扩展的拉格朗日乘子方法
Augmented Lagrangrians and the Method of Multipliers是凸优化问题的一种通用解法. 在凸优化中,我们一般会遇到如此形式的优化问题
\begin{equation}\label{eq:oringinal}minimize \quad f(x) \quad w.r.t. \quad Ax=b\end{equation}
上式经过拉格朗日乘子变换之后,变为了
\begin{equation}\label{eq:normalLag}minimize \quad f(x)+y^{T} (Ax-b) \quad w.r.t. \quad y\ge 0\end{equation}
而所谓的扩展拉格朗日形式则是在优化问题\ref{eq:normalLag}的基础上,增加了一个二次项,即
\begin{equation}\label{eq:AugmentedLag}minimize \quad f(x)+y^{T} (Ax-b)+(\rho /2)\Vert Ax-b\Vert _{2}^{2} \quad w.r.t. \quad y\ge 0 \, \rho>0\end{equation}
在加上这个二次项之后,可以保证新的优化问题是强凸的,因此在可行集上只有一个极小值点。而且新问题仍然等价于原始的优化问题\ref{eq:oringinal},因为任何满足原始限制条件的\(x\)都会使二次项变为0,其中的\(\rho\)是惩罚参数.此时的对偶函数可以表示为\(g_{\rho}(y)=\text{inf}_x L_{\rho}(x,y)\),而原有的优化问题转变为了\(\text{max}_y g_{\rho}(y)\)。此问题的解法仍然是对偶上升法(dual ascent),即迭代的进行如下的两步操作:
\begin{equation}\label{eq:FinalLag}\begin{aligned}&x^{k+1}:=\mathop{\argmin}_{x} L_{\rho}(x,y^k)\\& y^{k+1}:=y^k+\rho (Ax^{k+1}-b)\end{aligned}\end{equation}
这里之所以采取\(\rho\)作为\ref{eq:FinalLag}中的更新步长,是出于如下考虑。在达到最优解的时候,我们可以得到如下条件:
\begin{equation}Ax^{\star}-b=0 ,\qquad \nabla f(x^{\star})+A^Ty^{\star}=0\end{equation}
根据定义,\(x^{k+1}\)可以使\(L_{\rho}(x,y^k)\)得到最小值。所以:
\begin{equation}\begin{aligned}0&=\nabla _{x}L_{\rho}(x^{k+1},y^k)\\&=\nabla _x f(x^{k+1})+A^T (y^k+\rho (Ax^{k+1}-b))\\&=\nabla _x f(x^{k+1})+A^Ty^{k+1}\end{aligned}\end{equation}
因此,在此步长下,如果达到了最优解,则\(x,y\)的值将不再变化。
在实践中,二次项的引入可能会造成一些麻烦,特别是在\(f(x)\)可以分为多个部分的时候,二次项不可分。
ADMM介绍
ADMM的全称为Alternating Direction Method of Multipliers,其主要目的就是利用优化问题的可分部分。此时的优化问题有如下形式:
\begin{equation}\label{eq:AdmmOrigin}minimize \quad f(x)+g(z) \quad w.r.t. \quad Ax+Bz=c\end{equation}
我们将此时的最优值表示为:
\begin{equation}p^{\star}=\text{inf}\{f(x)+g(z)\vert Ax+Bz=c\}\end{equation}
我们对\ref{eq:AdmmOrigin}做一个扩展的拉格朗日变化,可以得到新的目标函数:
\begin{equation}\label{eq:AdmmLag}L_{\rho}(x,z,y)=f(x)+g(z)+y^T(Ax+Bz-c)+(\rho /2)\Vert Ax+Bz-c\Vert _2^2 \end{equation}
ADMM对优化问题\ref{eq:AdmmLag}的迭代更新步骤为:
\begin{equation}\begin{aligned}&x^{k+1}:=\mathop{\argmin}_{x} L_{\rho}(x,z^k,y^k)\\&z^{k+1}:=\mathop{\argmin}_{z} L_{\rho}(x^{k+1},z,y^k)\\& y^{k+1}:=y^k+\rho (Ax^{k+1}+Bz^{k+1}-c)\end{aligned}\end{equation}
在上式中,\(x^k\)的值并没有被用到,所以我们可以把\((z^{k+1},y^{k+1})\)当作\((z^k,y^k)\)的函数。由于\(x,z\)的更新顺序不影响结果,我们可以随意的安排其更新序。
这里我们还提一下ADMM的标量形式,引入一个定义余项\(r=Ax+Bz-c\),我们可以得到:
\begin{equation}\begin{aligned}y^Tr+(\rho /2) \Vert r\Vert _2^2&=(\rho /2) \Vert r+(1/\rho )y\Vert _2^2 -(1/{2\rho}) \Vert y\Vert _2 ^2\\&=(\rho /2) \Vert r+u\Vert _2^2 -(\rho/2) \Vert u\Vert _2 ^2\\\end{aligned}\end{equation}
其中\(u=(1/\rho)y\)。引入这些定义之后,之前的ADMM更新可以更改为:
\begin{equation}\begin{aligned}&x^{k+1}:=\mathop{\argmin}_{x} f(x)+(\rho /2)\Vert Ax+Bz^k -c+u^k\Vert _2^2\\&z^{k+1}:=\mathop{\argmin}_{z} g(z)+(\rho /2)\Vert Ax^{k+1} +Bz-c +u^k \Vert _2^2\\& u^{k+1}:=u^k+x^{k+1}+Bz^{k+1}-c\end{aligned}\end{equation}
在前两步的更新中,需要处理的都是一个\(primal\)问题。随着迭代的进行,\(u\)将逐渐稳定,而余项\(r\)将逐渐变为0。
ADMM收敛性分析
这里的收敛证明需要一些前提条件,这些前提条件在当前的很多问题中都可以得到满足,这里我们就不去追究其根源。前提条件有二:
-
\(f,g\)的扩展函数\(f: R^n \rightarrow R\cup \{ + \infty\} ,g:R^m \rightarrow \{+\infty\}\)都是一个非空的闭合凸集。这个性质保证了ADMM之中的第一步和第二步更新可以进行。
-
未进行二次增广的拉格朗日乘子形式\(L_0\)拥有一个鞍点,即存在\((x^\star,z^\star,y^\star)\)使得\(L_0(x^\star,z^\star,y)\le L_0(x^\star,z^\star,y^\star)\le L_0(x,z,y^\star)\)。这个性质保证存在一个稳定的最优解。
在上述的两个前提下,当ADMM方法收敛时,下面三个命题都会得到满足:
-
余项收敛: 随着\(k\rightarrow \infty\),\(r^k \rightarrow 0\)
-
目标值收敛: 随着\(k\rightarrow \infty\),\(f(x^k)+g(z^k)\rightarrow p^\star\)
-
对偶变量收敛: 随着\(k\rightarrow \infty\),\(y^k\rightarrow y^\star\)
需要注意的是,我们当前并不要求\(x^k,z^k\)会得到收敛。
首先我们引入一个定义\(V^k\):
\begin{equation}\label{eq:Vk}V^k=(1/\rho)\Vert y^k-y^\star\Vert _2^2 +\rho\Vert B(z^k-z^\star)\Vert _2^2\end{equation}
此外,我们还需要利用三个不等式
\begin{equation}\label{eq:prove1}V^{k+1}\le V^k -\rho \Vert r^{k+1}\Vert _2^2 -\rho \Vert B(z^{k+1}-z^k)\Vert _2^2\end{equation}
\begin{equation}\label{eq:prove2}p^{k+1}-p^\star \le -(y^{k+1})^Tr^{k+1}-\rho (B(z^{k+1}-z^k))^T(-r^{k+1}+B(z^{k+1}-z^\star))\end{equation}
\begin{equation}\label{eq:prove3}p^\star -p^{k+1}\le {y^\star}^T r^{k+1}\end{equation}
我们首先对不等式\ref{eq:prove3} 进行证明。考虑到我们的前提条件二\((x^\star,z^\star,y^\star)\)是\(L_0\)的一个鞍点,所以我们有
\begin{equation}p^\star=L_0(x^\star,z^\star,y^\star)\le L_0(x^{k+1},z^{k+1},y^{\star})=f(x^{k+1})+g(z^{k+1})+{y^\star}^T(Ax^{k+1}+Bz^{k+1}-c)\end{equation}
联立\(Ax^{k} +Bz^{k}-c =r^{k}\)以及\(p^{k+1}=f(x^{k+1})+g(z^{k+1})\),我们就可以得到
\begin{equation}p^\star \le p^{k+1}+{y^\star}^T r^{k+1}\end{equation}
根据定义,\(x^{k+1}\)使\(L_{\rho}(x,z^k,y^k)\)得到最小值,因此
\begin{equation}0\in \partial L_{\rho}(x^{k+1},z^k,y^k)=\partial f(x^{k+1})+A^Ty^k+\rho A^T(Ax^{k+1}+Bz^k-c)\end{equation}
我们将\(y^k=y^{k+1}-\rho r^{k+1}\)带入上式 ,可以得到
\begin{equation}0\in \partial f(x^{k+1})+A^T(y^{k+1}-\rho B(z^{k+1}-z^k))\end{equation}
由此导数可以推出\(x^{k+1}\)使得下面的函数得到最小值:
\begin{equation}f(x)+(y^{k+1}-\rho B(z^{k+1}-z^k))^TAx\end{equation}
所以
\begin{equation}f(x^{k+1})+(y^{k+1}-\rho B(z^{k+1}-z^k))^TAx^{k+1}\le f(x^\star)+(y^{k+1}-\rho B(z^{k+1}-z^k))^TAx^\star\end{equation}
同样的分析过程应用到\(z\)上,可以得到\(z^{k+1}\)使得\(g(z)+y^{(k+1)T}Bz\)得到最小值,因此
\begin{equation}g(z^{k+1})+y^{(k+1)T}Bz^{k+1}\le g(z^\star)+y^{(k+1)T}Bz^\star\end{equation}
将我们新得到的两个不等式累加,并将\(Ax^\star +Bz^\star=c\)带入,即可得到:
\begin{equation}p^{k+1}-p^\star \le -(y^{k+1})^Tr^{k+1}-\rho (B(z^{k+1}-z^k))^T(-r^{k+1}+B(z^{k+1}-z^\star))\end{equation}
因此,不等式\ref{eq:prove3}得证。此时我们再将不等式\ref{eq:prove2}累加并乘以2,可以得到
\begin{equation}\label{eq:prove4}2(y^{k+1}-y^\star)^Tr^{k+1}-2\rho (B(z^{k+1}-z^k))^Tr^{k+1}+2\rho (B(z^{k+1}-z^{k}))^T(B(z^{k+1}-z^\star))\le 0\end{equation}
现在,将\(\rho r^{k+1}=y^{k+1}-y^k=y^{k+1}-y^\star-(y^k-y^\star)\)带入不等式\ref{eq:prove4}的第一项,得到
\begin{equation}(1/\rho)\left(\Vert y^{k+1}-y^\star\Vert _2^2 -\Vert y^k-y^\star\Vert _2^2\right) +2\rho \Vert r^{k+1}\Vert _2^2\end{equation}
同样的,将\(z^{k+1}-z^k=(z^{k+1}-z^\star)+(z^k-z^\star)\)带入到不等式\ref{eq:prove4}的最后一项可以得到
\begin{equation}\rho( \Vert B(z^{k+1}-z^\star)\Vert _2^2-\Vert B(z^{k}-z^\star)\Vert _2^2)+\rho \Vert B(z^{k+1}-z^k)\Vert _2^2\end{equation}
因此,原始的不等式\ref{eq:prove4}可以变换为
\begin{equation}\begin{aligned}&(1/\rho)\left(\Vert y^{k+1}-y^\star\Vert _2^2 -\Vert y^k-y^\star\Vert _2^2\right) +\rho \Vert r^{k+1}\Vert _2^2\\&+\rho \Vert r^{k+1}-B(z^{k+1}-z^k)\Vert _2^2 +\rho( \Vert B(z^{k+1}-z^\star)\Vert _2^2-\Vert B(z^{k}-z^\star)\Vert _2^2) \le 0\end{aligned}\end{equation}
此时我们将原来定义的\ref{eq:Vk}带入,即可得到:
\begin{equation}V^k-V^{k+1}\ge \rho \Vert r^{k+1}-B(z^{k+1}-z^k)\Vert _2^2\end{equation}
为了得到不等式\ref{eq:prove1},我们只需要证明
\begin{equation}\rho r^{(k+1)T}(B(z^{k+1}-z^k))\le 0\end{equation}
这里我们需要利用\(z^k\)使得\(g(z)+y^{kT}Bz\)取得极小值这个性质。根据定义,\(z^{k+1}\)使得\(L_{\rho}(x^{k+1},z,y^k)\)取到极小值,因此
\begin{equation}\begin{aligned}0&\in \partial g(z^{k+1})+B^Ty^k+\rho B^T(Ax^{k+1}+Bz^{k+1}-c)\\&= \partial g(z^{k+1})+B^Ty^k+\rho B^Tr^{k+1}\\&=\partial g(z^{k+1})+B^Ty^{k+1}\end{aligned}\end{equation}
所以
\begin{equation}\begin{aligned}g(z^{k+1})+y^{(k+1)T}Bz^{k+1}&\le g(z^k)+y^{(k+1)T}Bz^k\\g(z^k)+y^{kT}Bz^k&\le g(z^{k+1})+y^{kT}Bz^{k+1}\end{aligned}\end{equation}
两式相加即可得到
\begin{equation}(y^{k+1}-y^k)(B(z^{k+1}-z^k))\le 0\end{equation}
综上,不等式\ref{eq:prove1}得证。
在不等式\ref{eq:prove1}成立的情况下,由于\(V^k\)是非负的,所以
\begin{equation}\rho \sum_{k=0}^{\infty}{(\Vert r^{k+1}\Vert _2^2+\Vert B(z^{k+1}-z^k)\Vert _2^2)}\le V^0\end{equation}
由于上式是一个无穷和,有上限说明\(r^k\rightarrow 0\)和\(B(z^{k+1}-z^k)\rightarrow 0\),对于第二部分我们乘以\(\rho A^T\)可以得到\(s^{k+1}=\rho A^TB(z^{k+1}-z^k)\),这个也是会趋近于0的。在对偶余项收敛的情况下,考虑不等式\ref{eq:prove2},我们同样可以得出目标值收敛。
终止条件分析
当ADMM方法最终达到最优解时,以下三个条件会得到满足:
\begin{equation}\begin{aligned}&Ax^\star+Bz^\star-c=0\\&0\in \partial f(x^\star)+A^Ty^\star\\&0\in \partial f(z^\star)+B^Ty^\star\end{aligned}\end{equation}
由于\(z^k\)使得\(g(z)+y^{kT}Bz\)取得极小值,所以第三个等式在ADMM迭代中一定成立。只需要考虑前两个
\begin{equation}\begin{aligned}0&\in \partial f(x^{k+1})+A^Ty^k+\rho A^T(Ax^{k+1}+Bz^k-c)\\&=\partial f(x^{k+1})+A^T(y^k+\rho r^{k+1}+\rho B(z^k-z^{k+1}))\\&=\partial f(x^{k+1})+A^Ty^{k+1}+\rho A^TB(z^k-z^{k+1})\end{aligned}\end{equation}
等价的
\begin{equation}\rho A^TB(z^{k+1}-z^k)\in \partial f(x^{k+1})+A^Ty^{k+1}\end{equation}
所以对偶余项\(s^{k}\)趋近于0时,第二个条件越能够被满足。
由于ADMM在高精度求解时收敛会变得很慢,同时大规模机器学习对于精度的要求并没有很高,所以我们一般在对偶残差和初始残差在一定误差内即停止继续迭代。一般的设置为
\begin{equation}\Vert r^k\Vert _2^2\le {\epsilon}^{pri} \quad \Vert s^k\Vert _2^2\le {\epsilon}^{dual}\end{equation}
我们可以在程序执行之前设定这两个误差界的值,还有另外的一种相对型的误差
\begin{equation}\begin{aligned}{\epsilon}^{pri} &=\sqrt{p} {\epsilon}^{abs}+{\epsilon}^{rel}\text{max}\{\Vert Ax^k\Vert _2,\Vert Bz^k\Vert _2,\Vert c^k\Vert _2\}\\{\epsilon}^{dual} &=\sqrt{n}{\epsilon}^{abs} +{\epsilon}^{rel}\Vert A^Ty^k\Vert _2\end{aligned}\end{equation}
其中的\(p,n\)是输入的维度和样本的个数,byod建议将\({\epsilon}^{rel}\)取值为\(10^{-3}-10^{-4}\)。
ADMM计算方法
在证明了收敛性和给出停止条件之后,现在我们还剩下一个最重要的问题:如何去执行ADMM中的\(x,z\)更新?由于\(x,z\)更新基本是一样的,所以我们只需要考虑如何执行这一步:
\begin{equation}x^{k+1}:=\mathop{\argmin}_{x} f(x)+(\rho /2)\Vert Ax-v\Vert _2^2\end{equation}
其中\(v=-Bz^k +c-u^k\)。
在byod原始的paper中,只讨论了\(f(x)\)的三种形式:
对于二次函数形式,如果\(P+\rho A^TA\)可逆,则我们可以很简单的得到解析解。
\begin{equation}x^{k+1}=(P+\rho A^TA)^{-1}(\rho A^Tv-q)\end{equation}
在计算的时候,需要考虑一些技巧。首先就是缓存\((P+\rho A^TA)^{-1}\)的结果,同时在计算这个逆时,可以采取下面的矩阵逆公式来加速:
\begin{equation}(P+\rho A^TA)^{-1}=P^{-1}-\rho P^{-1}A^T(I+\rho A P^{-1}A^T)^{-1} AP^{-1}\end{equation}
对于没有解析解的情况,我们则需要采取凸优化里面的一些优化方法来得到极小值,这些方法主要包括\(LBFGS\)内点法等。实践中一般会把上一次的值当作这次更新的初始寻找点,然后再利用这些梯度方法来迭代更新。
而对于\(f(x)\)可分块的情况,此时则是大规模分布式计算的最适场景了。如果\(A^TA\)是分块的对角矩阵,那么约束中\(\vert Ax\Vert _2^2\)也是可分的,同时扩展的拉格朗日函数\(L_{\rho}\)也是可分的。特别的,如果\(A=I\),且\(f(x)=\lambda \Vert x\Vert _1 \, \lambda >0\)。则原始的\(x-update\)过程变为了soft thresholding问题(同时也是优化领域的proximity operator),即
\begin{equation}x_i^{k+1}=\mathop{\argmin}_{x}(\lambda \Vert x_i\Vert _1 +(\rho /2)\Vert x-v\Vert _2^2)\end{equation}
虽然该目标函数不是处处可导,但是我们可以很容易的得到他的解析解
\begin{equation}x^{+}_i = S_{\lambda/\rho}(v_i),\rightarrow S_k(a) = \left\{\begin{array}{lc}a - k &a >k \\0, & |a|\leq k\\a +k & a < -k \\\end{array}\right.\end{equation}
这里的\(S_k(a)\)也叫做压缩算子(shrinkage operator).
由于这里的每一个变量\(x_i\)都可以单独计算,所以是并行化的理想场所。
ADMM问题转化
现在回到我们最开始的ADMM问题形式:
\begin{equation}\label{eq:AdmmOrigin} minimize \quad f(x)+g(z) \quad w.r.t. \quad Ax+Bz=c \end{equation}
但是,我们一般遇到的是单变量的目标函数,并没有\(z\)的存在。所以,我们需要构造出一个\(z\)出来。下面来谈一下一些常见目标函数的ADMM形式的构建方法。
对于一般的受约束的凸优化问题,我们有如下形式
\begin{equation}minimize \quad f(x) \quad w.r.t. \quad x\in \mathcal{C}\end{equation}
其ADMM形式为
\begin{equation}\begin{array}{lc}\min & f(x) + g(z)\\w.r.t.& x - z = 0 \\\end{array}\Longrightarrow L_{\rho}(x, z, u) = f(x) + g(z) + (\rho/2)\|x - z + u\|^2_2\end{equation}
其中的\(g(x)\)便是\(\mathcal{C}\)的示性函数。同时,该问题的ADMM更新步骤为:
\begin{equation}\begin{split}x^{k+1} & = \arg\min(f(x)+(\rho/2)\|x - z^k + u^k\|^2_2)\\z^{k+1} & = \Pi_{\mathcal{C}}(x^{k+1} + u^k) \\u^{k+1} & = u^k + x^{k+1} - z^{k+1} \\\end{split}\end{equation}
这里的\(\Pi_{\mathcal{C}}\)为向量投影函数。\(x\)的更新则是一个平常的凸函数优化问题,对于可微情况,我们可以直接采用KKT条件来得到极小值。
除了这种普通的凸优化问题以外,还有一些好玩的问题也可以用ADMM来解决。例如找到两个非空包的交集中的一点。其基本算法形式为Neumann交替投影法:
\begin{equation}\begin{split}x^{k + 1} & = \Pi_{\mathcal{C}}(z^k) \\z^{k + 1} & = \Pi_{\mathcal{D}}(x^{k + 1}) \\\end{split}\end{equation}
将这个方法转变为ADMM形式为:
\begin{equation}\begin{split}x^{k + 1} & = \Pi_{\mathcal{C}}(z^k - u^k) \\z^{k + 1} & = \Pi_{\mathcal{D}}(x^{k + 1} + u^k) \\u^{k + 1} & = u^k + x^{k + 1} - z^{k + 1} \\\end{split}\end{equation}
norm-1 范数问题
之所以说ADMM适合机器学习和统计学习的优化问题,因为大部分机器学习问题基本都是“损失函数+正则项”形式,这种分法恰好可以套用到ADMM的框架\(f(x)+g(z)\)。因此结合ADMM框架基本可以解决很多已有的问题,以及利用\(\ell_1\)-norm构造的新的优化问题。下面将先介绍非分布式计算的版本,后面会单开一节来介绍如何分布式计算。
Least Absolute Deviations
先从一个简单的问题开始。在稳健估计中,LAD是一个应用很广的模型,相对于直接优化平方和损失\(\Vert Ax-b\Vert _2^2\),优化绝对损失\(\vert Ax-b\vert _1\)的抗噪性能很好。原始问题可以表示为:
\begin{equation}\begin{array}{lc}\min & \|z\|_1 \\s.t. & Ax - b = z \\\end{array}\end{equation}
在ADMM框架下,往之前的受约束的凸优化问题靠拢,这个问题有简单的迭代算法:
\begin{equation} \text{let} \,\,f(x) = 0, g(z) = \|z\|_1 \Longrightarrow \left \{\begin{split} x^{k + 1} & = (A^TA)^{-1}A^T(b + z^k - u^k) \\z^{k + 1} & = S_{1/\rho}(Ax^{k + 1} - b + u^k) \\u^{k + 1} & = u^k + Ax^{k+1} - z^{k + 1} - b \\\end{split} \right.\end{equation}
Huber Fitting
Huber问题与上面的其实差不多,只是损失函数形式不同,换成了Huber惩罚函数:
\begin{equation}\begin{array}{lc}\min & g^{hub}(z) \\s.t. & Ax - b = z \\\end{array}, \,\, g^{hub}(z) = \left\{\begin{array}{lc}z^2/2, & |z| \leq 1 \\|z| - \frac{1}{2} & |z| > 1 \\\end{array}\right.\end{equation}
因此与LAD除了\(z\)-update不在是proximity operator(或称作软阈值)之外,其余均是相同的
\begin{equation}z^{k + 1} = \frac{\rho}{1 + \rho}(Ax^{k + 1} - b + u^k) + \frac{1}{1 + \rho}S_{1 + 1/\rho}(Ax^{k+1} - b + u^k)\end{equation}
看着像是proximity operator与一个残差的加权。
LAD和Huber fitting这种问题只是一些传统损失不加正则项的ADMM化,注意一定要构造个\(z\)出来即可,\(x\)可以基本不用管,总是需要解的,下面的带有正则项的优化问题,ADMM形式就会更明显。
Basis Pursuit
基追踪法(basic pursuit)是信号处理的一种重要方法。目的是想找到一组稀疏基可以完美恢复信号,换套话说就是为一个线性方程系统找到一个稀疏解。原始形式如下,与lasso有些像:
\begin{equation}\begin{array}{lc}\min & \|x\|_1 \\s.t. & Ax = b \\\end{array}\end{equation}
修改成ADMM形式,注意往之前受约束的凸优化问题的那种形式回套,将\(\ell_1\)看做约束,然后构造带定义域的\(f(x)\),于是就有解
\begin{equation}\begin{array}{lc}\min & f(x) + \|z\|_1 \\s.t. & x - z = 0 \\\end{array}\,\,\,f(x) = I(\{x \in \mathbf{R}^n| Ax = b\})\Longrightarrow \left \{\begin{split}x^{k + 1} & = \Pi(z^k - u^k) \\z^{k + 1} & = S_{1/\rho}(Ax^{k + 1} + u^k) \\u^{k + 1} & = u^k + x^{k+1} - z^{k + 1} \\\end{split}\right.\end{equation}
其中\(\Pi(z^k −u^k )\)是向一个线性约束的欧式空间中投影\(x\in R^n ∣Ax=b\),这也是有直接的显示解的:
\begin{equation}x^{k + 1} = (I - A^T(A^TA)^{-1}A)(z - u^k) + A^T(AA^T)^{-1}b\end{equation}
最近还有一类算法来解决\(ℓ\ell_1\) 问题,被称作Bregman iteration methods,对于基追踪相关问题,加正则项的Bregman iteration就是method of multiplier,而所谓的split Bregman iteration就等同于 ADMM。
一般化损失函数加norm-1正则化
一般化损失函数加\(\ell_1\)正则化的形式如:
\begin{equation}\min \,\, l(x) + \lambda\|x\|_1,\end{equation}
这类问题在高维统计开始时便是一个非常重要的问题,而即使到了现在也是一个非常重要的问题,比如group lasso,generalized lasso,高斯图模型,Tensor型图模型,与图相关的\(ℓ\ell_1\) 问题等算法的开发,都可以在此框架上直接应用和实施,这正是ADMM一个优势所在,便于快速实施,也便于可能的大规模分布式部署。
\begin{equation}\begin{array}{lc}\min & l(x) + \lambda \|z\|_1 \\s.t. & x - z = 0 \\\end{array}\Longrightarrow\left \{\begin{split}x^{k + 1} & = \arg\min_x (l(x) + (\rho/2)\|x - z^k + u^k\|_2^2) \\z^{k + 1} & = S_{1/\rho}(x^{k + 1} + u^k) \\u^{k + 1} & = u^k + x^{k+1} - z^{k + 1} \\\end{split}\right.\end{equation}
特别的,对于lasso问题\(f(x) = \frac{1}{2}|Ax - b|^2_2\),我们可以得到第一步的解析解:
\begin{equation}x^{k + 1} = (A^TA + \rho I)^{-1}(A^Tb + \rho(z^k - u^k))\end{equation}
全局一致问题
下面两节讲述的两个优化问题,是非常常见的优化问题,也非常重要,是ADMM算法通往并行和分布式计算的一个途径:consensus和sharing,即一致性优化问题与共享优化问题。
Global variable consensus optimization
所谓全局变量一致性优化问题,即目标函数根据数据分解成\(N\)子目标函数(子系统),每个子系统和子数据都可以获得一个参数解\(x^i\) ,但是全局解只有一个\(z\),于是就可以写成如下优化命题:
\begin{equation}\begin{array}{lc}\min & \sum^N_{i = 1}f_i(x_i), x_i \in \mathbf{R}^n\\s.t. & x_i - z = 0 \\\end{array}\end{equation}
注意,此时\(f_i: \mathbf{R}^n \rightarrow \mathbf{R} \bigcup {+\infty}\)仍是凸函数,而\(x_i\) 并不是对参数空间进行划分,这里是对数据而言,所以\(x_i\) 维度一样$x_i ,z\in R^n $,与之前的问题并不太一样。这种问题其实就是所谓的并行化处理,或分布式处理,希望从多个分块的数据集中获取相同的全局参数解。
在ADMM算法框架下(先返回最初从扩增lagrangian导出的ADMM),这种问题解法相当明确.其问题形式可以表示为:
\begin{equation}\begin{array}{c}L_{\rho}(x_1, \ldots, x_N, z, y) = \sum^N_{i=1}(f_i(x_i) + y^T_i(x_i - z) + (\rho/2)\|x_i - z\|^2_2) \\s.t. \mathcal{C} = \{(x_1, \ldots, x_N)|x_1 = \ldots = x_N\} \\\end{array} \end{equation}
其ADMM更新方法见下:
\begin{equation}\begin{split}x_i^{k+1} & = \arg\min_x (f_i(x_i) + (y^k_i)^T(x_i - z^k) + (\rho/2)\|x_i - z\|^2_2)) \\z^{k+1} & = \frac{1}{N}\sum^N_{i=1}(x_i^{k+1} + (\frac{1}{\rho}y^k_i)) \\y_i^{k+1} & = y_i^k + \rho(x_i^{k+1} - z^{k+1}) \\\end{split}\end{equation}
对\(y\)-update和\(z\)-update的\(y^{k+1}_ i\) 和\(z^{k+1}_ i\) 分别求个平均,易得\(\bar{y}^{k+1} =0\),于是可以知道\(z\)-update步其实可以简化为\(z^{ k+1} =\bar{x}^{k+1}\) ,于是上述ADMM其实可以进一步化简为如下形式:
\begin{equation}\begin{split}x_i^{k+1} & = \arg\min_x (f_i(x_i) + (y^k_i)^T(x_i - \bar{x}^k) + (\rho/2)\|x_i - \bar{x}^k\|^2_2)) \\y_i^{k+1} & = y_i^k + \rho(x_i^{k+1} - \bar{x}^{k+1}) \\\end{split}\end{equation}
这种迭代算法写出来了,并行化那么就是轻而易举了,各个子数据分别并行求最小化,然后将各个子数据的解汇集起来求均值,整体更新对偶变量\(y^k\) ,然后再继续回带求最小值至收敛。当然也可以分布式部署(hadoop化),但是说起来容易,真正工程实施起来又是另外一回事,各个子节点机器间的通信更新是一个需要细细揣摩的问题。
另外,对于全局一致性优化,也需要给出相应的终止迭代准则,与一般的ADMM类似,看primal和dual的residuals即可
\begin{equation}\|r^k\|_2^2 = \sum^N_{i = 1}\|x^k_i - \bar{x}^k\|_2^2, \quad \|s^k\|_2^2 = N\rho\|\bar{x}^k_i - \bar{x}^{k-1}\|_2^2\end{equation}
带正则项的全局一致性问题
下面就是要将之前所谈到的经典的机器学习算法并行化起来。想法很简单,就是对全局变量加上正则项即可,
\begin{equation}\begin{array}{lc}\min & \sum^N_{i = 1}f_i(x_i) + g(z), x_i \in \mathbf{R}^n\\s.t. & x_i - z = 0 \\\end{array}\end{equation}
因此ADMM算法只需要改变下\(z\)-update步即可
\begin{equation}\begin{split}x_i^{k+1} & = \arg\min_{x+i} (f_i(x_i) + (y^k_i)^T(x_i - z^k) (\rho/2)\|x_i - z\|^2_2)) \\z^{k+1} & = \arg\min_z (g(z) + \sum^N_{i=1}(-(y^k_i)^Tz + (\rho/2)\|x^{k+1}_i - z\|_2^2)) \\y_i^{k+1} & = y_i^k + \rho(x_i^{k+1} - z^{k+1})\\\end{split}\end{equation}
同样的,我们仍对\(z\)做一个平均处理,于是就有
\begin{equation}z^{k+1} = \arg\min_z(g(z) + (N\rho/2)\|z - \bar{x}^{k+1} - (1/\rho)\bar{y}^k\|^2_2)\end{equation}
上述形式都取得是最原始的ADMM形式,简化处理,写成scaled形式即有
\begin{equation}\begin{split}x_i^{k+1} & = \arg\min_x (f_i(x_i) + (\rho/2)\|x_i - z^k + u_i^k\|^2_2)) \\z^{k+1} & = \arg\min_z (g(z) + (N\rho/2)\|z - x^{k+1}_i - \bar{u}^k\|^2_2) \\u_i^{k+1} & = u_i^k + x_i^{k+1} - z^{k+1} \\\end{split}\end{equation}
这样对于后续处理问题就清晰明了多了。可以看到如果\(g(z)=\lambda \|z\|_1\) ,即lasso问题,那么\(z\)-update步就用软阈值operator即可。因此,对于大规模数据,要想用lasso等算法,只需要对数据做切块(切块也最好切均匀点),纳入到全局变量一致性的ADMM框架中,即可并行化处理。下面给出一些实例。
数据切割
在经典的统计估计中,我们处理的多半是大样本低维度的数据,现在则多是是大样本高维度的数据。对于经典的大样本低维度数据,如果机器不够好,那么就抽样部分数据亦可以实现较好估计。不过如果没有很好的信息,就是想要对大样本进行处理,那么切割数据,并行计算是一个好的选择。现在的社交网络、网络日志、无线感应网络等都可以这么实施。下面的具体模型都在受约束的凸优化问题中以及\(\ell_1\)-norm问题中提过,此处只不过切割数据,做成分布式模型,思想很简单,与带正则项的global consensus问题一样的处理。经典问题lasso、sparse logistic lasso、SVM都可以纳入如下框架处理。
有观测阵\(A\in R^{m×n}\) 和响应值\(b\in R^m\) ,可以对应切分,即对矩阵\(A\)和向量\(b\)横着切,
\begin{equation}A = \begin{pmatrix}A_1\\\vdots\\A_N \\\end{pmatrix}\quad b = \begin{pmatrix}b_1 \\\vdots\\b_N \\\end{pmatrix}\end{equation}
于是原来带正则项的优化问题就可以按照数据分解到多个子系统上去分别优化,然后汇集起来,形成一个global consensus问题。
\begin{equation}\begin{array}{lr}\min & \sum^N_{i=1}l_i(A_ix_i - b_i) + r(z) \\s.t. & x_i - z = 0, i = 1, \ldots, N \quad x_i, z \in \mathbf{R}^n \\\end{array}\end{equation}
结合受约束的凸优化问题时所给出来的具体的ADMM算法解的形式,下面直接给出这些问题的ADMM迭代算法公式。
对于lasso,其更新公式为
\begin{equation}\begin{split}x_i^{k + 1} & = (A_i^TA_i + \rho I)^{-1}(A_i^Tb_i + \rho (z^k - u_i^k)) \\z^{k + 1} & = S_{1/\rho N}(\bar{x}^{k + 1} - b + \bar{u}^k) \\u_i^{k + 1} & = u_i^k + x_i^{k+1} - z^{k + 1} \\\end{split}\end{equation}
如果切割的数据量小于维数\(m_i <n\),那么求解时分解小的矩阵\(A_i A^T_i +\rho I\)即可;其他求逆采用矩阵加速技巧即可。
对于Sparse Logistic Regression,其更新公式如下:
\begin{equation}\begin{split}x_i^{k + 1} & = \arg\min_{x_i}(l_i(A_ix_i - b_i) + (\rho/2)\|x_i - z^k + u_i^k\|^2_2\\z^{k + 1} & = S_{1/\rho N}(\bar{x}^{k + 1} - \bar{b} + \bar{u}^k) \\u_i^{k + 1} & = u_i^k + x_i^{k+1} - z^{k + 1} \\\end{split}\end{equation}
在\(x\)-update步是需要用一些有效的算法来解决\(\ell_2\) 正则的logistic回归,比如L-BFGS,其他的优化算法应该问题不大吧。
对于SVM,注意分类问题和回归问题的损失函数不同,一般都是用\(l(sign(t)y)\)形式来寻求最优的分类权重使得分类正确。SVM使用Hinge Loss:\(\ell(y)=max(0,1−t.y)\),即将预测类别与实际分类符号相反的损失给凸显出来。分布式的ADMM形式为
\begin{equation}\begin{split}x_i^{k + 1} & = \arg\min_{x_i}(\mathbf{1}^T(A_ix_i + 1)_{+} + (\rho/2)\|x_i - z^k + u_i^k\|^2_2\\z^{k + 1} & = \frac{\rho}{(1/\lambda) + N\rho}(\bar{x}^{k+1} + \bar{u}^k) \\u_i^{k + 1} & = u_i^k + x_i^{k+1} - z^{k + 1} \\\end{split}\end{equation}
一般形式的一致性优化问题
所谓的一般形式的一致性问题,就是切割参数到各子系统,但各子系统目标函数参数维度不同,可能部分重合。上述全局一致性优化问题中,我们可以看到,所做的处理不过是对数据分块,然后并行化处理。但是更一般的优化问题是,参数空间也是分块的,即每个子目标函数\(f_i (x_i )\)的参数维度不同\(x_i ,\in R n_i\) ,我们称之为局部变量。而局部变量所对应的的也将不再是全局变量\(z\),而是全局变量中的一部分\(z_g\) ,并且不是像之前的顺序对应,而可能是随便对应到\(z\)的某个位置.可令\(g=\mathcal{G}(i,.)\),即将\(x_i\) 映射到\(z\)的某部位
\begin{equation}(x_i)_j = z_{\mathcal{G}(i, j)} = \hat{z}_i \end{equation}
如果对所有\(i\)有\(\mathcal{G}(i,j)=j\),那么\(x_i\) 与\(z\)就是顺序映射,也就是全局一致性优化问题,否则就不是。结合下图就比较好理解
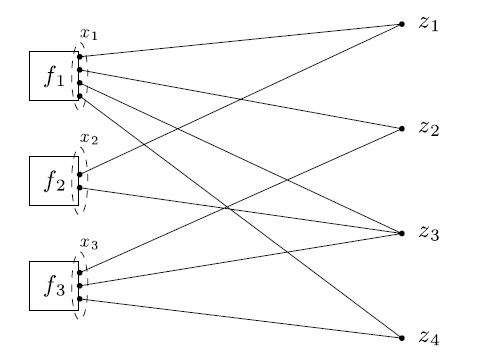
虽然如果用其他方法来做感觉会复杂,但是纳入到上述ADMM框架,其实只不过是全局一致性优化问题的一个局部化变形,不过此时不是对数据进行分块,是对参数空间进行分块.新的优化问题可以表示为
\begin{equation}\begin{array}{lc}\min & \sum^N_{i = 1}f_i(x_i) + g(z), x_i \in \mathbf{R}^{n_i}\\s.t. & x_i - \hat{z}_i = 0, i = 1, \ldots N \\\end{array}\end{equation}
而新的更新策略则为
\begin{equation}\begin{split}x_i^{k+1} & = \arg\min_x (f_i(x_i) + (y^k_i)^Tx_i (\rho/2)\|x_i - \hat{z}_i^k\|^2_2)) \\z^{k+1} & = \arg\min_z (\sum^N_{i=1}(-(y^k_i)^T\hat{z}_i + (\rho/2)\|x^{k+1}_i - \hat{z}_i\|_2^2))) \\y_i^{k+1} & = y_i^k + \rho(x_i^{k+1} - \hat{z}_i^{k+1}) \\\end{split}\end{equation}
共享问题
与之前的全局变量一致性优化问题类似,共享问题也是一个非常一般而且常见的问题。他的形式如下:
\begin{equation}\min \,\, \sum^N_{i=1}f_i(x_i) + g(\sum^N_{i=1}x_i)\end{equation}
这里的第一部分局部损失\(f_i (x_i )\)与全局一致性优化是一样的,即所有的\(x_i \in R^n ,i=1,\cdots,N\)同维度,而对于一个共享的目标函数\(g\)则是新加入的。在实际中,我们常常需要优化每个子数据集上的损失函数,同时还要加上全局数据所带来的损失;或者需要优化每个子系统的部分变量,同时还要优化整个变量。共享问题是一个非常重要而灵活的问题,它也可以纳入到ADMM框架中,形式如下:
\begin{equation}\begin{array}{lc}\min & \sum^N_{i=1}f_i(x_i) + g(\sum^N_{i=1}z_i) \\s.t. & x_i - z_i = 0, z_i \in \mathbf{R}^n, i = 1, \ldots, N, \\\end{array}\end{equation}
其更新形式如下:
\begin{equation}\begin{split}x_i^{k+1} & = \arg\min_{x_i} (f_i(x_i) + (\rho/2)\|x_i - z_i^k + u_i^k\|^2_2)) \\z^{k+1} & = \arg\min_z (g(\sum^N_{i = 1}z_i) + \rho/2\sum^N_{i = 1}\|z_i - x^{k+1}_i - u^k_i\|^2_2) \\u_i^{k+1} & = u_i^k + x_i^{k+1} - z_i^{k+1} \\\end{split}\end{equation}
上述形式当然还不够简洁,需要进一步化简。因为\(x\)-update可以不用担心,分机并行处理优化求解即可,而对于\(z\)-update这里面需要对\(N\)个变量求解,想加快速度,就减少变量个数。于是想办法通过和之前那种平均方式一样来简化形式解.
对于\(z\)-update步,令\(a_i =u^k_i +x^{k+1}_i\) ,于是\(z\)-update步优化问题转化为
\begin{equation}\begin{array}{lc}\min & g(N\bar{z}) + (\rho/2)\sum^N_{i=1}\|z_i - a_i\|^2_2 \\s.t. & \bar{z} = \frac{1}{N}\sum^N_{i=1}z_i \\\end{array}\end{equation}
当\(\bar{z}\) 固定时,那么后面的最优解(类似回归)为\(z_i =a_i +\bar{z} −\bar{a }\),带入上式后于是后续优化就开始整体更新(均值化)
\begin{equation}\begin{split}x_i^{k+1} & = \arg\min_{x_i} (f_i(x_i) + (\rho/2)\|x_i - x_i^k + \bar{x}^k - \bar{z}^k + u^k\|^2_2)) \\z^{k+1} & = \arg\min_z (g(N\bar{z}) + N\rho/2\|\bar{z} - \bar{x}^{k+1} - u^k\|^2_2) \\u^{k+1} & = u_i^k + \bar{x}^{k+1} - \bar{z}^{k+1} \\\end{split}\end{equation}
另外,有证明如果强对偶性存在,那么global consensus问题与sharing问题是可以相互转化的,可以同时达到最优,两者存在着很紧密的对偶关系。
本节开头提过,sharing问题用来切分数据做并行化,也可以切分参数空间做并行化。这对于高维、超高维问题是非常有好处的。因为高维统计中,大样本是一方面问题,而高维度才是重中之重,如果能切分特征到低纬度中去求解,然后在合并起来,那么这将是一个很美妙的事情。上面利用regularized global consensus问题解决了切分大样本数据的并行化问题,下面利用sharing思想解决常见的高维数据并行化问题
同样假设面对还是一个观测阵\(A\in R^{m×n}\)和响应观测\(b\in R^n\) ,此时有\(n\gg m\),那么要么就降维处理,要么就切分维度去处理,或者对于超高维矩阵,切分维度后再降维。此时\(A\)矩阵就不是像之前横着切分,而是竖着切分,这样对应着参数空间的切分:
\begin{equation}A = [A_1, \ldots, A_N], A_i \in \mathbf{R}^{m \times n_i}, x = (x_1, \ldots, x_N), x\in \mathbf{R}^{n_i}, \rightarrow Ax = \sum^N_{i = 1}A_ix_i\end{equation}
于是正则项也可以切分为\(r(x) = \sum^N_{i = 1}r_i(x_i)\),那么从最初的\(\min \,\, l(Ax - b) + r(x)\)形式变成了:
\begin{equation}\min \,\, l(\sum^N_{i = 1}A_ix_i - b) + \sum^N_{i = 1}r_i(x_i)\end{equation}
个与sharing问题非常接近了,做点变化那就是sharing问题了
\begin{equation}\begin{array}{lc}\min & l(\sum^N_{i=1}z_i - b) + \sum^N_{i=1}r_i(x_i) \\s.t. & A_ix_i - z_i = 0, i = 1,\ldots, N \\\end{array}\end{equation}
其对应的更新形式如下:
\begin{equation}\begin{split}x_i^{k+1} & = \arg\min_{x_i} (r_i(x_i) + (\rho/2)\|A_ix_i - A_ix_i^k + \overline{Ax}^k - \bar{z}^k + u^k\|^2_2)) \\z^{k+1} & = \arg\min_z (l(N\bar{z} - b) + N\rho/2\|\bar{z} - \overline{Ax}^{k+1} - u^k\|^2_2) \\u^{k+1} & = u_i^k + \overline{Ax}^{k+1} - \bar{z}^{k+1} \\\end{split}\end{equation}
与之前的global consensus问题相比,ADMM框架\(x\)-update与\(z\)-update似乎是反过来了。于是将此形式直接套到Lasso等高维问题即有很具体的形式解了
\begin{equation}\begin{split}x_i^{k+1} & = \arg\min_{x_i} (\lambda\|x_i\|_1+ (\rho/2)\|A_ix_i - A_ix_i^k + \overline{Ax}^k - \bar{z}^k + u^k\|^2_2)) \\\bar{z}^{k+1} & = \frac{1}{N + \rho}(b + \rho \overline{Ax}^{k+1} + \rho u^k) \\u^{k+1} & = u^k + \overline{Ax}^{k+1} - \bar{z}^{k+1} \\\end{split}\end{equation}
当\(|A^T_i(A_ix^k_i + \bar{z}^k - \overline{Ax}^k - u^k)|_2 \leq \lambda/\rho\)时\(x^{k+1}_i = 0\),所以这样加快了x -update速度,不过这个对串行更有效,对并行起来也没有多大用..
Sparse Logstic Regression 也与lasso区别不大,只是\(z\)-update的损失函数不同,其余相同于是
\begin{equation}\bar{z}^{k+1} = \arg\min_{\bar{z}} (l(N\bar{z})+ (\rho/2)\|\bar{z} - \overline{Ax}^{k+1} - u^k\|^2_2)\end{equation}
SVM与之前的global consensus时候优化顺序反了过来,与logistic rgression只是在\(z\)-update步不同(损失函数不同):
\begin{equation}\begin{split}x_i^{k+1} & = \arg\min_{x_i} (\lambda\|x_i\|_2^2+ (\rho/2)\|A_ix_i - A_ix_i^k + \overline{Ax}^k - \bar{z}^k + u^k\|^2_2)) \\\bar{z}^{k+1} & = \arg\min_{\bar{z}}(\mathbf{1}^T(N\bar{z}+\mathbf{1})_{+} + (\rho/2)\|\bar{z} - \overline{Ax}^{k+1} - u^{k+1}\|) \\u^{k+1} & = u^k + \overline{Ax}^{k+1} - \bar{z}^{k+1} \\\end{split}\end{equation}
\(z\)-update解析解可以写成软阈值算子
\begin{equation}(\bar{z}^{k+1})_i = \left\{\begin{array}{ll}v_i - N/\rho, & v_i > -1/N + N/\rho \\-1/N, & v_i \in [-1/N, -1/N + N/\rho] \\v_i, & v_i < -1/N \\\end{array}\right.v_i = (\overline{Ax}^{k+1} + \bar{u}^k)_i\end{equation}
参考链接