相关概念
首先介绍一下Concurrency,因为如果没有concurrency的话,后面两个也就基本没啥意义。concurrency也就是并行,比较简单的描述就是多个线程(进程)同时运行,在并发环境下衍生除了一个非常重要的问题,就是mutable资源的共享问题, 主要是共享内存的读写问题。下面就是一个共享内存多线程读写的例子.

在两个core分别执行完之后, r1和r2的值在不同的硬件环境下是不一样的, 甚至在相同硬件环境下都有可能出现各种结果,最奇葩的情况莫过于(0, 0),(0,NEW),(NEW, 0), (NEW, NEW)四种情况都可能出现。这种不确定性在于程序对内存的读写并不一定是瞬发完成的,可能是一个异步的过程。而且CPU甚至为了优化内存访问,可能对没有数据依赖的程序指令进行重新排序, 这种指令重排序对于单线程程序来说并没有多大影响,但是在多线程下很有可能造成错误的结果。
共享内存可以简单的理解为一个server, 而每个线程则认为是一个client,server可以同时服务多个client,每个client发送消息到server是有延迟的,client的单个消息到达server之后只能一个一个处理,处理完成一个之后才能处理下一个。client可以对server发起的操作目前只有简单的load store, load操作会读取server存储的全局状态, 而store操作则会修改server存储的全局状态。每个client端发出的操作都带有一个时间戳, 而server端处理这个操作的时候也会有一个时间戳。x操作的client时间戳早于y操作的client时间戳并不意味着x操作的server时间戳早于y操作在的server时间戳,最松散的内存模型甚至并不保证x,y操作在client端发起之后会最终到达server。 这个是最基本的共享内存的结构,具体的内存模型基本都可以在这个client-server模型上做拓展。Consistency所面临的问题是如何正确对各个client呈现对server操作的顺序,也就是读写共享内存的时序, 以符合程序所期望的语义。这种内存系统对于维持访问顺序和写内存可见性所做出的一些规定,就是Consistency model, 也叫内存模型。
而coherence的定义对象则是缓存cache line,并不是定义在内存之上的。cache的存在目的是为了对内存的读写进行加速,但是由于每个cpu都有自己专有的缓存,从而导致了更多的共享内存的问题。在带有缓存之后,我们就无法简单的保证client端发起的操作一定会到达server端, 可能每个client自己的缓存就处理了client的请求。coherence的目的则是让所有client的独立cache表现的如同所有client共享一个cache一样, 并最终达到将cache对client不可见的目的。
缓存系统维持coherence就需要实现两点:
- 单写者多读者的机制,也就是常见的读写锁。这种读写锁最简单的实现方式就是对内存的访问分为了epoch, 就是断代访问, 每个core对于同一个cache line都拥有一把锁,读取一个变量只需要本地锁,而写一个变量则需要获取所有core对应cache line的锁,这样每个epoch期间对于同一个cache line最多只能有一次写操作。
- 当前epoch对内存做的修改在下个epoch时对所有core都可见。不加上这个修改传播的话,我们可以在每个epoch保证对一个cache line只写一次的同时在epoch的末尾将这个写操作留在当前core,其他core在下一个epoch仍然看不到最新的修改。
至于coherence与consistency的关系,只能说coherence基本都是consistency的基础,但不是必要的。 特定的内存模型允许一定的incoherence,甚至都不需要cache系统内存系统也可以存在,但是这样带来的后果就是慢。简而言之,coherence是consistency必须要考虑的一个因素,甚至是最重要的因素。
基础模型
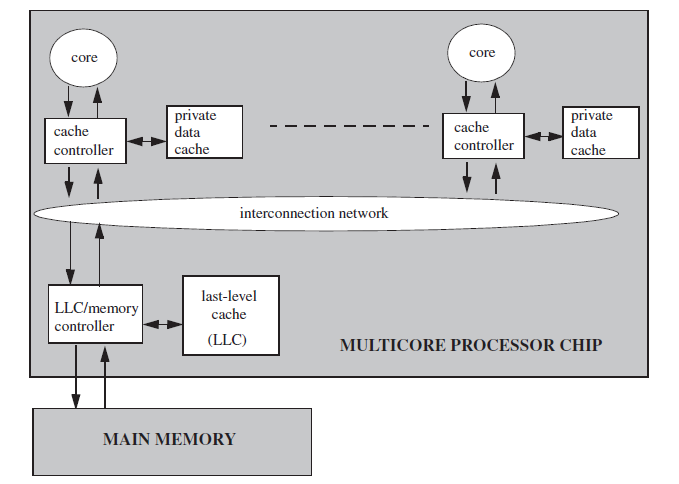
为了描述cpu、缓存、内存之间的消息通信,通过归纳现有的硬件平台抽象出了如下的一个带有两层缓存结构模型:
- 每个cpu都有一个专属的cache
- 所有cpu共享一个last level cache
- LLC(last level cache)直接与内存相连
- 每个cpu对内存的读写都需要经过专属的缓存控制器
- 专属缓存控制器可以将读写请求拦截在本地, 也可以将请求转发到LLC
- LLC缓存控制器可以将读写请求拦截到本地,也可以将请求转发到内存
具体的结构图如下:
常见的内存一致性模型包括:
- Sequence Consistence 常见平台 MIPS
- Total Store Order 常见平台X86
- Relaxed Model 常见平台Power
下面对着三种内存一致性模型做一下介绍。
Sequence Consistency
Sequence Consistency定义
Sequence Consistency也被称作为序列一致性,顾名思义,就是每个core发起的操作都保持有序的到达memory, 所有的core在同一时刻看到的memory格局都是一样的,这样就要求任何在内存上的操作维持了一个全序。
为了定义这个序列的概念, 我们引入两个新的概念,程序序和内存序。程序序\(<_p\)表示的是在同一个线程里两个内存操作指令在执行时的顺序关系,而内存序\(<_m\)则表示两个内存操作在内存系统处理时的顺序关系,也就是之前谈到的client时间戳和server时间戳。对于操作\(a,b\) ,如果\(a <_p b\)则表示在同一个线程中\(a\)操作先于\(b\)操作执行, 如果\(a <_m b $ 则表示在内存系统中\)a\(操作先于\)b$操作执行。
在这两个记号的辅助下, 我们可以对序列一致性做一下形式化的规定:
- 所有的cpu core都顺序的提交任何内存相关操作, 同时内存系统保证在处理来自同一个core发出的请求时,都维持这些请求的顺序。对于任意的两个内存地址\(a,b\), 不管\(a,b\)是否相等,下面的公式都成立。
- \(L(a) <_p L(b) \Rightarrow L(a) <_m L(b)\)
- \(L(a) <_p S(b) \Rightarrow L(a) <_m S(b)\)
- \(S(a) <_p S(b) \Rightarrow S(a) <_m S(b)\)
- \(S(a) <_p L(b) \Rightarrow S(a) <_m L(b)\)
- 每次load的时候都会获得在内存序中早于这个load且最晚发生的对应内存区域的store的值,也就是 \(L(a) = Value\ of \ MAX_{<_m}\{S(a) \vert S(a) <_m L(a)\}\)
- 对于原子的(RMW)read-modify-write操作来说,可以拆分为一个load和一个save操作,这两个操作在\(<_m\)中是相邻的
在这些限制条件下,cpu完全就没有了乱序执行的能力,
Sequence Consistency 实现
在我们定义的基础模型上,实现序列一致性有两种naive方案:
- 彻底废除掉多核,每个线程只能允许到同一个核上执行
- 令牌机制,每个线程在执行内存访问之前都需要首先获得一个全局的令牌,执行完一次内存访问之后释放这个令牌。
反正不管怎么实现都看起来特别的蠢,too simple , too naive。
要对这个加速的话,需要加入之前的带读写锁的缓存系统。在这个缓存系统上我们定义两个操作来处理读写:
- GetM 获得对特定cache line的读写权限, 之后这个cache line在当前core上的状态是M, 并且将其他core上的对应cache line evict掉,
- GetS 获得特定cache line的读权限, 之后这个cache line在当前core上的状态是S, 如果之前是M状态,则释放锁
在这两个操作的辅助下,我们来处理load和save和RMW:
- load 首先查询该cache line 在当前core的状态,如果不在则发起GetS操作
- save 首先查询该cache line在当前core的状态是不是M, 如果不是则发起GetM操作,写完之后再getS来释放锁
- RMW 跟save一样
而缓存控制器则可以同时处理多个get请求,只要这个请求在不同的地址之上。如果有相同地址且有一个getM操作,则getM操作后的同一地址的任何操作都需要等待。
Total Store Order
Total Store Order 定义
Total store order是spark采用的内存模型,同时由于x86的内存模型跟这个模型很相似,所以这个内存模型可以说用处最广。这个内存模型使用一个FIFO的写缓冲区来处理save操作。所以对于本文最早的那个图才会出现(0,0)的结果, 因为两次写都被缓存住了,并没有进入到内存之中。total store order的形式化定义与sequence consistency基本一致,除了缺少下面的这条规则:
\(S(a) <_p L(b) \Rightarrow S(a) <_m L(b)\)
这条规则也就是人们常说的写后读,RAW(read after write)。同时因为这个写缓冲的存在,load操作的语义也需要修改;
现在load的语义变为了要么读取全局序的最近修改值,要么读取当前core的最近修改值。
为了在必要的时候实现RAW的一致性,TSO平台基本都会有一条叫做FENCE的指令(也就是传说中的memory barrier)。在全局内存序上:FENCE之前的指令在内存序上不会出现在FENCE之后的指令的后面。在接入FENCE之后,一致性定义也需要做对应的修改:
- \(L(a) <_p FENCE \Rightarrow L(a) <_m FENCE\)
- \(S(a) <_p FENCE \Rightarrow S(a) <_m FENCE\)
- $FENCE(A) <_p FENCE(B) \Rightarrow FENCE(A) <_m FENCE(B) $
- $FENCE <_p L(a) \Rightarrow FENCE <_m L(a) $
- \(FENCE <_p S(a) \Rightarrow FENCE <_m S(a)\)
Total Store Order 实现
目前我们需要处理的就是新加入的FIFO 写缓冲,为此我们定义以下四个规则:
- load 和store在当前core上维持\(<_p\)
- 一次load, 如果写缓冲里有对应地址的写,则返回最新的关于对应地址的写,否则尝试去请求内存
- 一次store,如果已经满了则等待这个写缓冲刷新到主内存,然后将这个store放在FIFO写缓冲的队尾
- 当内存调度器将调度权转移到当前core时,这个core要么执行下一次的load,要么对当前写缓冲的头部store进行写回
对于RMW之类的原子操作,最简单的维护一致性的方法就是每次在这个指令前都把当前core的写缓冲都写回。而对于FENCE指令,也可以采取这个简单粗暴的做法。
Relaxed Memory Consistency
Relaxed Memory Consistency定义
TSO是相对于SC的一种妥协,使用写缓冲来避免所有缓存的同步操作。Relaxed Memory Consistency则更进一步,或者说得寸进尺,认为如非必要则一切都可以乱序。此时只维持对相同地址的内存操作序和FENCE序:
- \(L(a) <_p L(a) \Rightarrow L(a) <_m L(a)\)
- \(L(a) <_p S(a) \Rightarrow L(a) <_m S(a)\)
- \(S(a) <_p S(a) \Rightarrow S(a) <_m S(a)\)
- \(L(a) <_p FENCE \Rightarrow L(a) <_m FENCE\)
- \(S(a) <_p FENCE \Rightarrow S(a) <_m FENCE\)
- \(FENCE(A) <_p FENCE(B) \Rightarrow FENCE(A) <_m FENCE(B)\)
- \(FENCE <_p L(a) \Rightarrow FENCE <_m L(a)\)
- \(FENCE <_p S(a) \Rightarrow FENCE <_m S(a)\)
同样,由于写缓冲的存在,load的语义跟TSO一致:
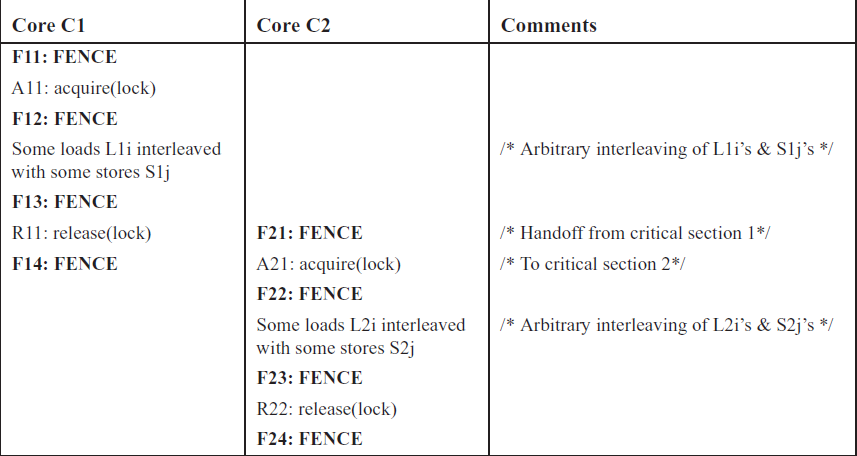
由于Relaxed Memory Consistency的约束少,此时RMW不再具有SC的FENCE的功能,因为之前的同步原语RMW包含的load store现在可以被动态的调度到前面。 导致写多线程同步的代码需要插入很多的fence,下面便是几个典型的例子:

Relaxed Memory Consistency 的实现
要实现这个Relaxed Memory Consistency需要对之前的FIFO写缓冲做一些修改,直接放弃FIFO的序列功能,直接合并写。对于读写操作,有如下规则:
- load store 和fence 都会进入到当前core的重编排单元中去调度
- 重编排单元按照前面规定的八个规则去安插新进入的请求,
- 当内存调度器选择当前core去执行的时候,选择当前调度队列的头节点去load或者store,如果遇到的是fence,则抛弃并选择下一个节点
对于调度器,需要遵守如下原则:
- 保持fence的有序
- 保持对同一地址的相关操作有序,Store Load操作除外
- 当load的时候,如果写缓冲里有对应地址的值,则直接读取这个值
FENCE与Atomic
前面的三个内存模型中,我们对于fence的定义都是barrier,在这之前的操作永远\(<_m\)于在这之后的操作。但是有些体系结构里还是觉得这个FENCE太重了,因此又定义了几种新的fence。
- sequence fence 这种fence就是我们最初设计的fence, 其语义就是\(a<_p seq\_cst <_p b \Rightarrow a<_m seq\_cst <_m b\),每次使用之后都会将写缓冲写回。由于每次都写回缓冲区,同时这个写回操作在内存控制器里是独占的,因此可以推论出使用了sequence fence的atomic操作维持了一个全局唯一的序列。
- acquire fence 其语义为\(acquire <_p a \Rightarrow acquire<_m a\)
- release fence 其语义为 \(a<_p release \Rightarrow a<_m release\)
手工来添加fence是比较危险的,主要是容易忘记。为了便利程序员和编译器来处理fence相关的代码,c++还提出了atomic来简化fence的使用。atomic顾名思义就是原子变量,他包含了两个重要的性质:
- 单个线程内对于相同的原子变量的读写操作不会被编译器和cpu重排
- 对于同一个原子变量的多线程操作,保证在全局维持一个统一的modification sequence,即每次修改都会直接通知其他cpu的缓存系统进行更新,而不会放在本地的写缓冲之中,这个性质保证了每次对于原子变量的读取都获得了最近一次修改的值。以例子来说,如果我们有一个原子的counter,初始为10,多个线程去fetch_sub这个counter来分配工作,则这些线程读取的counter值的序列一定是10-9-8...1单调递减的。如果使用print来打印读取出来的值,这个序列的顺序可能会打乱(因为输出流在多线程下是无序的),但是仍然会保证所有数字都会出现且只会出现一次。
atomic包括三种操作,load, save和read-modify-write。这三个操作都可以使用对应的fence来标记处理,在生成代码时会对应的内存操作之前或之后加入对应的fence。有些时候会在之前和之后都加入fence,例如前面是acquire后面是release 的read-modify_write操作,或者是sequence fence操作。
在c++中,fence的存在有两种形式:atomic_thread_fence和atomic_signal_fence。thread_fence是用来警告编译器和cpu不要乱排序,而signal_fence是用来警告编译器不要乱排序。
memory order in c++ 11
在c++11中引入了6种应用于原子变量的内存次序:
- memory_order_relaxed 这是约束最低的次序 只要求保证单个线程内的对相同原子变量的操作不会被编译器和cpu乱序,不关心这些操作在其他线程内的可见顺序,只保证原子性,只关系单个操作。举个例子来说:
// Thread 1: r1 = y.load(memory_order_relaxed); // A x.store(r1, memory_order_relaxed); // B // Thread 2: r2 = x.load(memory_order_relaxed); // C y.store(42, memory_order_relaxed); // D
最终执行完成之后可能会出现r1=r2=42这种荒谬的结果。因为当前的内存序并没有规定同步关系。虽然AB操作在线程1里保证了先后顺序,但是在线程2种,可能B出现在C之前, A出现在D之后。cppreference里说这个relaxed目前只用在shared_ptr里的自增操作上, 因为反正不需要其他地方可见,也不会触发任何函数,不像自减操作需要与析构函数同步所以采用了acquire-release语义。后面的五个内存序都包含了不可被当前core乱序这个保证。
-
memory_order_seq_cst 这个要求所有以此标记的原子操作在全局有唯一顺序,且原子操作前后的指令不可越过当前指令,基本相当于sequence fence。
-
memory_order_acquire 类似于一个acquire fence 这个是与memory_order_release共同使用的,线程A内的release如果与线程B内的acquire配对了,则在A的release之前的所有写操作都在B的acquire操作之前可见。只能用在load上。在cppreference里说标准库的mutex和spin_lock使用了acquire和release。
-
memory_order_release 类似于一个release fence, 与acquire配套使用,只能用在store上。
-
memory_order_acq_rel 类似于这条语句的前面加了一个acquire fence, 后面加了一个release fence。
-
memory_order_consume 这个跟acquire有点相似,但是他的副作用没有acquire强,只会对与当前修饰的变量有依赖关系的读写进行fence,避免乱序。也是与release一起配对使用的。只能用于load。
上述六个选项其实表示的是三种内存模型:
- sequential consistent(memory_order_seq_cst) 此模型下对于原子变量的操作在每个线程下看到的顺序一致,同时维持单线程内原子操作不能乱序
- relaxed(memory_order_relaxed) 此模型下只保证本线程中对于原子变量的操作不会乱序,并不涉及到多线程的同步
- acquire release(memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel)
上面这些内容最让人疑惑的莫过于memory_order_acq_rel 与memory_order_seq_cst 之间的差异,从直觉上来说这两个是差不多的,但是的确是有差异的。seq_cst保证了所有相关的原子操作在全局维持一个唯一序列,而acq_rel只能保证在同一个变量上的操作在全局维持一个唯一序列。因此对于下面这段代码,只有在采取seq_cst的时候才能获得正确的结果。
bool x= false; bool y= false; int z= 0; a() { x= true; } b() { y= true; } c() { while (!x); if (y) z++; } d() { while (!y); if (x) z++; } // kick off a, b, c, d, join all threads assert(z!=0);
下面我们来分析为什么。设a()中对x的操作为x,b()中对y的操作为y, c()中对x的操作为C_x,对y的操作为C_y,d()中对y的操作为D_y, 对x的操作为D_x。如果想让11行的assert fire,则需要在c()看到的全局序列中x<C_x<C_y<y,同时d()中看到的序列为y<D_y<D_x<x,这样我们可以构造出C_y<y<D_y且D_x<x<C_x的序列来满足这种条件。这个序列并不与acq_rel相关规定起冲突。所以对于这六个内存序,我们需要记住的是除了seq_cst之外,其他的处理都不能维持一个全局序。如果要在多个线程之间对多个单次操作做同步,最好使用seq_cst。
经过上面的分析,我们可以看出所有的原子操作都以用memory_order_relaxed和一个或两个对应的thread_fence来实现。为了安全起见还是不要手动拆分比较好,除非性能需要选择性的加入fence,具体例子见下:
const int num_mailboxes = 32; std::atomic<int> mailbox_receiver[num_mailboxes]; std::string mailbox_data[num_mailboxes]; // The writer threads update non-atomic shared data // and then update mailbox_receiver[i] as follows mailbox_data[i] = ...; std::atomic_store_explicit(&mailbox_receiver[i], receiver_id, std::memory_order_release); // Reader thread needs to check all mailbox[i], but only needs to sync with one for (int i = 0; i < num_mailboxes; ++i) { if (std::atomic_load_explicit(&mailbox_receiver[i], std::memory_order_relaxed) == my_id) { std::atomic_thread_fence(std::memory_order_acquire); // synchronize with just one writer do_work( mailbox_data[i] ); // guaranteed to observe everything done in the writer thread before // the atomic_store_explicit() } }
这里 的12行在读取mailbox_receiver的时候使用的是relaxed,在判断条件通过的时候才使用acquire_fence, 用来避免不必要的同步。