队列,并将此impl放入完成事件中进行等待。
Asio 实现概览
总的来说,这些io object 都算 initiator的范畴,启动一个异步操作之后,转接相应的服务类最后到具体的平台相关的xxx_service_impl post 对应的op到io_service上。
因此Asio的总体体系结构可以分为3层:io object 层,basic 模板层和服务层。
-
io object 层,作为应用程序直接使用的对象,是各种basic模板类的typedef实例类型;
-
basic 模板类层,提供对外操作的接口,并把具体操作转发给服务层;
-
服务层,提供具体操作的底层实现,又可分为操作转接层和平台实现层。
通过对Asio中主要对象类型的交互,我们可以推断出整个异步操作的执行流程就是:
-
建立
io_service,并在此io_service之上建立一些io objects -
通过
io objects调用异步操作,例如async_connect; -
通过多层的service转接,最后生成对应的operation,并把完成handle托付给这个operation;
-
发起异步操作,并将operation对象传递给平台实现相关的service,最后调用平台原生操作;
-
操作系统接受IO请求,执行IO操作;
-
IOCP是等待异步等待操作完成,其他平台是等待
IO可以进行; -
等待条件满足之后,执行下一个函数,IOCP是回调函数,非IOCP是真正的IO函数之后串联回调函数;
win io service 实现
在windows平台上,IOCP已经提供了很多异步操作的功能,所以相对来说 win_iocp_io_service比 task_io_service简单点,所以我们先来分析win_iocp_io_service的实现。
根据我们在之前对IOCP的分析,IOCP的使用流程可以分为如下几个步骤:
-
使用Win函数CreateIoCompletionPort()创建一个完成端口对象;
-
创建一个IO对象,如用于listen的socket对象,并通过CreateIoCompletionPort()函数将创建的对象绑定到第一步中的完成端口中。
-
创建一个线程或者线程池,用以服务完成端口事件;所有这些线程调用GetQueuedCompletionStatus()函数等待一个完成端口事件的到来;
-
IO对象进行异步调用,例如WSASend()等操作。
-
在系统执行完异步操作并把事件投递到端口上,或者客户自己调用了PostQueuedCompletionStatus()函数,使得在完成端口上等待的一个线程苏醒,执行后续的服务操作。
现在我们去Asio中寻找执行这些流程的具体代码。首先我们来看完成端口的创建,这个是在win_iocp_io_service的构造函数中调用的:
win_iocp_io_service::win_iocp_io_service( boost::asio::io_service& io_service, size_t concurrency_hint) : boost::asio::detail::service_base<win_iocp_io_service>(io_service), iocp_(), outstanding_work_(0), stopped_(0), stop_event_posted_(0), shutdown_(0), gqcs_timeout_(get_gqcs_timeout()), dispatch_required_(0) { BOOST_ASIO_HANDLER_TRACKING_INIT; iocp_.handle = ::CreateIoCompletionPort(INVALID_HANDLE_VALUE, 0, 0, static_cast<DWORD>(concurrency_hint < DWORD(~0) ? concurrency_hint : DWORD(~0))); if (!iocp_.handle) { DWORD last_error = ::GetLastError(); boost::system::error_code ec(last_error, boost::asio::error::get_system_category()); boost::asio::detail::throw_error(ec, "iocp"); } }
这里的iocp_是一个RAII类型,封装了完成端口的析构操作:
struct auto_handle { HANDLE handle; auto_handle() : handle(0) {} ~auto_handle() { if (handle) ::CloseHandle(handle); } }; // The IO completion port used for queueing operations. auto_handle iocp_;
因此,每一个io_service都会对应着一个完成端口。
现在我们来考虑完成端口的绑定问题。在创建io objects时,我们需要把这些对象绑定到完成端口之上,这里win_iocp_io_service提供了绑定服务:
boost::system::error_code win_iocp_io_service::register_handle( HANDLE handle, boost::system::error_code& ec) { if (::CreateIoCompletionPort(handle, iocp_.handle, 0, 0) == 0) { DWORD last_error = ::GetLastError(); ec = boost::system::error_code(last_error, boost::asio::error::get_system_category()); } else { ec = boost::system::error_code(); } return ec; }
所以这些对象的构造函数都会带有io_service&的参数,就是为了绑定完成端口使用的。我们来看一下这个函数的调用方是如何使用register_handle的:
boost::system::error_code win_iocp_socket_service_base::do_open( win_iocp_socket_service_base::base_implementation_type& impl, int family, int type, int protocol, boost::system::error_code& ec) { if (is_open(impl)) { ec = boost::asio::error::already_open; return ec; } socket_holder sock(socket_ops::socket(family, type, protocol, ec)); if (sock.get() == invalid_socket) return ec; HANDLE sock_as_handle = reinterpret_cast<HANDLE>(sock.get()); if (iocp_service_.register_handle(sock_as_handle, ec)) return ec; impl.socket_ = sock.release(); switch (type) { case SOCK_STREAM: impl.state_ = socket_ops::stream_oriented; break; case SOCK_DGRAM: impl.state_ = socket_ops::datagram_oriented; break; default: impl.state_ = 0; break; } impl.cancel_token_.reset(static_cast<void*>(0), socket_ops::noop_deleter()); ec = boost::system::error_code(); return ec; }
简而言之呢,就是每个socket打开之后都会绑定在完成端口上。其实还有一个do_assign函数也调用了register_handle,这可函数可以当作拷贝构造函数吧,反正执行流与do_open差不多,只不过不会再构造一个新的socket了。
服务和对象都创建好了之后,我们需要一个线程池来执行任务。创建线程池在Asio中还是比较简单的:
thread1=std::thread(&io_service.run); thread1.join();
这样就可以为这个io_service增加一个线程执行单元了。
到具体平台执行层,这个run函数会委托到win_io_iocp_service::run来执行,这个函数的实现见下:
size_t win_iocp_io_service::run(boost::system::error_code& ec) { if (::InterlockedExchangeAdd(&outstanding_work_, 0) == 0) { stop(); ec = boost::system::error_code(); return 0; } win_iocp_thread_info this_thread; thread_call_stack::context ctx(this, this_thread); size_t n = 0; while (do_one(true, ec)) if (n != (std::numeric_limits<size_t>::max)()) ++n; return n; }
首先检查是否有未完成的操作,如果没有直接返回。否则将当前线程加入线程列表,然后开始循环的do_one来完成一个回调,每完成一个计数加一。
所有的任务都委托到了do_one中,这个才会与完成队列直接交互。这个函数的实现大约有110多行,这里我们分部分来分析。这个函数的整个函数体都被放在一个无限循环之中:
for (;;)
每次循环的头部是首先获得由于系统忙而导致未投递出的任务:
// Try to acquire responsibility for dispatching timers and completed ops. if (::InterlockedCompareExchange(&dispatch_required_, 0, 1) == 1) { mutex::scoped_lock lock(dispatch_mutex_); // Dispatch pending timers and operations. op_queue<win_iocp_operation> ops; ops.push(completed_ops_); timer_queues_.get_ready_timers(ops); post_deferred_completions(ops); update_timeout(); }
这里的dispatch_required_记录了是否有未投递出去的任务,取值范围只有0和1。而completed_ops_则存储了这些未成功投递的任务,每次循环都要把这些任务重新投递一次。
处理完未投递任务之后,我们开始在完成端口上等待一个事件的完成,或者超时:
// Get the next operation from the queue. DWORD bytes_transferred = 0; dword_ptr_t completion_key = 0; LPOVERLAPPED overlapped = 0; ::SetLastError(0); BOOL ok = ::GetQueuedCompletionStatus(iocp_.handle, &bytes_transferred, &completion_key, &overlapped, block ? gqcs_timeout_ : 0); DWORD last_error = ::GetLastError();
在得到了一个完成事件或者超时之后,我们检查返回的OVERLAPPED结构。如果有效的话,则转换为operation结构,因为operation结构是直接继承自OVERLAPPED的。
win_iocp_operation* op = static_cast<win_iocp_operation*>(overlapped); boost::system::error_code result_ec(last_error, boost::asio::error::get_system_category());
在做任何操作之间首先检查是否异常,然后再做后续的操作:
// We may have been passed the last_error and bytes_transferred in the // OVERLAPPED structure itself. if (completion_key == overlapped_contains_result) { result_ec = boost::system::error_code(static_cast<int>(op->Offset), *reinterpret_cast<boost::system::error_category*>(op->Internal)); bytes_transferred = op->OffsetHigh; } // Otherwise ensure any result has been saved into the OVERLAPPED // structure. else { op->Internal = reinterpret_cast<ulong_ptr_t>(&result_ec.category()); op->Offset = result_ec.value(); op->OffsetHigh = bytes_transferred; }
这个所谓的后续操作就是调用我们之前设置的回调函数,即operation.complete:
// Dispatch the operation only if ready. The operation may not be ready // if the initiating function (e.g. a call to WSARecv) has not yet // returned. This is because the initiating function still wants access // to the operation's OVERLAPPED structure. if (::InterlockedCompareExchange(&op->ready_, 1, 0) == 1) { // Ensure the count of outstanding work is decremented on block exit. work_finished_on_block_exit on_exit = { this }; (void)on_exit; op->complete(*this, result_ec, bytes_transferred); ec = boost::system::error_code(); return 1; }
这里的work_finished_on_block_exit又是一个RAII类,其唯一动作就是将outstanding_work_减1。自此,一个IO事件就算彻底完成了。
上面的代码已经说明了任务是怎么消费的,但是任务是如何添加的我们还没有搞清楚。在windows上,我们可通过两种形式往完成队列添加信息:
-
一个是异步操作完成,操作系统自己通过完成端口添加完成事件;
-
另外一个是手动调用
PostQueuedCompletionStatus函数往完成端口添加完成事件。
一般的异步操作都是第一种情形,例如async_read和async_write。但是有些操作并没有利用重叠IO机制,需要手动添加完成事件。例如:
-
async_resolver这个操作系统并没有提供对应的重叠IO操作; -
async_connect这个是Asio作者并没有采用支持重叠IO的ConnectEx函数; -
io_service自带的post和dispatch操作,压根就不属于IO范围,只不过复用了多线程处理队列而已。
对于这些类型的完成事件的提交,都会调用post_immediate_completion来处理。这个函数只会将outstanding_work_加1,然后调用post_deferred_completion。
void win_iocp_io_service::post_deferred_completion(win_iocp_operation* op) { // Flag the operation as ready. op->ready_ = 1; // Enqueue the operation on the I/O completion port. if (!::PostQueuedCompletionStatus(iocp_.handle, 0, 0, op)) { // Out of resources. Put on completed queue instead. mutex::scoped_lock lock(dispatch_mutex_); completed_ops_.push(op); ::InterlockedExchange(&dispatch_required_, 1); } }
这个函数只是将这些完成事件放到一个待处理的队列之中,最后一整批的放入系统的完成端口上:
void win_iocp_io_service::post_deferred_completions( op_queue<win_iocp_operation>& ops) { while (win_iocp_operation* op = ops.front()) { ops.pop(); // Flag the operation as ready. op->ready_ = 1; // Enqueue the operation on the I/O completion port. if (!::PostQueuedCompletionStatus(iocp_.handle, 0, 0, op)) { // Out of resources. Put on completed queue instead. mutex::scoped_lock lock(dispatch_mutex_); completed_ops_.push(op); completed_ops_.push(ops); ::InterlockedExchange(&dispatch_required_, 1); } } }
这个函数的调用时机就是每次do_one循环的开头,通过检查dispatch_required_来判断这个ops是不是空,如果不为空则调用此函数。
task io service 实现
在无IOCP支持的情况下,Asio可用的只有select/poll/epoll/kqueue之类的多路复用模式(windows也支持select,不过较弱,限制较多)。
而task_io_service这个类本身也是一个接口类,基本提供了与win_iocp_io_service等价的接口,同时会把操作转接到select/poll/epoll/kqueue之上去,我们这里就分析一下基于epoll的实现。
同样的,我们都以run这个函数为入口:
std::size_t task_io_service::run(boost::system::error_code& ec) { ec = boost::system::error_code(); if (outstanding_work_ == 0) { stop(); return 0; } thread_info this_thread; this_thread.private_outstanding_work = 0; thread_call_stack::context ctx(this, this_thread); mutex::scoped_lock lock(mutex_); std::size_t n = 0; for (; do_run_one(lock, this_thread, ec); lock.lock()) if (n != (std::numeric_limits<std::size_t>::max)()) ++n; return n; }
首先构造一个thread_info,和first_idle_thread_类型相同,即通过first_idle_thread_将所有线程串联起来,它这个串联不是立即串联的,当该线程无任务可做是加入到first_idle_thread_的首部,有任务执行时,从first_idle_thread_中断开。这很正常,因为first_idle_thread_维护的是当前空闲线程。
这里与iocp_service不同的地方就是有了一个lock,这个lock是用来互斥访问task_io_service的数据的;同时do_one函数改为了do_run_one。所有的四个具体的执行函数的参数中都有这个lock:
// Run at most one operation. May block. BOOST_ASIO_DECL std::size_t do_run_one(mutex::scoped_lock& lock, thread_info& this_thread, const boost::system::error_code& ec); // Poll for at most one operation. BOOST_ASIO_DECL std::size_t do_poll_one(mutex::scoped_lock& lock, thread_info& this_thread, const boost::system::error_code& ec); // Stop the task and all idle threads. BOOST_ASIO_DECL void stop_all_threads(mutex::scoped_lock& lock); // Wake a single idle thread, or the task, and always unlock the mutex. BOOST_ASIO_DECL void wake_one_thread_and_unlock( mutex::scoped_lock& lock);
这里我们继续跟进do_run_one函数,看看他干了些什么:
std::size_t task_io_service::do_run_one(mutex::scoped_lock& lock, task_io_service::thread_info& this_thread, const boost::system::error_code& ec) { while (!stopped_) { if (!op_queue_.empty()) { // Prepare to execute first handler from queue. operation* o = op_queue_.front(); op_queue_.pop(); bool more_handlers = (!op_queue_.empty()); //执行具体任务 } else { wakeup_event_.clear(lock); wakeup_event_.wait(lock); } } return 0; }
这里的操作就是每次从op_queue(其实是一个侵入性链表)里拿出头节点,然后处理。如果这个队列为空,那么就等待。
又根据与一个特殊的task_operation_的比较结果,这里的具体执行任务分为了两种情况。
if (o == &task_operation_) { task_interrupted_ = more_handlers; if (more_handlers && !one_thread_) wakeup_event_.unlock_and_signal_one(lock); else lock.unlock(); task_cleanup on_exit = { this, &lock, &this_thread }; (void)on_exit; // Run the task. May throw an exception. Only block if the operation // queue is empty and we're not polling, otherwise we want to return // as soon as possible. task_->run(!more_handlers, this_thread.private_op_queue); }
这里的逻辑就比较诡异了,首先做的是:
// Operation object to represent the position of the task in the queue. struct task_operation : operation { task_operation() : operation(0) {} } task_operation_;
如果我们得到的operation就是这个特殊的task_operation_的话,再根据队列是否还有剩下的任务以及是否是单线程执行的做下一步操作。如果有剩下的任务且是多线程环境,则使用wake_one_thread_and|unlock尝试唤醒可能休眠的线程;否则直接释放锁。可以看出,这个task_operation_的用途肯定是说明当前线程不适合执行任务了。
void task_io_service::wake_one_thread_and_unlock( mutex::scoped_lock& lock) { if (!wakeup_event_.maybe_unlock_and_signal_one(lock)) { if (!task_interrupted_ && task_) { task_interrupted_ = true; task_->interrupt(); } lock.unlock(); } }
这个wakeup_event是event类型的,这又是一个各种实现的别名:
#if !defined(BOOST_ASIO_HAS_THREADS) typedef null_event event; #elif defined(BOOST_ASIO_WINDOWS) typedef win_event event; #elif defined(BOOST_ASIO_HAS_PTHREADS) typedef posix_event event; #elif defined(BOOST_ASIO_HAS_STD_MUTEX_AND_CONDVAR) typedef std_event event; #endif
这里我就尝试去查看std的实现。实现上来说还是非常简单的,用条件变量来等待和通知,我就不贴代码了。
整个流程就是:若有空闲线程,则唤醒空闲线程;若没有空闲线程,但是有线程在执行task->run,即阻塞在epoll_wait上,那么先中断epoll_wait执行任务队列完成后再执行epoll_wait。这个阻塞标记位就是task_interrupted_。
// The task to be run by this service. reactor* task_;
然后就是让reactor执行当前线程的私有任务队列,最后返回的时候利用task_cleanup这个RAII类型去做一些清理工作:
struct task_io_service::task_cleanup { ~task_cleanup() { if (this_thread_->private_outstanding_work > 0) { boost::asio::detail::increment( task_io_service_->outstanding_work_, this_thread_->private_outstanding_work); } this_thread_->private_outstanding_work = 0; // Enqueue the completed operations and reinsert the task at the end of // the operation queue. lock_->lock(); task_io_service_->task_interrupted_ = true; task_io_service_->op_queue_.push(this_thread_->private_op_queue); task_io_service_->op_queue_.push(&task_io_service_->task_operation_); } task_io_service* task_io_service_; mutex::scoped_lock* lock_; thread_info* this_thread_; };
这里的操作就是将本线程的私有队列放入全局队列中,然后用task_operation_来标记一个线程私有队列的结束。
以上这些操作中唯一可疑的就是reactor.run函数了,我们继续顺藤摸瓜。在Asio中,reactor有多种实现模式,是一个代理类:
#if defined(BOOST_ASIO_WINDOWS_RUNTIME) typedef class null_reactor reactor; #elif defined(BOOST_ASIO_HAS_IOCP) typedef class select_reactor reactor; #elif defined(BOOST_ASIO_HAS_EPOLL) typedef class epoll_reactor reactor; #elif defined(BOOST_ASIO_HAS_KQUEUE) typedef class kqueue_reactor reactor; #elif defined(BOOST_ASIO_HAS_DEV_POLL) typedef class dev_poll_reactor reactor; #else typedef class select_reactor reactor; #endif
我们这里就查看一下epoll.run的实现吧,这个函数也比较长,我们分部分的来解析。首先是其签名:
void epoll_reactor::run(bool block, op_queue<operation>& ops) // This code relies on the fact that the task_io_service queues the reactor // task behind all descriptor operations generated by this function. This // means, that by the time we reach this point, any previously returned // descriptor operations have already been dequeued. Therefore it is now safe // for us to reuse and return them for the task_io_service to queue again.
这里首先对时钟的time_out做处理,设置好正确的time_out参数。如果有timer_fd在等待队列内且调用设置为非阻塞,则我们设置为立即返回;否则设置为阻塞。没有使用timer_fd的话则获取之前设置的time_out参数。
// Calculate a timeout only if timerfd is not used. int timeout; if (timer_fd_ != -1) timeout = block ? -1 : 0; else { mutex::scoped_lock lock(mutex_); timeout = block ? get_timeout() : 0; }
然后我们开始设置好epoll_wait的参数,开始等待。
// Block on the epoll descriptor. epoll_event events[128]; int num_events = epoll_wait(epoll_fd_, events, 128, timeout);
等待完成之后,我们开始分发事件:
#if defined(BOOST_ASIO_HAS_TIMERFD) bool check_timers = (timer_fd_ == -1); #else // defined(BOOST_ASIO_HAS_TIMERFD) bool check_timers = true; #endif // defined(BOOST_ASIO_HAS_TIMERFD) // Dispatch the waiting events. for (int i = 0; i < num_events; ++i) { void* ptr = events[i].data.ptr; if (ptr == &interrupter_) { // No need to reset the interrupter since we're leaving the descriptor // in a ready-to-read state and relying on edge-triggered notifications // to make it so that we only get woken up when the descriptor's epoll // registration is updated. #if defined(BOOST_ASIO_HAS_TIMERFD) if (timer_fd_ == -1) check_timers = true; #else // defined(BOOST_ASIO_HAS_TIMERFD) check_timers = true; #endif // defined(BOOST_ASIO_HAS_TIMERFD) } #if defined(BOOST_ASIO_HAS_TIMERFD) else if (ptr == &timer_fd_) { check_timers = true; } #endif // defined(BOOST_ASIO_HAS_TIMERFD) else { // The descriptor operation doesn't count as work in and of itself, so we // don't call work_started() here. This still allows the io_service to // stop if the only remaining operations are descriptor operations. descriptor_state* descriptor_data = static_cast<descriptor_state*>(ptr); descriptor_data->set_ready_events(events[i].events); ops.push(descriptor_data); } }
这里处理了三种event:interrupt,timer和普通的IO事件。这里需要特别说明的就是interrupt,这个是一个特别的文件描述符。如果我们想要人工的终止epoll_wait,可以通过select_interrupter函数来将这个描述符加入到监听列表之中去。select_interrupter实际上实现是eventfd_select_interrupter,在构造的时候通过pipe系统调用创建两个文件描述符,然后预先通过write_fd写8个字节,这8个字节一直保留。在添加到epoll_wait中采用EPOLLET水平触发,这样只要select_interrupter的读文件描述符添加到epoll_wait中,立即中断epoll_wait。
void epoll_reactor::interrupt() { epoll_event ev = { 0, { 0 } }; ev.events = EPOLLIN | EPOLLERR | EPOLLET; ev.data.ptr = &interrupter_; epoll_ctl(epoll_fd_, EPOLL_CTL_MOD, interrupter_.read_descriptor(), &ev); }
这里会调用set_ready_event来做一些工作,只是简单将当前事件放入可执行队列里而已。最后的结果是可执行的操作都放入了this_thread的private_op_queue之中去了,等待线程去处理。
如果不是task_operation,即普通的完成事件,初始处理也是类似。
else { std::size_t task_result = o->task_result_; if (more_handlers && !one_thread_) wake_one_thread_and_unlock(lock); else lock.unlock(); // Ensure the count of outstanding work is decremented on block exit. work_cleanup on_exit = { this, &lock, &this_thread }; (void)on_exit; // Complete the operation. May throw an exception. Deletes the object. o->complete(*this, ec, task_result); return 1; }
最后就是调用回调函数operation.complete,具体内容在前面的代码里也说明了:先执行IO,然后执行回调。至此整个线程调度可以说是完美结束。
而stop操作就比较简单了,直接调用stop_all_threads:
void task_io_service::stop_all_threads( mutex::scoped_lock& lock) { stopped_ = true; wakeup_event_.signal_all(lock); if (!task_interrupted_ && task_) { task_interrupted_ = true; task_->interrupt(); } }
直接设置stopped为true,然后唤醒所有休眠线程,这是通过single和interrupt一起实现的。