POGS Introduction
Proximal Graph Solver (POGS) is a solver for convex optimization problems in graph form using Alternating Direction Method of Multipliers (ADMM). The graph form problem can be expressed as
where \( f\) and \( g\) are convex and can take on the values \(R \cup {∞}\) . The solver requires that the proximal operators of \( f\) and \(g\) are known and that $f $ and $g $ are separable, meaning that they can be written as
The following functions are currently supported
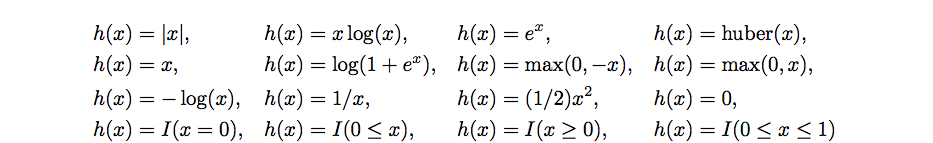
where \(I(.)\) is the indicator function, taking on the value 0 if the condition is satisfied and infinity otherwise.
util.h
The content of util.h is mainly about some ASSERT macro,like LEQ,LT,NEQ,GT,GEQ,EQ_EPS. Beside the common c++ macro, some CUDA specific macro is here as well:
#ifdef __CUDACC__ #define CUDA_CHECK_ERR() \ do { \ cudaError_t err = cudaGetLastError(); \ if (err != cudaSuccess) { \ std::cout << __FILE__ << ":" << __LINE__ << ":" \ << __BLUE << __func__ << "\n" \ << __RED << "ERROR_CUDA: " << cudaGetErrorString(err) \ << __RESET << std::endl; \ exit(EXIT_FAILURE); \ } \ } while (0) #endif
prox_lib.h
In this file , all kinds of loss function are defined. Currently pogs support 16 functions.
enum Function { kAbs, // f(x) = |x| kExp, // f(x) = e^x kHuber, // f(x) = huber(x) kIdentity, // f(x) = x kIndBox01, // f(x) = I(0 <= x <= 1) kIndEq0, // f(x) = I(x = 0) kIndGe0, // f(x) = I(x >= 0) kIndLe0, // f(x) = I(x <= 0) kLogistic, // f(x) = log(1 + e^x) kMaxNeg0, // f(x) = max(0, -x) kMaxPos0, // f(x) = max(0, x) kNegEntr, // f(x) = x log(x) kNegLog, // f(x) = -log(x) kRecipr, // f(x) = 1/x kSquare, // f(x) = (1/2) x^2 kZero };
If we want to add our own loss function, we should extend this enum definition.
The optimization functions in pogs are in this form
. The enum stands for the\(f\). Parameters \(a,c,e\) default to 1, while b and d default to 0. This optimization function is warpped in a FunctionObj
template<typename T> struct FunctionObj { Function h; T a, b, c, d, e; FunctionObj(Function h, T a, T b, T c, T d, T e) : h(h), a(a), b(b), c(c), d(d), e(e) { CheckConsts(); } void CheckConsts() { if (c < static_cast<T>(0)) Printf("WARNING c < 0. Function not convex. Using c = 0"); if (e < static_cast<T>(0)) Printf("WARNING e < 0. Function not convex. Using e = 0"); c = std::max(c, static_cast<T>(0)); e = std::max(e, static_cast<T>(0)); } };
Then here comes some simple warpper of math functions,like
__DEVICE__ inline double Abs(double x) { return fabs(x); } __DEVICE__ inline float Abs(float x) { return fabsf(x); }
Apart from the common math functions, there are some interesting math functions as well. Like the implementation of Lambert function and root of cubic function.The lambert w function is the inverse function of
These two functions are used later.
Then all math functions' evaluation is warpped into a FuncEval
template<typename T> __DEVICE__ inline T FuncEval(const FunctionObj<T> &f_obj, T x) { T dx = f_obj.d * x; T ex = f_obj.e * x * x / 2; x = f_obj.a * x - f_obj.b; switch (f_obj.h) { case kAbs: x = FuncAbs(x); break; default: x = FuncZero(x); break; } return f_obj.c * x + dx + ex; }
These warppers are necessary because we want to run on CPU/GPU, while these two platform has different implementation for these function. We don't want to mess our logicflow code with some ifdef endif guards. So we just warp these function and leave the macro guards to implementation files.
The warppers are used by proximal operator definitions. The socalled proximal operator has such form
where \(a,b,c,d,e\) are parameters. For every function enum, there is a corresponding proximal operator function whoes signature is the concatenation of Prox prefix and function enum name. The rational behind these 16 functions is that we can solve these functions analytically. These proximal operator is the result function of corresponding optimization problems.
The cubic root is used in reciprocal and the lambert is used in expotional. The only exception is logistic , it's implemented in iteration :
template<typename T> __DEVICE__ inline T ProxLogistic(T v, T rho) { // Initial guess based on piecewise approximation. T x; if (v < static_cast<T>(-2.5)) x = v; else if (v > static_cast<T>(2.5) + 1 / rho) x = v - 1 / rho; else x = (rho * v - static_cast<T>(0.5)) / (static_cast<T>(0.2) + rho); // Newton iteration. T l = v - 1 / rho, u = v; for (unsigned int i = 0; i < 5; ++i) { T inv_ex = 1 / (1 + Exp(-x)); T f = inv_ex + rho * (x - v); T g = inv_ex * (1 - inv_ex) + rho; if (f < 0) l = x; else u = x; x = x - f / g; x = Min(x, u); x = Max(x, l); } // Guarded method if not converged. for (unsigned int i = 0; u - l > Tol<T>() && i < 100; ++i) { T g_rho = 1 / (rho * (1 + Exp(-x))) + (x - v); if (g_rho > 0) { l = Max(l, x - g_rho); u = x; } else { u = Min(u, x - g_rho); l = x; } x = (u + l) / 2; } return x; }
Finally, all optimiztion process is abtracted to one ProxEval,this function is a variation of oringinal proximal operator, with additional penalty parameter. So current problem can be constructed as such:
We can tranform this problem to the proximal operator that we are familar with. Letting\(y=ax+b\), the problem with penalty can be transformed to
We take derivation of \(y\) except for the term \(c*f(y)\) , and set it to 0. Then we get
So the penalty proximal operator problem can be refractored to another proximal operator problem
where the \(k\) is a const value, so we can neglect it. The cpp code implemention is just what we have analyzed.
template<typename T> __DEVICE__ inline T ProxEval(const FunctionObj<T> &f_obj, T v, T rho) { const T a = f_obj.a, b = f_obj.b, c = f_obj.c, d = f_obj.d, e = f_obj.e; v = a * (v * rho - d) / (e + rho) - b; rho = (e + rho) / (c * a * a); switch (f_obj.h) { //here come all cases, I just list one for example case kSquare: v = ProxSquare(v, rho); break; case kZero: default: v = ProxZero(v, rho); break; } return (v + b) / a; }
As well as the derivation of these functions,in pogs they are called subgradient. The derivation function signature is concatenation of ProjSubgrad and function enum name. The common evaluation warpper is the same as FuncEval
emplate<typename T> __DEVICE__ inline T ProjSubgradEval(const FunctionObj<T> &f_obj, T v, T x) { const T a = f_obj.a, b = f_obj.b, c = f_obj.c, d = f_obj.d, e = f_obj.e; if (a == static_cast<T>(0.) || c == static_cast<T>(0.)) return d + e * x; v = static_cast<T>(1.) / (a * c) * (v - d - e * x); T axb = a * x - b; switch (f_obj.h) { case kAbs: v = ProjSubgradAbs(v, axb); break; default: v = ProjSubgradZero(v, axb); break; } return a * c * v + d + e * x; }
After layers and layers warpper, this file finally defines some interface function to evaluate these functions parallelly. Yet another OPENMP/CUDA warpper. Here are some examples:
// CPU version template<typename T> void ProxEval(const std::vector<FunctionObj<T> > &f_obj, T rho, const T *x_in, T *x_out) { #ifdef _OPENMP #pragma omp parallel for #endif for (unsigned int i = 0; i < f_obj.size(); ++i) x_out[i] = ProxEval(f_obj[i], x_in[i], rho); } //GPU version template<typename T> struct ProxEvalF: thrust::binary_function<FunctionObj<T>, T, T> { T rho;__device__ ProxEvalF(T rho) : rho(rho) { } __device__ T operator()(const FunctionObj<T> &f_obj, T x) { return ProxEval(f_obj, x, rho); } }; template<typename T> void ProxEval(const thrust::device_vector<FunctionObj<T> > &f_obj, T rho, const T *x_in, T *x_out) { thrust::transform(thrust::device, f_obj.cbegin(), f_obj.cend(), thrust::device_pointer_cast(x_in), thrust::device_pointer_cast(x_out), ProxEvalF<T>(rho)); }
These implemetations are very interesting. Need more attention here.
This file also defines the eps
template<typename T> __DEVICE__ inline T Epsilon(); template<> __DEVICE__ inline double Epsilon<double>() { return 4e-16; } template<> __DEVICE__ inline float Epsilon<float>() { return 1e-7f; }
pogs.h
The pogs.h defines some control variables and instructions:
const double kAbsTol = 1e-4; const double kRelTol = 1e-3; const double kRhoInit = 1.; const unsigned int kVerbose = 2u; // 0...4 const unsigned int kMaxIter = 2500u; const unsigned int kInitIter = 10u; const bool kAdaptiveRho = true; const bool kGapStop = false;
Apparently the name schema is subject to Google C++ style. Aside from these const values, some enum status are defined as well.
enum PogsStatus { POGS_SUCCESS, // Converged succesfully. POGS_INFEASIBLE, // Problem likely infeasible. POGS_UNBOUNDED, // Problem likely unbounded POGS_MAX_ITER, // Reached max iter. POGS_NAN_FOUND, // Encountered nan. POGS_ERROR };
Then there comes the problem warpper Pogs
template<typename T, typename M, typename P> class Pogs { private: // Data M _A; P _P; T *_de, *_z, *_zt, _rho; bool _done_init; // Setup matrix _A and solver _LS int _Init(); // Output. T *_x, *_y, *_mu, *_lambda, _optval; // Parameters. T _abs_tol, _rel_tol; unsigned int _max_iter, _init_iter, _verbose; bool _adaptive_rho, _gap_stop, _init_x, _init_lambda; }
When we use Pogs, we just use a warpper of it PogsDirect or PogsIndirect
#ifndef __CUDACC__ template <typename T, typename M> using PogsDirect = Pogs<T, M, ProjectorDirect<T, M> >; template <typename T, typename M> using PogsIndirect = Pogs<T, M, ProjectorCgls<T, M> >; #endif
pogs.cpp
Firstly, it defines aApplyOp in a anonymous namespace, yet another function warpper:
template<typename T, typename Op> struct ApplyOp: std::binary_function<FunctionObj<T>, FunctionObj<T>, T> { Op binary_op; ApplyOp(Op binary_op) : binary_op(binary_op) { } FunctionObj<T> operator()(FunctionObj<T> &h, T x) { h.a = binary_op(h.a, x); h.d = binary_op(h.d, x); h.e = binary_op(binary_op(h.e, x), x); return h; } };
Well , I have no idea why we need it.
Then here is the default pogs constructor:
template<typename T, typename M, typename P> Pogs<T, M, P>::Pogs(const M &A) : _A(A), _P(_A), _de(0), _z(0), _zt(0), _rho( static_cast<T>(kRhoInit)), _done_init(false), _x(0), _y(0), _mu( 0), _lambda(0), _optval(static_cast<T>(0.)), _abs_tol( static_cast<T>(kAbsTol)), _rel_tol(static_cast<T>(kRelTol)), _max_iter( kMaxIter), _init_iter(kInitIter), _verbose(kVerbose), _adaptive_rho( kAdaptiveRho), _gap_stop(kGapStop), _init_x(false), _init_lambda( false) { _x = new T[_A.Cols()](); _y = new T[_A.Rows()](); _mu = new T[_A.Cols()](); _lambda = new T[_A.Rows()](); }
The constructor list is insane! After the contruction, we call pogs::init to do some check and memory allocation.
template<typename T, typename M, typename P> int Pogs<T, M, P>::_Init() { DEBUG_EXPECT(!_done_init); if (_done_init) return 1; _done_init = true; size_t m = _A.Rows(); size_t n = _A.Cols(); _de = new T[m + n]; ASSERT(_de != 0); _z = new T[m + n]; ASSERT(_z != 0); _zt = new T[m + n]; ASSERT(_zt != 0); memset(_de, 0, (m + n) * sizeof(T)); memset(_z, 0, (m + n) * sizeof(T)); memset(_zt, 0, (m + n) * sizeof(T)); _A.Init(); _A.Equil(_de, _de + m); _P.Init(); return 0; }
After all the preparation, we call pogs::solve to get everything done. The signature of such function is:
template<typename T, typename M, typename P> PogsStatus Pogs<T, M, P>::Solve(const std::vector<FunctionObj<T> > &f,const std::vector<FunctionObj<T> > &g)
At the beginning of this function, it sets some const vars and memory allocation.
double t0 = timer<double>(); // Constants for adaptive-rho and over-relaxation. const T kDeltaMin = static_cast<T>(1.05); const T kGamma = static_cast<T>(1.01); const T kTau = static_cast<T>(0.8); const T kAlpha = static_cast<T>(1.7); const T kRhoMin = static_cast<T>(1e-4); const T kRhoMax = static_cast<T>(1e4); const T kKappa = static_cast<T>(0.9); const T kOne = static_cast<T>(1.0); const T kZero = static_cast<T>(0.0); const T kProjTolMax = static_cast<T>(1e-8); const T kProjTolMin = static_cast<T>(1e-2); const T kProjTolPow = static_cast<T>(1.3); const T kProjTolIni = static_cast<T>(1e-5); bool use_exact_stop = true; size_t m = _A.Rows(); size_t n = _A.Cols(); std::vector<FunctionObj<T> > f_cpu = f; std::vector<FunctionObj<T> > g_cpu = g; // Allocate data for ADMM variables. gsl::vector<T> de = gsl::vector_view_array(_de, m + n); gsl::vector<T> z = gsl::vector_view_array(_z, m + n); gsl::vector<T> zt = gsl::vector_view_array(_zt, m + n); gsl::vector<T> zprev = gsl::vector_calloc<T>(m + n); gsl::vector<T> ztemp = gsl::vector_calloc<T>(m + n); gsl::vector<T> z12 = gsl::vector_calloc<T>(m + n); // Create views for x and y components. gsl::vector<T> d = gsl::vector_subvector(&de, 0, m); gsl::vector<T> e = gsl::vector_subvector(&de, m, n); gsl::vector<T> x = gsl::vector_subvector(&z, 0, n); gsl::vector<T> y = gsl::vector_subvector(&z, n, m); gsl::vector<T> x12 = gsl::vector_subvector(&z12, 0, n); gsl::vector<T> y12 = gsl::vector_subvector(&z12, n, m); gsl::vector<T> xprev = gsl::vector_subvector(&zprev, 0, n); gsl::vector<T> yprev = gsl::vector_subvector(&zprev, n, m); gsl::vector<T> xtemp = gsl::vector_subvector(&ztemp, 0, n); gsl::vector<T> ytemp = gsl::vector_subvector(&ztemp, n, m);
The gsl::vector_subvector is to provide a vector slice with its begin idx and length. The most important piece of these memory allocation is that \(z\) is concatenation of \(x,y\), ie
And the vars' correspondance to the vars in paper is
Some more attention should be payed to the scale.
// Scale f and g to account for diagonal scaling e and d. std::transform(f_cpu.begin(), f_cpu.end(), d.data, f_cpu.begin(), ApplyOp<T, std::divides<T> >(std::divides<T>())); std::transform(g_cpu.begin(), g_cpu.end(), e.data, g_cpu.begin(), ApplyOp<T, std::multiplies<T> >(std::multiplies<T>()));
If we have already run the solver before and gotten some results, we can resume the solver by filling \(x,lambda\) by reusing these results.
if (_init_x) { gsl::vector_memcpy(&xtemp, _x); gsl::vector_div(&xtemp, &e); _A.Mul('n', kOne, xtemp.data, kZero, ytemp.data); gsl::vector_memcpy(&z, &ztemp); } if (_init_lambda) { gsl::vector_memcpy(&ytemp, _lambda); gsl::vector_div(&ytemp, &d); _A.Mul('t', -kOne, ytemp.data, kZero, xtemp.data); gsl::blas_scal(-kOne / _rho, &ztemp); gsl::vector_memcpy(&zt, &ztemp); }
Otherwise, we make a initial guess for these two vars
if (_init_x && !_init_lambda) { // Alternating projections to satisfy // 1. \lambda \in \partial f(y), \mu \in \partial g(x) // 2. \mu = -A^T\lambda gsl::vector_set_all(&zprev, kZero); for (unsigned int i = 0; i < kInitIter; ++i) { ProjSubgradEval(g_cpu, xprev.data, x.data, xtemp.data); ProjSubgradEval(f_cpu, yprev.data, y.data, ytemp.data); _P.Project(xtemp.data, ytemp.data, kOne, xprev.data, yprev.data, kProjTolIni); gsl::blas_axpy(-kOne, &ztemp, &zprev); gsl::blas_scal(-kOne, &zprev); } // xt = -1 / \rho * \mu, yt = -1 / \rho * \lambda. gsl::vector_memcpy(&zt, &zprev); gsl::blas_scal(-kOne / _rho, &zt); } else if (_init_lambda && !_init_x) { ASSERT(false); } _init_x = _init_lambda = false;
Then it defines the stop criteria.
T sqrtn_atol = std::sqrt(static_cast<T>(n)) * _abs_tol; T sqrtm_atol = std::sqrt(static_cast<T>(m)) * _abs_tol; T sqrtmn_atol = std::sqrt(static_cast<T>(m + n)) * _abs_tol; T delta = kDeltaMin, xi = static_cast<T>(1.0); unsigned int k = 0u, kd = 0u, ku = 0u; bool converged = false; T nrm_r, nrm_s, gap, eps_gap, eps_pri, eps_dua;
Finally, here is the big iteration loop. I'm going to examine it step by step.
gsl::vector_memcpy(&zprev, &z); // Evaluate Proximal Operators gsl::blas_axpy(-kOne, &zt, &z); ProxEval(g_cpu, _rho, x.data, x12.data); ProxEval(f_cpu, _rho, y.data, y12.data);
In math , these code are identical to
The prox is proximal operator. After the new value of \(x,y\) are computed, we calculate the gap,optimal value and tolerance to decide if the stop criterion is meet.
gsl::blas_axpy(-kOne, &z12, &z); gsl::blas_dot(&z, &z12, &gap); gap = std::abs(gap); eps_gap = sqrtmn_atol+ _rel_tol * gsl::blas_nrm2(&z) * gsl::blas_nrm2(&z12); eps_pri = sqrtm_atol + _rel_tol * gsl::blas_nrm2(&y12); eps_dua = sqrtn_atol + _rel_tol * _rho * gsl::blas_nrm2(&x);// should be x12?
The math procedure is
// Apply over relaxation. gsl::vector_memcpy(&ztemp, &zt); gsl::blas_axpy(kAlpha, &z12, &ztemp); gsl::blas_axpy(kOne - kAlpha, &zprev, &ztemp); // Project onto y = Ax. T proj_tol = kProjTolMin / std::pow(static_cast<T>(k + 1), kProjTolPow); proj_tol = std::max(proj_tol, kProjTolMax); _P.Project(xtemp.data, ytemp.data, kOne, x.data, y.data, proj_tol);
The corrosponding math procedure is
The projector function is not fully discussed. We will dive into its details later.
Now we calculate the residual :
// Calculate residuals. gsl::vector_memcpy(&ztemp, &zprev); gsl::blas_axpy(-kOne, &z, &ztemp); nrm_s = _rho * gsl::blas_nrm2(&ztemp); gsl::vector_memcpy(&ztemp, &z12); gsl::blas_axpy(-kOne, &z, &ztemp); nrm_r = gsl::blas_nrm2(&ztemp);
The math procudure is
Then the solver decide if it calculate the exact residual by comparing current rough residual to the eps
// Calculate exact residuals only if necessary. bool exact = false; if ((nrm_r < eps_pri && nrm_s < eps_dua) || use_exact_stop) { gsl::vector_memcpy(&ztemp, &z12); _A.Mul('n', kOne, x12.data, -kOne, ytemp.data); nrm_r = gsl::blas_nrm2(&ytemp); if ((nrm_r < eps_pri) || use_exact_stop) { gsl::vector_memcpy(&ztemp, &z12); gsl::blas_axpy(kOne, &zt, &ztemp); gsl::blas_axpy(-kOne, &zprev, &ztemp); _A.Mul('t', kOne, ytemp.data, kOne, xtemp.data); nrm_s = _rho * gsl::blas_nrm2(&xtemp); exact = true; } }
Frankly,I don't know where the exact residual come from!!!!
Finally we come to the stopping criterial
converged = exact && nrm_r < eps_pri && nrm_s < eps_dua&& (!_gap_stop || gap < eps_gap); if (converged || k == _max_iter - 1)break;
If not converged yet, we should update the dual variable
// Update dual variable. gsl::blas_axpy(kAlpha, &z12, &zt); gsl::blas_axpy(kOne - kAlpha, &zprev, &zt); gsl::blas_axpy(-kOne, &z, &zt);
In short, the z update is
Sometimes the \(\rho\) is dynamic , we would update the \(\rho\) as well. The detail is ad-hoc so I'm not going to explain it (It's just a mess).
The whole procedure is not straight to understand, especially with the different \(z\) names. The workflow presented in paper is:
The \(\prod\) denotes projection onto \(\{(x,y)| y=Ax\}\).
The solver body is completed, and we instantiate some template at the end of this cpp file:
// Explicit template instantiation. // Dense direct. template class Pogs<double, MatrixDense<double>, ProjectorDirect<double, MatrixDense<double> > > ; template class Pogs<float, MatrixDense<float>, ProjectorDirect<float, MatrixDense<float> > > ; // Dense indirect. template class Pogs<double, MatrixDense<double>, ProjectorCgls<double, MatrixDense<double> > > ; template class Pogs<float, MatrixDense<float>, ProjectorCgls<float, MatrixDense<float> > > ; // Sparse indirect. template class Pogs<double, MatrixSparse<double>, ProjectorCgls<double, MatrixSparse<double> > > ; template class Pogs<float, MatrixSparse<float>, ProjectorCgls<float, MatrixSparse<float> > > ;
projection.h
The subspace projection problem is to project \(x_0,y_0\) to one point \((x_1,y_1)\) in subspace \(y=Ax\). Ie
Infact this subspace projection is a viaration of least squre projection \(Ax=b\). If we conside \(b=x_0++y_0\) and \(A_1=I++A\) where the \(++\) is concatenation . So current problem is to solve the least square projection of \(A_1 x=b\).
But there is a cut through answer without the concatenation . We take derivation of
and set it to zero, we get
That's a least square projection problem. If we solve the \(x\) ,then \(y=Ax\).
The least square projection problem.r can be done in two manner: conjugate gradient and direct.
The conjugate gradient algorithm is detailed below for solving \(Ax = b\) where \(A\) is a real, symmetric, positive-definite matrix. The input vector \(x_0\) can be an approximate initial solution or 0.

While the direct method is to compute
The code is straight forward. Here is the preparation work.
size_t min_dim = std::min(_A.Rows(), _A.Cols()); info->AA = new T[min_dim * min_dim]; ASSERT(info->AA != 0); info->L = new T[min_dim * min_dim]; ASSERT(info->L != 0); memset(info->AA, 0, min_dim * min_dim * sizeof(T)); memset(info->L, 0, min_dim * min_dim * sizeof(T)); CBLAS_TRANSPOSE_t op_type = _A.Rows() > _A.Cols() ? CblasTrans : CblasNoTrans; // Compute AA if (_A.Order() == MatrixDense<T>::ROW) { const gsl::matrix<T, CblasRowMajor> A = gsl::matrix_view_array<T, CblasRowMajor> (_A.Data(), _A.Rows(), _A.Cols()); gsl::matrix<T, CblasRowMajor> AA = gsl::matrix_view_array < T, CblasRowMajor > (info->AA, min_dim, min_dim); gsl::blas_syrk(CblasLower, op_type, static_cast<T>(1.), &A, static_cast<T>(0.), &AA); }
In short, the pogs consider \(A\) is \(m*n\) ,while\(m\ge n\). If the input is not in that form, we would transpose \(A\)(not transpose it in memory but logically). Themin_dim is \(less(m,n)\). And the \(A^TA\) is computed by a syrk call.
const gsl::matrix<T, CblasRowMajor> A = gsl::matrix_view_array<T, CblasRowMajor> (_A.Data(), _A.Rows(), _A.Cols()); gsl::matrix<T, CblasRowMajor> AA = gsl::matrix_view_array < T, CblasRowMajor > (info->AA, min_dim, min_dim); gsl::matrix<T, CblasRowMajor> L = gsl::matrix_view_array < T, CblasRowMajor > (info->L, min_dim, min_dim); if (s != info->s) { gsl::matrix_memcpy(&L, &AA); gsl::vector<T> diagL = gsl::matrix_diagonal(&L); gsl::vector_add_constant(&diagL, s); gsl::linalg_cholesky_decomp(&L); } if (_A.Rows() > _A.Cols()) { gsl::blas_gemv(CblasTrans, static_cast<T>(1.), &A, &y_vec, static_cast<T>(1.), &x_vec); gsl::linalg_cholesky_svx(&L, &x_vec); gsl::blas_gemv(CblasNoTrans, static_cast<T>(1.), &A, &x_vec, static_cast<T>(0.), &y_vec); }
We must take care of row major or col major.